
CEMTM: Contextual Embedding-based Multimodal Topic Modeling
Amirhossein Abaskohi, Raymond Li, Chuyuan Li, Shafiq Joty, Giuseppe Carenini
Abstract
- CEMTM: 텍스트와 이미지를 모두 포함하는 짧고 긴 문서에서 일관성 있고(coherent) 해석 가능한(interpretable) 토픽 구조를 추론하도록 설계된 "context-enhanced multimodal topic model"입니다.
- 모델의 주요 구성 요소 및 작동 방식
- Fine-tuned LVLMs 활용: Fine-tuned Large Vision Language Models (LVLMs)를 기반으로 문맥화된 임베딩(contextualized embeddings) 을 얻습니다. 이는 텍스트와 이미지 정보를 통합한 표현입니다.
- 분포 기반 어텐션 메커니즘: 분포 기반 어텐션 메커니즘(distributional attention mechanism) 을 사용하여 토큰(텍스트 토큰 및 이미지 패치)이 토픽 추론에 기여하는 정도에 가중치를 부여합니다.
- 재구성 목표(Reconstruction Objective): 재구성 목표를 통해 토픽 기반 표현을 전체 문서 임베딩과 정렬합니다. 이는 텍스트와 이미지 모달리티 전반에 걸쳐 의미론적 일관성(semantic consistency) 을 보장하는 역할을 합니다.
- 기존 접근 방식과의 차별점 및 장점
- 효율적인 이미지 처리: 기존 방식과 달리, 문서당 여러 이미지를 반복적인 인코딩 없이(without repeated encoding) 처리할 수 있어 효율적입니다.
- 해석 가능성 유지: 명시적인 단어-토픽(word-topic) 및 문서-토픽(document-topic) 분포를 제공하여 모델의 해석 가능성을 유지합니다.
- 실험 결과 및 성능
- 6가지 멀티모달 벤치마크에서 광범위한 실험을 진행한 결과, CEMTM은 기존의 단일 모달(unimodal) 및 멀티모달(multimodal) 베이스라인보다 일관되게 뛰어난 성능을 보여주었습니다.
- 평균 LLM score 2.61 (1-3 스케일) 이라는 인상적인 점수를 달성했습니다.
- 추가 분석을 통해 다운스트림 few-shot 검색(retrieval) 작업에서도 그 효과가 입증되었으며, 과학 논문과 같은 복잡한 도메인에서 시각적으로 연관된 의미(visually grounded semantics) 를 포착하는 능력을 보여주었습니다.
1 Introduction
- 멀티모달 콘텐츠의 등장과 한계
- 이미지, 캡션, 정형 텍스트가 함께 존재하는 멀티모달 콘텐츠의 급증으로, 여러 모달리티를 동시에 이해하고 추론할 수 있는 모델의 필요성이 커졌습니다.
- [1,2] 과 같은 전통적인 멀티모달 토픽 모델은 LDA를 확장하여 이미지 특징을 텍스트와 함께 통합하려 했으나, 깊이 있는 교차 모달 상호작용을 포착하는 데 종종 실패했습니다.
- Multi-modal NTM 의 발전: 최근 [3] 등 신경 토픽 모델링의 발전은 모달리티 전반에 걸쳐 공유 임베딩(shared embeddings)을 학습함으로써 이러한 한계를 해결했습니다. 이를 통해 더 일관성 있고 의미론적으로 통합된 토픽 발견이 가능해졌습니다.
- LLMs 및 LVLMs의 영향
- LLMs 과 Large Vision-Language Model (LVLMs)은 방대하고 다양한 코퍼스로부터 풍부한 의미론적 지식을 encoding 하는 탁월한 능력을 보여주었습니다.
- Prompt 기반 토픽 모델링: LLM은 제로샷(zero-shot) 및 퓨샷(few-shot) 프롬프팅을 통해 토픽을 생성하고 할당하는 데 사용되어 토픽 일관성과 해석 가능성을 크게 향상시켰습니다 [5,6]
- 멀티모달에서 Prompt 기반 토픽모델링
- [6] 과 같은 Prompt 기반 방법이 사용되었습니다.
- 장점: TopicGPT와 같은 모델은 자연어 기반의 해석 가능한 결과물을 생성합니다.
- 한계: 코퍼스 수준의 토픽 분포가 부족하고, 프롬프트 변화에 대한 견고성이 떨어집니다. 또한 불확실성을 모델링하거나 일관된 전역적(global) 토픽 구조를 제공하지 못하여 탐색적 분석(exploratory analysis)에 유용성이 제한됩니다 [7].
- 필요한 연구 방향: LVLMs의 knowledge grounding 및 modality alignment 능력과 멀티모달 신경 토픽 모델의 구조화된 모델링을 결합하는 것입니다. 이는 토픽 표현의 일관성과 안정성을 유지하면서 의미론적 이해를 향상시키기 위해 LVLMs 를 활용하는 방향입니다.
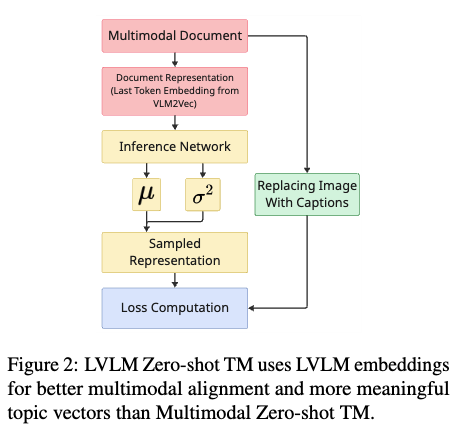
- CEMTM Framework
- LVLM의 잠재 표현 활용: CEMTM은 복잡한 아키텍처를 통해 여러 모달리티(양식)를 정렬하는 대신, 사전 훈련된 대규모 비전 언어 모델(LVLM)에서 생성된 잠재 표현(latent representations)을 직접 활용합니다.
- 통합된 문서 표현: [9] 에서처럼, LVLM의 최종 토큰 임베딩을 다중 모달 문서(텍스트 및 시각적 콘텐츠 포함)의 압축되고 통합된 표현으로 사용합니다.
- 간소화된 다중 이미지 처리: 이 접근 방식은 모달리티별 인코더를 개별적으로 사용할 필요가 없으므로, 문서 내 여러 이미지를 반복적인 인코딩 없이 단일하게 처리할 수 있습니다. 이는 확장 가능하고 일관성 있는 다중 모달 토픽 모델링에 적합합니다.
- 학습 가능한 중요도 네트워크: 저자들은 [8]에서 영감을 받아, 각 텍스트 토큰과 이미지 패치가 문서-토픽 표현에 기여하는 정도를 추정하는 학습 가능한 중요도 네트워크(importance network)를 통합합니다.
- SOTA performance: CEMTM은 6개의 다중 모달 벤치마크 데이터셋에서 광범위한 실험을 통해 강력한 성능을 입증했으며, 평균 LLM 점수 2.61점(3점 만점)을 달성하여 기존 베이스라인 모델들을 능가했습니다.
- Contributions
- CEMTM은 텍스트와 이미지를 모두 포함하는 문서에서 일관성 있고 해석 가능한 토픽 구조를 추론하도록 설계된 모델입니다.
특히, 사전 학습된 대규모 비전-언어 모델(LVLM)에서 얻은 표현(embeddings)을 활용하여 멀티모달 데이터를 처리합니다.
이를 통해 짧거나 긴 다양한 길이의 문서에서도 의미론적으로 연결되고 다양한 토픽을 생성할 수 있습니다. - CEMTM은 각 토큰(텍스트 토큰 및 이미지 패치)이 문서-토픽 표현에 기여하는 정도를 학습하는 확률적(stochastic) 분포 기반 메커니즘을 도입합니다. 이러한 접근 방식은 토큰-레벨 기여도를 명시적으로 모델링하여 의미론적 정렬(semantic alignment)을 개선하고, 토픽 추론 과정의 해석 가능성(interpretability)을 높입니다. 특히, LVLM의 미세 조정된 임베딩과 결합될 때 더욱 효과적입니다.
- CEMTM은 기존의 강력한 단일 모달 및 멀티모달 베이스라인 모델들을 뛰어넘는 뛰어난 성능을 보여주며 새로운 SOTA(State-Of-The-Art)를 달성했습니다. 이는 토픽 품질 측정 지표(예: LLM 점수 2.61)에서 확인되었으며, downstream task 인 few-shot QA task 에서도 그 효과가 입증되었습니다. 이러한 결과는 CEMTM이 학습한 토픽 분포가 검색 기반 retrieval-based task, 특히 관련 문서나 예시를 효과적으로 찾는 데 매우 유용하다는 것을 시사합니다.
- CEMTM은 텍스트와 이미지를 모두 포함하는 문서에서 일관성 있고 해석 가능한 토픽 구조를 추론하도록 설계된 모델입니다.
2 Related Work
Neural Multimodal Topic Modeling.
- 초기 멀티모달 토픽 모델 (Early Multimodal Topic Models)
- 기반: 주로 Latent Dirichlet Allocation(LDA) 모델을 확장하여 이미지와 텍스트를 함께 처리하려고 했습니다. 예를 들어, Modeling annotated data(Blei and Jordan, 2003) 연구가 있습니다.
- 한계: 이러한 초기 모델들은 종종 각 모달리티(이미지, 텍스트)를 독립적으로 취급하는 경향이 있어, 깊이 있는 교차 모달 상호작용(cross-modal interactions)을 효과적으로 포착하지 못했습니다.
- 신경망 기반 접근법 (Neural Approaches): 초기 모델의 한계를 극복하고, 여러 모달리티 간에 공유되는 표현(shared representations)을 학습하는 데 중점을 두었습니다.
- [10] 은 autoregressive approach를 사용하여 모달리티 간의 관계를 모델링했습니다.
- [11] 는 짧은 문서에 대해 단어 관계와 객체 관계를 통합하는 그래프 기반 모델을 제시했습니다.
- 평가 연구: Neural multimodal topic modeling: A comprehensive evaluation(Gonzalez-Pizarro and Carenini, 2024a/b)는 신경 멀티모달 토픽 모델에 대한 대규모 비교 연구를 수행하여, 토픽의 일관성(coherence)과 다양성(diversity) 측면에서 여전히 개선의 여지가 있음을 보여주었습니다.
- CEMTM의 차별점
- 핵심: CEMTM은 위에서 언급된 기존 모델들과 다르게, 사전 학습된 LVLM(Large Vision Language Models)을 활용합니다.
- LVLM 활용: LVLM으로부터 얻은 "최종 토큰 임베딩(final token embeddings)"을 사용하여 텍스트와 이미지 간의 잘 정렬된(aligned) 교차-모달 의미(cross-modal semantics)를 포착합니다.
- 효율성: 이러한 접근 방식 덕분에 CEMTM은 토픽 표현을 학습하는 과정에서 모달리티 정렬(modality alignment)을 별도로 학습할 필요가 없습니다. 이는 LVLM이 이미 텍스트와 이미지의 의미를 효과적으로 통합하여 표현하기 때문에, 추가적인 정렬 단계 없이도 높은 수준의 교차-모달 이해를 달성할 수 있음을 의미합니다.
Language Models for Topic Modeling.
- 언어 모델의 토픽 모델링 발전
- LLM(Large Language Models)은 Decoder model 기반의 프롬프트(prompting)와 Encoder model 기반의 문맥화된 임베딩(contextual embeddings)을 활용하여 토픽 모델링에 큰 발전을 가져왔습니다.
- TopicGPT [5] 와 같은 프롬프트 기반 방식은 LLM을 사용하여 해석 가능하며 자연어 형태의 토픽을 생성합니다.
- CWTM [8] 은 문맥화된 BERT 임베딩을 신경망 토픽 모델에 통합하여 토픽의 일관성(coherence)을 향상시켰습니다.
- 멀티모달 환경에서의 언어 모델 활용
- 멀티모달 설정에서는 PromptMTopic [6] 과 같은 방법이 LLM을 통해 텍스트 및 시각적 단서를 결합하여 밈(memes)과 같은 데이터에서 문화적으로 특화된(culturally aware) 토픽을 추출합니다.
- LVLMs 는 이미지-텍스트 쌍에 대해 통합된(unified) 표현을 제공하지만, 이러한 LVLMs의 멀티모달 토픽 모델링 적용은 아직 충분히 탐구되지 않았습니다.
- CEMTM의 접근 방식
- CEMTM은 이러한 한계를 해결하기 위해 LVLMs를 직접 활용합니다.
- LVLM의 최종 토큰 임베딩 (final token embedding) 을 문서의 텍스트 및 시각적 콘텐츠를 모두 포함하는 압축되고 정렬된 멀티모달 표현으로 사용합니다.
- 이 접근 방식은 별도의 양식별 인코더나 프롬프트 없이도 LVLM의 사전 학습된 지식을 활용하여 효율적이고 해석 가능한 토픽을 발견할 수 있게 합니다.
3 Method
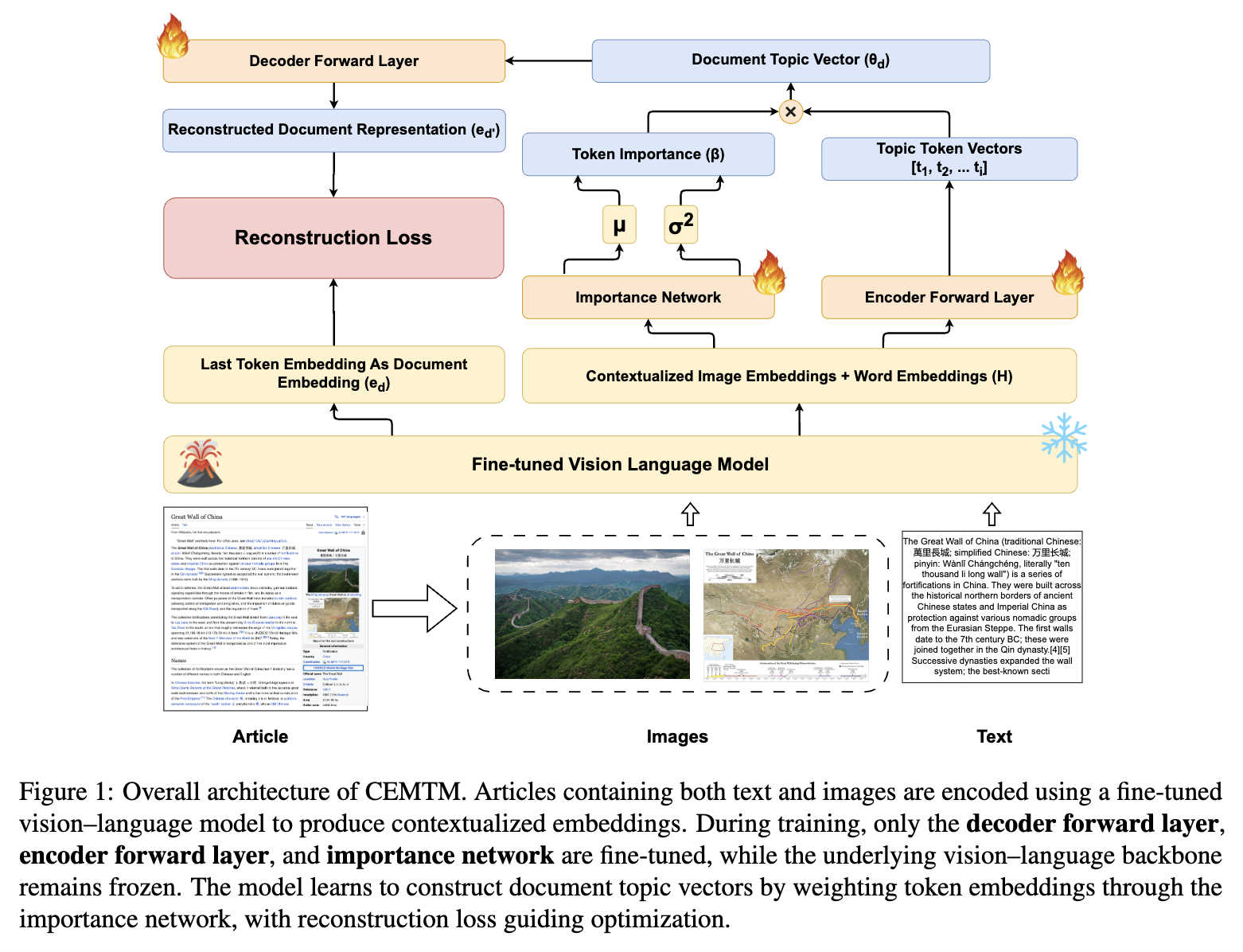
- Overall Process of CEMTM (Three Parts)
- Data Preprocessing
- Model Training
- Topic Extraction
3.1 Preprocessing
- 텍스트 정제 (Text Cleaning)
- 문서의 텍스트 콘텐츠에 표준 자연어 처리(NLP) 전처리 기법을 적용합니다.
- 구두점(punctuation)을 제거하고, 모든 문자의 대소문자(casing)를 통일하며, HTML 태그와 같이 내용과 관련 없는 토큰(irrelevant tokens)들을 제거합니다.
- 이는 텍스트 데이터를 일관된 형태로 만들고 불필요한 노이즈를 줄여 모델이 핵심적인 의미를 학습하는 데 집중할 수 있도록 돕습니다.
- 어휘 구성 (Vocabulary Construction)
- 정제된 모든 문서에서 토큰화(tokenizing)를 수행하여 단어들을 추출합니다.
이후, 가장 자주 등장하는 단어들을 포함하고 불용어(stop-words) 및 희귀 단어(rare terms)는 제외하여 고정된 어휘 집합 V 를 구축합니다. - 불용어(예: "the", "a", "is")는 의미론적 가치가 낮아 토픽 추출에 방해가 될 수 있으며, 희귀 단어는 통계적으로 유의미한 패턴을 형성하기 어렵기 때문에 제거됩니다.
- 정제된 모든 문서에서 토큰화(tokenizing)를 수행하여 단어들을 추출합니다.
- 이미지 처리 (Image Processing)
- 문서에 포함된 모든 이미지는 비전-언어 모델(vision-language model, Llava)의 입력 요구 사항에 맞게 크기가 조정(resized)되고 형식(formatted)이 지정됩니다.
- 이는 모델이 이미지를 올바르게 처리하고 텍스트와 함께 일관된 임베딩(embedding)을 생성할 수 있도록 보장하는 중요한 단계입니다.
3.2 Model Training
- VLM2Vec의 역할
- CEMTM은 문서의 텍스트와 이미지 콘텐츠를 "contextualized representations"(문맥화된 표현)으로 인코딩하기 위해 VLM2Vec [9] 을 사용합니다.
- VLM2Vec은 LLaVA-Next-7B 의 미세 조정된(fine-tuned) 버전입니다. 이는 특정 목적에 맞게 모델이 더 최적화되었음을 의미합니다.
- 문서 임베딩의 한계 및 토큰 임베딩의 필요성
- CEMTM: "document embeddings"(문서 임베딩)가 풍부한 의미론적 정보를 인코딩하더라도, 오직 문서 임베딩만을 사용하여 토픽 분포를 추론하는 것은 "vocabulary-level topic-word associations"(어휘 수준의 토픽-단어 연관성)에 대한 접근을 막아 "interpretability"(해석 가능성)를 제한한다는 것입니다.
- 이러한 한계를 해결하기 위해 CEMTM은 문서 전체의 임베딩 대신, 문서에서 "contextualized token embeddings"(문맥화된 토큰 임베딩)를 추출합니다.
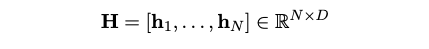
- 추출된 문맥화된 토큰 임베딩 (H)
- H: 문서에서 추출된 모든 문맥화된 토큰 임베딩을 담고 있는 행렬입니다.
- N: 문서 내에 있는 텍스트 토큰(textual tokens)과 시각적 패치(visual patches)의 총 개수를 나타냅니다. 즉, 텍스트와 이미지에서 추출된 모든 개별 요소의 수입니다.
- D: 임베딩 공간의 차원(dimensionality)을 나타냅니다. 각 토큰 벡터의 길이를 의미합니다.
- h_i: 각 h_i 는 토큰 i 또는 이미지 패치 i 에 대한 문맥 의존적인 표현(context-dependent representation)입니다. 즉, 단어 하나하나 또는 이미지의 작은 부분 하나하나가 해당 문서의 전체적인 문맥을 반영하여 임베딩된 벡터입니다.
- 해석 가능성(Interpretability) 향상
- 이러한 토큰 수준의 임베딩을 사용함으로써, 각 토픽이 어떤 단어나 이미지 패치와 강하게 연관되어 있는지 명확하게 파악할 수 있게 되어 토픽 모델의 해석 가능성이 크게 향상됩니다.
- 이는 단순히 문서 전체의 의미만 파악하는 것을 넘어, 구체적인 어휘나 시각적 요소가 토픽 형성에 어떻게 기여하는지 이해하는 데 도움을 줍니다.
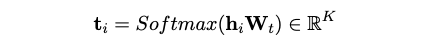
- A Learnable Encoder (Encoder Forward Layer, W)
- K 차원으로 projection 하는 학습가능한 인코더!
- Encoder Forward Layer 의 output 은 t_i 는 각 토큰에 대한 주제분포로 이해할 수 있다.
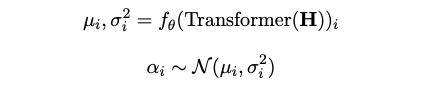
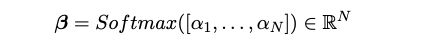
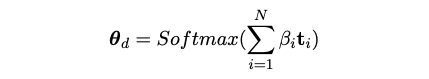
- A Learnable Importance Network and Document-Topic Vector
- 학습가능한 Transformer encoder (feedforward projection layer)
- 목표: 각 토큰에 대한 stochastic weight 예측한다. 문서하나의 Contextualized token embedding (H) 을 input 으로 받아서 mean, standard deviation 을 얻는다.
- Stochastic weight (Beta) 는 얼마나 각 토큰이 혹은 패치가 문서수준에서의 의미에 기여하는지를 예측한다.
- Compute Document-Topic Vector: A weighted average of the token-level topic
vectors
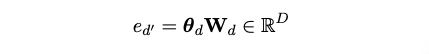
- A Learnable Decoder (Decoder Forward Layer)
- Shape: (K,D)
- Document-Topic Vector (K차원) 을 input 으로 받아, 문서를 D 차원의 임베딩공간으로 mapping 한다.
- 이는 Document-Topic Vector 를 이용해 문서를 reconstruction 하는 과정이다. 재구성된 문서는 model training 에 활용된다.
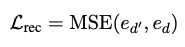
-
- Reconstruction Loss: \(L_{rec}\)
- 이 손실함수는 모델이 학습된 토픽 기반의 재구성된 문서 표현과 원래 LVLM(Large Vision-Language Model)에서 얻은 문서 임베딩 \(e_d\) 간의 유사성을 최대화하도록 합니다.
- \(e_d\) 는 LVLM2Vec에서 얻은 최종 토큰의 히든 스테이트(hidden state)를 문서 임베딩으로 사용한 참조 값입니다. 이는 문서의 전역적인 의미를 담고 있다고 가정합니다.
- \(e_d\) 는 문서의 토픽 벡터(\(\theta_d\))를 학습 가능한 디코더 가중치 \(W_d \in \mathbb{R}^{K \times D}\)를 사용하여 임베딩 공간으로 매핑한 재구성된 문서 표현입니다. 여기서 \(K\)는 잠재 토픽의 수, \(D\)는 임베딩 공간의 차원입니다.
- Reconstruction Loss: \(L_{rec}\)
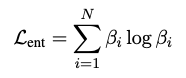
- 엔트로피 정규화 Loss: \(L_{ent}\)
- 이 항은 토큰 중요도 가중치 \(\beta_i\) 분포의 엔트로피를 낮추도록 모델을 유도합니다.
\(\beta_i\): 각 토큰(텍스트 토큰 또는 이미지 패치)이 문서의 의미론적 표현에 기여하는 중요도를 나타내는 확률론적 가중치입니다. \(\beta_i \in [0, 1]\)이며, \(\sum \beta_i = 1\)입니다. - \(\sum_{i=1}^{N} \beta_i \log \beta_i\): 이는 섀넌 엔트로피(\(H(\beta) = -\sum_{i=1}^{N} \beta_i \log \beta_i\))의 음수 값입니다. 즉, 이 값을 최소화하면 엔트로피를 최대화하는 결과를 초래합니다. 하지만 논문에서는 "penalizes high-entropy (i.e., overly uniform) distributions" (높은 엔트로피 분포에 패널티를 부여한다)고 언급합니다. 이는 중요도 점수 \(\beta_i\)가 너무 균일하게 분포되는 것을 막고, 모델이 소수의 관련 요소에 집중하도록 하여 스파스(sparse)하고 해석 가능한 중요도 점수를 장려하기 위함입니다.
- \(L_{ent}\)는 엔트로피를 낮추어 '선명하고 해석 가능한(sharp and interpretable)' 중요도 점수를 유도하는 역할을 합니다. 즉, 이 항을 총 손실에 더함으로써 모델이 엔트로피를 최소화하도록 유도하며, 이는 \(\beta_i\)를 더욱 스파스하게 만듭니다.
- 엔트로피 정규화 목표: 중요도 점수 \(\beta_i\)가 스파스하고 "날카롭게(sharp)" 분포되도록 장려하여, 모델이 문서의 핵심 요소에 집중하고 토픽 할당의 근거를 더 투명하게 만들도록 돕습니다.
- 이 항은 토큰 중요도 가중치 \(\beta_i\) 분포의 엔트로피를 낮추도록 모델을 유도합니다.
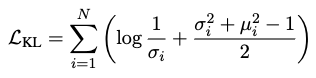
- KL Divergence: \(L_{KL}\)
- 예측된 중요도 분포 \(q(\alpha_i) = \mathcal{N}(\mu_i, \sigma_i^2)\)와 표준 정규 분포 \(p(\alpha_i) = \mathcal{N}(0, 1)\) 사이의 KL 발산(Kullback-Leibler divergence)에 페널티를 부과합니다.
\(\alpha_i\): 중요도 네트워크가 출력하는 각 토큰의 중요도 점수에 대한 가우시안 분포의 샘플 값입니다.
\(\mu_i, \sigma_i^2\): 중요도 네트워크가 각 토큰의 중요도 점수에 대해 예측하는 평균과 분산입니다. - 목표: 중요도 변수 \(\alpha_i\)를 표준 가우시안 분포에 가깝게 유지하여 과적합을 줄이고 잠재 공간을 부드럽고 균형 있게 만듭니다.
특히 multi-modal setting 에서 특정 modality 에 지나치게 편향되거나 과도하게 확신하는 토픽 표현을 방지하는 데 중요합니다.
- 예측된 중요도 분포 \(q(\alpha_i) = \mathcal{N}(\mu_i, \sigma_i^2)\)와 표준 정규 분포 \(p(\alpha_i) = \mathcal{N}(0, 1)\) 사이의 KL 발산(Kullback-Leibler divergence)에 페널티를 부과합니다.
3.3 Topic Extraction
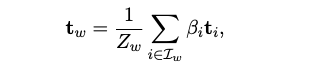
- 토픽 추출의 목표: 학습된 모델을 바탕으로 각 잠재 토픽(latent topic)에 가장 밀접하게 연결된 단어들을 식별하는 것입니다. 이 단어들은 해당 토픽의 의미를 대표하게 됩니다.
- 단어(\(w\)) 정의
- \(w \in V\): 여기서 \(w\)는 전체 어휘 집합 \(V\)에 포함된 하나의 단어를 의미합니다.
- \(I_w\): 말뭉치(corpus) 내에서 단어 \(w\)가 나타나는 모든 위치(\(i\))의 집합입니다. 예를 들어, 어떤 문서에서 'apple'이라는 단어가 5번 나왔다면, \(I_{apple}\)은 이 5개 위치의 인덱스를 포함합니다.
- 집계된 토픽 벡터(\(t_w\)) 계산: 단어 \(w\)에 대한 집계된 토픽 벡터(\(t_w\))는 다음 수식을 통해 계산됩니다.
- \(t_w\): 단어 \(w\)의 집계된 토픽 벡터입니다. 이 벡터는 단어 \(w\)가 어떤 토픽들에 얼마나 강하게 속하는지를 나타냅니다.
- \(Z_w\): 정규화 상수입니다. 모든 중요도(\(\beta_i\))의 합으로, \(Z_w = \sum_{i \in I_w} \beta_i\)와 같이 계산되어 \(t_w\)가 적절히 정규화되도록 합니다.
- \(\sum_{i \in I_w}\): 단어 \(w\)가 나타나는 모든 위치 \(i\)에 대해 합산한다는 의미입니다.
- \(\beta_i\): 토큰 \(i\)의 중요도(importance)입니다. 이 값은 이전에 설명된 중요도 네트워크(importance network)에서 학습되며, 해당 토큰이 문서의 의미론적 표현에 얼마나 기여하는지를 확률적으로 나타냅니다. 이 중요도는 softmax 함수를 거쳐 정규화된 형태를 가집니다.
- \(t_i\): 토큰 \(i\)의 소프트 토픽 분포입니다. LVLM에서 얻은 contextual embedding \(h_i\)를 사용하여 토픽 공간에 투영된 값(\(t_i = \text{Softmax}(h_i W_t)\))입니다.
- 이는 특정 토큰이 각 토픽에 속할 확률을 나타냅니다.
4 Experiments and Results
4.1 Datasets
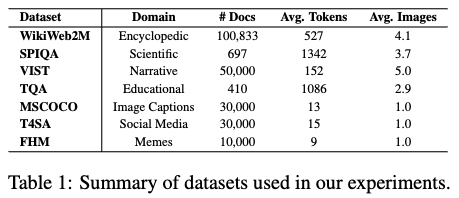
- 다양한 데이터셋: CEMTM은 백과사전, 과학, 내러티브, 교육, 소셜 미디어 등 다양한 도메인과 텍스트 길이(짧은 문서부터 긴 문서까지)를 가진 멀티모달 데이터셋을 활용하여 평가되었습니다.
- Ground-truth Topic Labels (정답 토픽 라벨)
- 제공된 데이터셋 중 WikiWeb2M과 SPIQA 두 가지만 명시적인 'ground-truth topic labels' (정답 토픽 라벨)을 가지고 있습니다.
- 이 라벨들은 정량적 평가(quantitative evaluation)에 사용되어 모델이 실제 토픽 분류와 얼마나 잘 일치하는지 측정할 수 있습니다.
- Unsupervised Metrics (비지도 학습 지표) 사용: 나머지 데이터셋의 경우, 정답 토픽 라벨이 없으므로, 모델이 추출한 토픽의 품질을 'coherence' (일관성) 및 'diversity' (다양성)와 같은 비지도 학습 지표를 사용하여 평가합니다.
4.2 Evaluation Metrics
- Topic Coherence
- NPMI (Normalized Pointwise Mutual Information): 특정 토픽 내에서 함께 나타나는 단어 쌍들의 상호 정보량(Pointwise Mutual Information)을 정규화하여 계산합니다. 이 값이 높을수록 해당 토픽을 구성하는 단어들이 의미론적으로 강하게 연관되어 있어 토픽이 더욱 일관성이 있다고 판단합니다.
- WE (Word Embedding score): 단어 수준의 의미론적 유사성(semantic similarity)을 측정합니다. 토픽을 구성하는 상위 단어들의 워드 임베딩(Word Embedding) 벡터를 활용하여 그들 간의 평균 유사도를 계산합니다. 임베딩 공간에서 단어들이 서로 가까이 위치할수록 의미적으로 유사하다고 간주하며, 이 점수가 높을수록 토픽의 응집력과 일관성이 좋다고 평가합니다.
- LLM score (Large Language Model score) [12]: LLM 을 활용한 토픽의 일관성 평가방법 입니다. LLM에게 추출된 토픽의 단어 목록을 제공하고, 해당 토픽이 얼마나 일관성 있는지 1점에서 3점 척도로 평가하도록 합니다. 이 점수는 인간의 판단과 높은 상관관계를 보여, LLM이 토픽의 의미론적 품질을 효과적으로 평가할 수 있음을 나타냅니다. 이는 특히 토픽의 자연어적 해석 가능성을 반영합니다.
- Topic Diversity
- I-RBO (Inverse Rank-Biased Overlap): 순위 기반 비유사성(rank-aware dissimilarity)을 통한 토픽 다양성(Topic Diversity) 측정. 여러 토픽 간에 상위 단어 목록의 순위가 얼마나 다른지를 평가하여 토픽 간의 중복이 얼마나 적은지를 나타냅니다. 이 값이 높을수록 토픽들이 서로 덜 유사하고 다양하다는 의미로, 각 토픽이 고유한 정보를 담고 있음을 보여줍니다.
- TD (Topic Diversity): 고유 단어 커버리지(unique word coverage)를 통한 토픽 다양성(Topic Diversity) 측정. 각 토픽에서 상위 N개의 단어를 추출했을 때, 전체 토픽에 걸쳐 이 단어들이 얼마나 고유하게 분포되어 있는지를 계산합니다. 예를 들어, 10개 토픽의 상위 100개 단어 중 90개가 서로 다른 단어라면 TD 점수가 높습니다. 높은 TD는 모델이 중복되거나 유사한 토픽이 아닌, 서로 구별되는 다양한 토픽을 효과적으로 생성했음을 의미합니다.
- Downstream Task: 클러스터링 기반 지표 (Clustering-based Metrics)
- 일부 데이터셋(예: WikiWeb2M, SPIQA)에는 실제 토픽 레이블(gold topic labels)이 존재합니다. 이러한 경우, 모델이 예측한 토픽 할당이 실제 레이블과 얼마나 잘 일치하는지 측정하기 위해 클러스터링 기반 지표가 사용됩니다.
- Purity: 클러스터링 결과의 순도를 측정합니다. 각 클러스터 내에서 가장 많이 나타나는 실제 토픽 레이블의 비율을 계산한 후, 이를 모든 클러스터에 대해 가중 평균합니다. 0과 1 사이의 값을 가지며, 1에 가까울수록 클러스터가 단일 토픽으로 잘 구성되어 있음을 의미합니다.
- ARI (Adjusted Rand Index): 예측된 토픽 클러스터와 실제 토픽 레이블 간의 유사성을 측정하는 지표입니다. 무작위로 할당된 클러스터링의 기대값을 보정하여 0과 1 사이의 값을 가집니다. 1에 가까울수록 예측이 실제와 완벽하게 일치함을 나타내고, 0에 가까울수록 무작위 클러스터링과 유사함을 의미합니다.
- NMI (Normalized Mutual Information): 예측된 토픽 클러스터와 실제 토픽 레이블 간의 상호 정보량(Mutual Information)을 정규화한 값입니다. 두 클러스터링 분할이 공유하는 정보의 양을 측정하며, 0과 1 사이의 값을 가집니다. 1에 가까울수록 높은 일치도를 나타냅니다.
4.3 Baselines
- LDA (Latent Dirichlet Allocation): 토픽 모델링의 고전적인 방법론입니다. 각 문서를 Bag-of-Words (BoW) 표현으로 보고, 여러 잠재 토픽의 혼합으로 모델링합니다. 주로 텍스트 데이터에 초점을 맞추며, 단어 간의 순서나 문맥 정보를 고려하지 않습니다.
- Zero-shotTM: SBERT (Sentence-BERT) 임베딩을 활용하여 제로샷(zero-shot) 토픽 모델링을 수행하는 방법입니다. BoW 특징을 임베딩으로 대체하거나 보강하여 문맥 정보를 활용합니다.
- CombinedTM: Zero-shotTM을 확장하여, SBERT 임베딩과 BoW 특징을 결합(concatenating)함으로써 토픽의 해석 가능성(interpretability)을 개선합니다.
- CWTM (Contextualized Word Topic Model) [13]: 문맥화된 토큰 표현(contextual token representations)을 토픽 공간으로 투영하고, 고정되거나 학습된 중요도 점수(importance scores)를 사용하여 토큰별 기여도를 집계합니다.
- TopicGPT [14]
- LLM(Large Language Model)을 활용한 프롬프트 기반(prompt-based) 토픽 모델링 프레임워크입니다. 해석 가능한 자연어 토픽을 생성하지만, 명시적인 topic-word 분포는 제공하지 않습니다.
- CEMTM 논문의 접근: 이 논문에서는 K개의 토픽으로 제한하고, 토큰 레벨의 소프트 할당(soft assignments)을 통해 interpretable한 topic-word 벡터를 구성하여 근사치를 얻습니다.
- Multimodal TopicGPT: TopicGPT를 확장하여 추론 시 텍스트와 이미지 정보를 모두 통합하는 멀티모달(multimodal) 버전입니다.
- M3L-Contrast [15]: 이미지-캡션 정렬(image–caption alignment)을 활용하여 일관된 문서-토픽 표현(document-topic representations)을 학습하는 멀티모달 토픽 모델입니다.
- Multimodal ZeroshotTM: Zero-shotTM을 확장한 모델로, 텍스트 임베딩과 비전 인코더(vision encoder) 특징을 결합하여 멀티모달 데이터를 처리합니다.
- LVLM ZeroshotTM: 이 논문에서 제안하는 기준선 모델 중 하나로, 대규모 시각 언어 모델(LVLM)의 임베딩을 사용하여 더 의미론적으로 기반을 다지고 잘 정렬된 멀티모달 토픽 벡터를 생성합니다. Figure 2 에서 설명된 바와 같이, 이미지 정보를 캡션으로 대체하는 Multimodal Zero-shot TM보다 더 나은 성능을 보여줍니다.
4.4 Quantitative Results
Long-document and In Domain Performance.
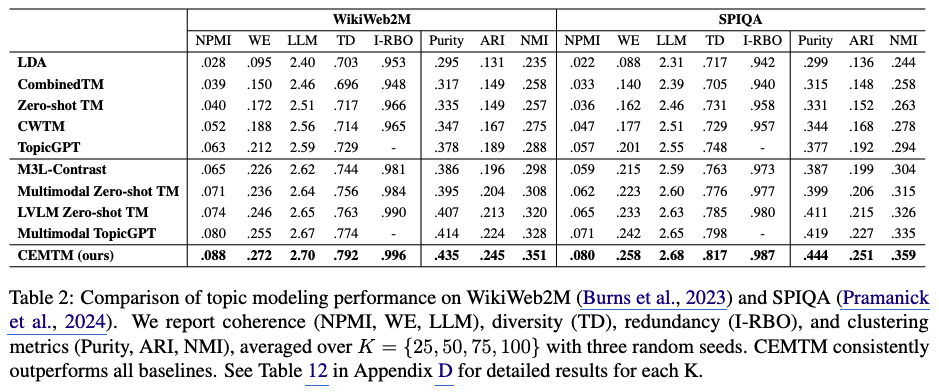
- WikiWeb2M 및 SPIQA 데이터셋 성능
- 데이터셋 특성: WikiWeb2M과 SPIQA는 모두 텍스트와 이미지를 포함하는 길고 복합적인 문서들로 구성되어 있으며, 실제(ground-truth) 토픽 레이블을 가지고 있습니다. 이는 모델이 생성한 토픽을 정량적으로 평가할 수 있게 합니다.
CEMTM의 우수성: CEMTM은 모든 평가 지표에서 기준 모델(baselines)들을 일관적으로 능가하는 성능을 보였습니다. - 토픽 일관성(Topic Coherence): NPMI, WE, LLM score와 같은 지표에서 더 높은 점수를 얻어, CEMTM이 더 의미 있고 이해하기 쉬운 토픽을 추출했음을 나타냅니다.
- 토픽 다양성(Topic Diversity): TD (Topic Diversity) 지표에서 높은 점수를 기록하여, 모델이 중복되지 않고 다양한 토픽을 생성했음을 보여줍니다.
- 토픽 할당 정확도 (Topic Assignment Accuracy): Purity, ARI (Adjusted Rand Index), NMI (Normalized Mutual Information)와 같은 클러스터링 지표에서 우수한 성능을 보여, 실제 토픽 레이블과 예측된 토픽 할당 간의 높은 일치도를 증명했습니다.
- 효율성 및 확장성: CEMTM은 Multimodal TopicGPT나 LVLM Zero-shot TM과 같은 멀티모달 기준 모델들보다도 우수하며, autoregressive decoding이나 여러 번의 순방향 패스(forward passes)가 필요한 TopicGPT와 같은 방식보다 효율적입니다. 특히, 여러 이미지를 포함하는 문서를 반복적인 인코딩 없이 한 번에 처리할 수 있어 성능과 확장성 모두에서 이점을 제공합니다.
- 데이터셋 특성: WikiWeb2M과 SPIQA는 모두 텍스트와 이미지를 포함하는 길고 복합적인 문서들로 구성되어 있으며, 실제(ground-truth) 토픽 레이블을 가지고 있습니다. 이는 모델이 생성한 토픽을 정량적으로 평가할 수 있게 합니다.
Generalization Across Domains.
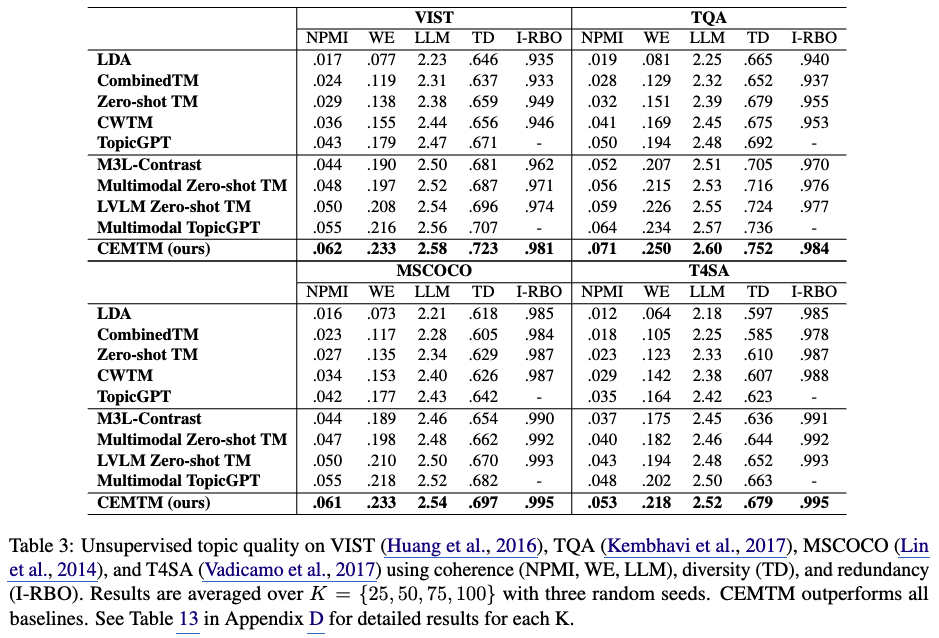
- 평가 데이터셋: Table 3에서는 VIST, TQA, MSCOCO, T4SA라는 네 가지 추가 데이터셋에 대한 CEMTM의 성능을 평가했습니다.
이 데이터셋들은 텍스트와 이미지를 모두 포함하는 짧거나 중간 길이(short and medium-length) 의 멀티모달 문서들로 구성되어 있습니다. - 모델의 유연성: 이러한 결과는 CEMTM이 다양한 도메인에 걸쳐 뛰어난 유연성(flexibility) 을 가지고 있음을 보여줍니다.
- 데이터셋 특징
- VIST 데이터셋: 내러티브(narratives) 도메인을 다룹니다.
- TQA 데이터셋: 교육 콘텐츠(educational content) 도메인을 다룹니다.
- MSCOCO 데이터셋: 캡션이 있는 이미지(captioned images) 도메인을 다룹니다.
- T4SA 데이터셋: 소셜 미디어 게시물(social media posts) 도메인을 다룹니다.
- 일반화 능력: 결론적으로, 이 결과들은 CEMTM 모델이 긴 텍스트 시나리오(long-text scenarios)를 넘어 더 짧거나 중간 길이의 문서에서도 잘 일반화 된다는 것을 시사합니다.
Semantic Gap Analysis using Facebook Hateful Memes (FHM).
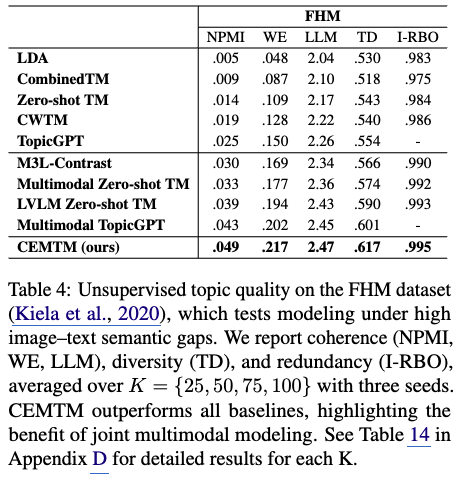
- Semantic Gap 의 정의 및 도전 과제
- 멀티모달 토픽 모델링에서 "시맨틱 갭" 은 이미지와 텍스트가 의미적으로 명확하게 일치하지 않거나, 오히려 상충되는 의미를 가질 때 발생합니다.
밈(memes) 이 대표적인 예시인데, 밈은 이미지가 텍스트와 다른 맥락에서 풍자적이거나 비유적인 의미를 전달하는 경우가 많습니다. - 이러한 시맨틱 갭은 텍스트 콘텐츠에만 의존하는 기존 토픽 모델에게 특히 어려운 과제입니다. 텍스트만으로는 문서의 진정한 주제를 파악하기 어렵기 때문입니다.
- 멀티모달 토픽 모델링에서 "시맨틱 갭" 은 이미지와 텍스트가 의미적으로 명확하게 일치하지 않거나, 오히려 상충되는 의미를 가질 때 발생합니다.
- 모델 성능 비교 및 LVLMs의 중요성
- 유니모달(Unimodal) vs. 멀티모달(Multimodal) 모델: 실험 결과, 이미지 정보를 고려하는 멀티모달 모델들이 텍스트 정보에만 의존하는 모델들보다 전반적으로 더 우수한 성능을 보였습니다. 이는 시각적 정보가 의미적 갭을 메우는 데 중요한 역할을 함을 의미합니다.
- 대규모 시각-언어 모델(LVLMs)의 효과: 특히 LVLM Zero-shot TM, Multimodal TopicGPT, 그리고 CEMTM과 같이 LVLMs(Large Vision-Language Models) 를 활용하는 모델들이 가장 높은 성능 향상(highest gains)을 기록했습니다.
- 이는 LVLMs가 이미지와 텍스트 간의 복잡한 교차-모달(cross-modal) 상호작용을 깊이 있게 이해하고 인코딩하는 데 뛰어난 능력이 있음을 시사합니다.
- CEMTM 설계의 유효성 검증
- 이러한 결과는 CEMTM의 핵심 설계가 유효함을 입증합니다. CEMTM은 fine-tuned LVLM embeddings와 유연한 importance-weighted fusion mechanism을 활용하여 교차-모달 시맨틱을 효과적으로 포착하도록 설계되었습니다.
- 이러한 설계 덕분에 CEMTM은 밈과 같이 의미적으로 모호한(semantically ambiguous) 맥락에서도 높은 품질의 토픽 모델링을 수행할 수 있습니다. 즉, 더 나은 멀티모달 정렬(alignment)이 토픽 모델링 성능을 크게 개선함을 보여줍니다.
4.5 Improving Few-Shot Multimodal QA with Topic-Aware Retrieval
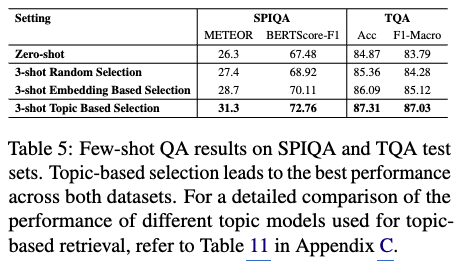
- Few-shot QA 문제 정의
- Few-shot QA는 소수의 예시(in-context examples)를 사용하여 QA 모델의 성능을 향상시키는 태스크입니다.
- 이 연구에서는 CEMTM이 학습한 document-topic vectors(문서-토픽 벡터)를 활용하여 QA 모델에 제시할 적절한 in-context examples를 검색하는 데 사용했습니다.
- 이때 토픽의 개수 K는 50으로 설정되었습니다.
- 네 가지 검색 전략 비교: 이 연구는 SPIQA와 TQA 데이터셋에서 다음 네 가지 in-context examples 검색 전략을 비교했습니다.
- Zero-shot Baseline: QA 모델에 어떠한 예시도 제공하지 않고 질문만 주어 답변을 생성하게 하는 가장 기본적인 설정입니다.
- Random Selection (3 examples): 3개의 in-context examples를 무작위로 선택하여 QA 모델에 제공하는 방식입니다.
- Embedding-based Retrieval: OpenAI의 text-embedding-3-small 임베딩(OpenAI’s text-embedding-3-small)을 사용하여 질문과 가장 유사한 예시를 cosine similarity(코사인 유사도) 기반으로 검색하는 방식입니다. 이는 임베딩 공간에서 텍스트의 표면적인 또는 직접적인 의미 유사성을 활용합니다.
- Topic-based Retrieval (CEMTM): CEMTM이 생성한 document-topic vectors를 사용하여 토픽 분포 관점에서 질문과 가장 관련성이 높은 예시를 검색하는 방식입니다. 이는 문서의 고수준(high-level) 의미론적 구조를 기반으로 합니다.
- 실험 결과 및 의미
- Table 5에 제시된 결과에 따르면, CEMTM의 topic-based retrieval 전략이 SPIQA 데이터셋에는 METEOR 및 BERTScore, TQA 데이터셋에서는 Accuracy 및 Macro-F1 등 모든 평가 지표에서 다른 세 가지 방법(특히 embedding-based retrieval 포함)보다 훨씬 우수한 성능을 보였습니다.
- 이는 CEMTM이 학습한 토픽 분포가 문서의 고수준 의미론적 구조(high-level semantic structure)를 효과적으로 포착한다는 것을 의미합니다.
- 이러한 토픽 분포는 단순히 표면적인 유사성(direct surface similarity)에 의존하는 것이 아니라, 관련성 있고 다양한 컨텍스트를 제공하여 Few-shot QA 모델이 더 정확하고 풍부한 답변을 생성하도록 돕습니다.
- 결론적으로, 이 결과는 CEMTM이 단순히 토픽의 해석 가능성(topic interpretability)을 제공하는 것을 넘어, 실제 다운스트림 태스크(downstream task)인 Few-shot QA에서도 강력한 잠재력을 가지고 있음을 보여줍니다.
4.6 Qualitative Results
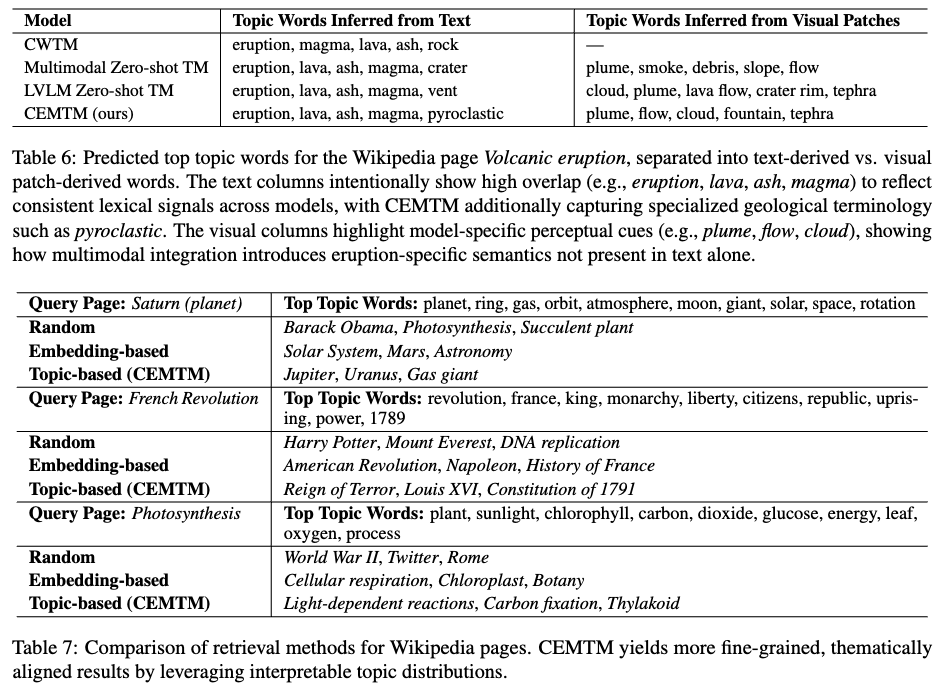
- CEMTM 의 시맨틱 검색 강화
- CEMTM은 문서-토픽 벡터를 비교함으로써 각 검색 질의(query)에 대해 주제적으로(thematically) 더욱 정확하고 세분화된(fine-grained) 위키피디아 페이지를 검색할 수 있습니다.
- 이는 무작위(random) 선택 방식이나 단순히 임베딩(embedding) 기반의 유사도를 사용하는 기존 방법들보다 뛰어난 성능을 보여줍니다.
- 기존 검색 방법들과의 비교
- 무작위 선택 (Random selection): 이 방법은 특정 주제와 관련 없는 문서를 가져오므로, 효과적인 검색이 어렵습니다.
- 임베딩 기반 선택 (Embedding-based selection): OpenAI의 text-embedding-3-small과 같은 임베딩을 사용하여 코사인 유사도(cosine similarity)를 기반으로 관련 페이지를 검색합니다. 이 방법은 넓은 범위에서 관련 있는 페이지를 찾지만, 특정 주제에 대한 세밀한(topical granularity) 정도는 부족할 수 있습니다.
- 토픽 기반 선택 (Topic-based selection, CEMTM): CEMTM은 문서의 핵심 의미 영역(core semantic fields)에 기반하여 'Gas giant' (Saturn에 대해), 'Reign of Terror' (French Revolution에 대해), 'Thylakoid' (Photosynthesis에 대해)와 같이 매우 구체적이고 문맥적으로 잘 정렬된(contextually aligned) 문서를 식별합니다.
- CEMTM
- CEMTM은 더 해석 가능한(interpretable) 신호를 포착할 뿐만 아니라, 문서의 주제 구조(thematic structure)를 더 잘 모델링합니다.
- 이러한 능력 덕분에 소수 학습 프롬프트(few-shot prompting)나 말뭉치(corpus) 탐색과 같은 후속 작업에서 특히 유용합니다.
5 Ablation Studies
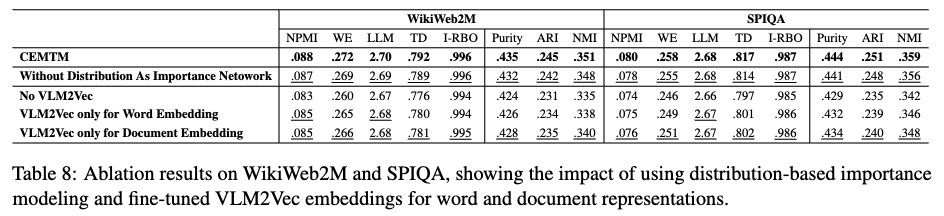
5.1 Impact of Vision-Language Embedding Quality
- 연구 목적: VLM2Vec(VLM to Vector) 임베딩의 품질, 특히 LLaVA-Next-7B 모델을 미세 조정하여 얻은 VLM2Vec 임베딩이 CEMTM의 토픽 표현 정확도에 얼마나 중요한지 분석합니다.
- 실험 설정
- CEMTM 모델에서 VLM2Vec을 활용하는 방식을 다르게 설정한 여러 변형 모델을 비교했습니다.
- CEMTM (원본 모델): 미세 조정된 LLaVA-Next-7B 기반의 VLM2Vec을 텍스트와 이미지 토큰의 문맥화된 임베딩(contextualized token embeddings) 및 최종 문서 임베딩(document embedding)을 생성하는 데 모두 사용한 경우입니다. Table 8에서 모든 지표에서 가장 높은 성능을 기록했습니다.
- No VLM2Vec: 미세 조정된 LLaVA-Next-7B 기반의 VLM2Vec 대신, 사전 훈련만 된 LLaVA-Next-7B를 문서 인코딩에 사용한 경우입니다. 이 설정은 CEMTM 성능에 가장 큰 하락을 가져왔으며, 특히 문서 클러스터링 관련 지표(Purity, ARI, NMI)에서 두드러진 성능 저하를 보였습니다. 이는 정렬(alignment)을 고려한 미세 조정 임베딩이 정확한 토픽 표현에 매우 중요함을 시사합니다.
- VLM2Vec only for Word Embedding: VLM2Vec을 단어 토큰 임베딩에만 사용하고, 문서 임베딩에는 다른 방식을 사용한 경우입니다. 원본 CEMTM보다는 성능이 떨어지지만, 'No VLM2Vec'보다는 나은 중간 정도의 성능을 보였습니다.
- VLM2Vec only for Document Embedding: VLM2Vec을 최종 문서 임베딩에만 사용하고, 단어 토큰 임베딩에는 다른 방식을 사용한 경우입니다. 이 역시 원본 CEMTM보다는 성능이 떨어지지만, 'No VLM2Vec'보다는 나은 중간 정도의 성능을 보였습니다.
- Findings
- 'No VLM2Vec' 변형에서 가장 큰 성능 하락이 발생했다는 점은 정렬 인식(alignment-aware) 미세 조정 임베딩이 정확한 토픽 표현에 필수적임을 강력하게 보여줍니다.
- VLM2Vec을 토큰 임베딩 또는 문서 임베딩 중 하나에만 사용하는 경우, 각각 개별적으로 도움이 되지만, 모델 전체에 걸쳐 VLM2Vec을 완전히 활용할 때 가장 강력한 성능 향상을 얻을 수 있습니다.
- 이는 단어 수준과 문서 수준 모두에서 의미론적으로 정렬된 멀티모달 표현이 토픽 모델링의 성능과 해석 가능성을 높이는 데 중요함을 강조합니다.
5.2 Role of Distributional Supervision in the Importance Network
- 중요도 가중치 모델링 방식의 차이
- 결정론적 방식 (Deterministic values, simple softmax network): 일반적으로 중요도 가중치는 단순히 소프트맥스(softmax) 네트워크의 직접적인 출력값으로 결정됩니다. 이 경우, 각 토큰의 중요도는 단일 고정 값으로 계산됩니다.
- 분포 기반 방식 (Samples from a learned Gaussian distribution): CEMTM에서는 각 토큰 \(i\)의 중요도 점수 \(\alpha_i\)를 학습된 정규 분포 \(N(\mu_i, \sigma_i^2)\)에서 샘플링합니다. 여기서 \(\mu_i\)와 \(\sigma_i^2\)는 중요도 네트워크(importance network)가 학습하는 파라미터입니다. 이렇게 샘플링된 \(\alpha_i\) 값들은 소프트맥스 함수를 통해 정규화되어 최종 중요도 가중치 \(\beta_i\)를 형성합니다.
- Importance Network: 컨텍스트화된 토큰 임베딩 \(H = [h_1, \ldots, h_N]\)을 입력받아 각 토큰의 중요도에 대한 평균과 분산을 출력합니다.
- Importance Network 로 인한 성능 향상 효과
- 강건성(Robustness) 증가: 중요도 가중치를 확률 분포에서 샘플링함으로써 모델은 불확실성을 명시적으로 모델링하고, 예측의 변동성을 줄여 다양한 입력에 대해 더 안정적이고 강건한 성능을 보입니다.
- 의미론적 관련성에 대한 집중: 이 확률적 중요도 모델링은 모델이 문서의 의미에 가장 관련성이 높은 텍스트 토큰이나 이미지 영역에 더 효과적으로 집중하도록 돕습니다. 이는 덜 중요한 정보나 노이즈의 영향을 줄이는 데 기여합니다.
- 고품질 및 해석 가능한 토픽 구조: 결과적으로, 이러한 집중 능력은 더 일관성(coherence) 있고, 다양성(diversity) 있는 고품질의 토픽을 도출하게 합니다. 또한, 각 토큰이 토픽에 기여하는 정도를 확률적으로 표현함으로써 토픽 구조의 해석 가능성을 높입니다.
- 실험적 증거 (Table 8)
- 논문의 Table 8은 분포 기반 중요도 모델링(Distributional Supervision)을 제거하고 단순한 소프트맥스 네트워크로 대체했을 때의 성능 변화를 보여줍니다.
- 실험 결과, 일관성(NPMI, WE, LLM), 다양성(TD), 클러스터링 지표(Purity, ARI, NMI) 등 모든 평가 지표에서 일관된 성능 하락이 관찰되었습니다. 이는 분포 기반 중요도 모델링이 CEMTM 모델의 성능과 토픽 품질에 필수적인 요소임을 강력하게 뒷받침합니다.
5.3 Role of Visual Signals in Multimodal Topic Modeling

- 이미지 모달리티 제거 시 성능 저하
- WikiWeb2M 및 SPIQA 데이터셋에서 이미지 모달리티를 완전히 제거했을 때(CEMTM w/o Image), CEMTM 모델의 성능이 토픽 일관성(topic coherence) 및 클러스터링 품질(clustering quality)을 포함한 모든 평가 지표에서 상당히 저하되었습니다.
- 이는 시각적 신호가 일관성 있고 품질 높은 토픽을 추출하고 문서를 정확하게 클러스터링하는 데 매우 중요하다는 것을 시사합니다.
- 이미지를 캡션으로 대체 시 성능 한계점
- 이미지를 GPT-4o와 같은 대규모 언어 모델(LLM)로 자동 생성된 캡션(caption)으로 대체했을 때(CEMTM w/ Caption), 이미지를 완전히 제거한 경우(w/o Image)보다는 성능이 향상되었습니다.
- 하지만, 텍스트와 이미지를 모두 직접 사용하는 원본 CEMTM 모델만큼의 성능에는 미치지 못했습니다.
- 이러한 결과는 Visual Storytelling [16] 이나 [17] 과 같은 기존 연구들이 강조하는 바와 같이, 캡션이 시각적 콘텐츠에 대한 부분적인 정보만을 제공하는 반면, 직접적인 이미지 특징(direct image features)은 더 풍부하고 심층적인 멀티모달 정보를 포착한다는 사실과 일맥상통합니다.
- 종합적으로, 이 연구 결과는 멀티모달 토픽 모델링에서 텍스트 기반의 대체물(textual surrogates)에만 의존하기보다는 이미지 표현을 직접 모델에 통합하는 것이 필수적이라는 점을 강조합니다.
6 Conclusion
- 모델의 목표 및 특징
- CEMTM은 짧은 문서와 긴 문서 모두에서 텍스트와 이미지를 동시에 처리하여 일관성 있고 해석 가능한 토픽 구조를 찾아내는 것을 목표로 합니다.
- 이는 'interpretable multi-modal topic model'로, 토픽의 의미를 사람이 이해하기 쉽게 유지하는 데 중점을 둡니다.
- 핵심 기술
- Fine-tuned LVLM embeddings: 사전 학습된 대규모 Vision-Language Model(LVLM)을 미세 조정(fine-tuned)하여 문서의 텍스트와 이미지로부터 'contextualized representations' (문맥을 고려한 임베딩)을 얻습니다. 이 임베딩은 텍스트와 이미지의 의미를 통합적으로 표현합니다.
- Distributional attention mechanism: 토큰(단어 또는 이미지 패치)이 토픽 추론에 기여하는 정도를 가중치(weight)로 부여하는 메커니즘을 사용합니다. 이는 토큰별 중요도를 확률 분포(distributional) 형태로 학습합니다.
- Reconstruction-based training objective: 토픽 기반으로 재구성된 문서 표현(\(e_{d}'\))을 원래 LVLM에서 얻은 문서 임베딩(\(e_d\))과 일치시키려는 재구성 목적 함수(\(L_{rec} = MSE(e_{d}', e_d)\))를 사용합니다. 이는 다양한 양식(modalities) 간의 의미론적 일관성을 강화합니다.
- Importance-weighted fusion: 토큰별 중요도(\(\beta_i\))를 가중치로 사용하여 토큰 수준의 토픽 벡터(\(t_i\))를 결합함으로써 문서 토픽 벡터(\(\theta_d\))를 생성합니다.
- 주요 이점
- 문서 수준 의미론 포착: LVLM의 강력한 표현력을 활용하여 문서 전체의 복합적인 의미를 효과적으로 포착합니다.
- 해석 가능성 유지: 명시적인 단어-토픽 및 문서-토픽 분포를 제공하며, 중요도 네트워크(\(\beta\))를 통해 어떤 토큰이 토픽 형성에 중요한 역할을 했는지 보여주므로 해석 가능성(interpretability)을 높입니다.
- 다중 이미지 처리 효율성: 기존 방식과 달리 문서당 여러 이미지를 반복적인 인코딩 없이 한 번에 처리할 수 있습니다.
- 성능 평가
- 6개의 멀티모달 벤치마크 데이터셋에서 광범위한 실험을 수행했습니다.
- 단일 모달 및 멀티모달 기존 모델(baselines)들을 일관되게 능가하는 성능을 보였습니다.
- 평균 LLM 점수(LLM score) 3점 만점에 2.61점, Purity 점수(Purity score) 0.44를 달성했습니다.
- 어블레이션 스터디(ablation study)를 통해 미세 조정된 LVLM과 분포 기반 감독(distributional supervision)이 토픽 품질을 향상하는 데 중요한 역할을 함을 입증했습니다.
- 활용 분야: CEMTM은 확장 가능(scalable)하고 설명 가능한(explainable) 프레임워크로서, 소수 학습 검색(few-shot retrieval), 멀티모달 요약(multimodal summarization), 그리고 말뭉치 수준의 토픽 분석(corpus-level topic analysis)과 같은 다양한 작업을 효율적이고 해석 가능하게 수행할 수 있습니다.
Limitations
- 높은 계산 비용 및 자원 요구사항
- CEMTM은 사전 훈련된 Large Vision Language Models (LVLM)에 크게 의존합니다.
- 이는 상당한 계산 오버헤드를 발생시키며, 대규모 GPU 자원을 필요로 합니다.
- 따라서 자원이 부족한 환경(low-resource)이나 실시간(real-time) 환경에서의 적용에 제약이 있을 수 있습니다.
- 토픽의 독립성 및 해석 가능성 문제
- 모델의 재구성(reconstruction) 목적은 토픽 벡터와 문서 임베딩을 정렬하지만, 각 토픽이 완전히 분리되거나 독립적으로 해석 가능하다는 것을 보장하지는 않습니다.
- 특히 문서들이 중복되는 개념을 다루거나 시각 정보에 노이즈 또는 중복이 많을 때 이러한 문제가 발생할 수 있습니다.
- 언어 및 문화적 범위 제한
- 현재 평가는 영어 기반 데이터셋에만 초점을 맞추고 있습니다.
- 다국어(multilingual) 또는 다문화(cross-cultural) 환경에서는 시각적 의미(visual semantics)와 토픽 해석 가능성(topic interpretability)이 크게 다를 수 있으므로, 이러한 환경에서의 모델 성능은 아직 탐구되지 않았습니다.
- 중요도 네트워크 가중치의 검증 부족
- 중요도 네트워크(importance network)는 어텐션 희소성(attention sparsity)을 통해 해석 가능성을 높이지만, 학습된 가중치가 사람의 판단(human judgments)에 대해 명시적으로 검증되지 않았습니다.
- 이는 향후 설명 가능성(explainability) 연구 및 사용자 참여형(user-in-the-loop) 토픽 개선 분야에서 추가 연구가 필요함을 시사합니다.
Reference
[1] Topic regression multi-modal latent dirichlet allocation for image annotation (CVPR 2010)
[2] Visual information in semantic representation (NAACL 2010)
[3] Neural Multimodal Topic Modeling: A comprehensive evaluation (LREC 2024)
[4] Large Language Models Offer an Alternative to the Traditional Approach of Topic Modelling (LREC 2024)
[5] TopicGPT: A Prompt-based Topic Modeling Framework (NAACL 2024)
[6] PromptMTopic: Unsupervised Multimodal Topic Modeling of Memes using Large Language Models
[7] A Review of Stability in Topic Modeling: Metrics for Assessing and Techniques for Improving Stability
[8] CWTM: Leveraging contextualized word embeddings from BERT for neural topic modeling (LREC 2023)
[9] VLM2vec: Training vision-language models for massive multimodal embedding tasks
[10] SupDocNADE: Topic Modeling of Multimodal Data: An Autoregressive Approach
[11] Graph-based multimodal topic modeling with word relations and object relations
[12] Revisiting automated topic model evaluation with large language models
[13] CWTM: Leveraging Contextualized Word Embeddings from BERT for Neural Topic Modeling (LREC 2023)
[14] TopicGPT: A Prompt-based Topic Modeling Framework (NAACL 2024)
[15] Multilingual and Multimodal Topic Modelling with Pretrained Embeddings (COLING 2022)
[16] Visual Storytelling
[17] Visual Information in Semantic Representation