
Toward Privacy-preserving Text Embedding Similarity with Homomorphic Encryption [EMNLP 2022 Workshop (FinNLP)]
Donggyu Kim, Garam Lee, Sungwoo Oh
Abstract
- 텍스트 임베딩의 중요성 및 개인 정보 보호 문제
- 텍스트 임베딩(Text Embedding): 텍스트를 숫자로 된 벡터(vector) 형태로 변환하는 필수적인 기술입니다. 이를 통해 검색 엔진이나 챗봇과 같은 자연어 처리(NLP) 애플리케이션에서 텍스트 간의 유사성을 효율적으로 계산할 수 있습니다.
- 민감 산업의 개인 정보 보호 요구: 금융 및 헬스케어와 같은 특정 산업에서는 사용자 데이터가 서비스 제공자를 포함한 잠재적인 악의적 사용자에게 노출되지 않아야 하는 엄격한 개인 정보 보호 조건이 요구됩니다.
- Inversion Attacks(역공격) 위험: 텍스트 임베딩은 겉보기에는 해석 불가능해 보이지만, "inversion attacks"을 통해 원래 텍스트로 복원될 수 있는 개인 정보 유출 위험이 존재합니다. 이는 임베딩에서 원본 데이터를 역추적하여 재구성하는 공격을 의미합니다.
- 동형 암호화(Homomorphic Encryption, HE) 기반 접근 방식
- 목표: 이러한 개인 정보 보호 요구 사항을 충족하기 위해, 본 논문에서는 동형 암호화(HE)에 기반한 텍스트 유사성 추론 방법을 연구합니다.
- HE의 특징: HE는 데이터를 복호화(decryption)하지 않고도 암호화된 상태에서 직접 계산을 수행할 수 있게 하는 암호학 기술입니다. 이는 민감한 데이터를 서버에 노출시키지 않고도 텍스트 유사성 계산을 가능하게 합니다.
- 방법 검증 및 실험 결과
- 실험: 제안된 방법의 유효성을 검증하기 위해 두 가지 핵심적인 텍스트 유사성 작업 1) STS (Semantic textual
similarity) 2) Text retrieval 에 대해 광범위한 실험을 수행했습니다. - Inversion Attack 취약성 증명
- 텍스트 임베딩 inversion 테스트를 통해 벤치마크 데이터셋이 inversion attacks에 취약하다는 것을 입증했습니다.
- dχ-privacy (Differential Privacy, DP) 의 한계: 개인 정보 보호를 위한 또 다른 접근 방식인 dχ-privacy (Local Differential Privacy의 완화된 버전)는 이러한 inversion attacks를 방지하는 데 실패했음을 확인했습니다. 이는 데이터에 노이즈(noise)를 추가하여 개인 정보를 보호하려는 방식입니다.
- 본 논문 접근 방식의 성능: 본 논문의 접근 방식은 최소한의 보안 설정에서도 최대 10%의 성능 저하를 보이는 baseline과 비교하여 모델 성능을 성공적으로 보존함을 보여주었습니다. 이는 개인 정보 보호와 모델 성능 유지라는 두 가지 목표를 모두 달성했음을 의미합니다.
- 실험: 제안된 방법의 유효성을 검증하기 위해 두 가지 핵심적인 텍스트 유사성 작업 1) STS (Semantic textual
1 Introduction
- 텍스트 임베딩의 활용: 텍스트 임베딩은 텍스트 간 유사도를 추론하여 document search, intent decision, dialogue response selection 등 다양한 NLP 기능을 효율적으로 구현하는데에 크게 기여합니다. 미리 계산된 임베딩을 활용하여 실시간 애플리케이션에 적용됩니다.
- 인버전 공격 (Inversion Attacks): 텍스트 임베딩의 이러한 사용은 "인버전 공격"이라는 새로운 개인정보 보호 위험을 야기합니다. 이 공격은 임베딩으로부터 원본 텍스트를 복구할 수 있게 합니다 [1].

- 민감한 데이터의 중요성 (Table1)
- 금융 및 헬스케어와 같은 특정 산업에서는 사용자 데이터가 서비스 제공자를 포함한 잠재적 악의적인 사용자에게 노출되어서는 안 된다는 엄격한 개인정보 보호 조건이 요구됩니다.
- 사용자의 Know-Your-Customer (KYC) 문의와 같은 텍스트에는 사용자를 식별할 수 있는 개인 정보뿐만 아니라 자산, 미래 행동에 대한 단서 또는 의도와 같은 민감한 데이터가 포함될 수 있습니다
- 악의적인 사용자의 분류
- 논문에서는 사용자 개인정보에 대한 권한이 없는 악의적인 사용자를 두 가지 범주로 정의합니다.
- 외부 악의적인 사용자: 서비스 외부에서 데이터나 서버에 접근하여 공격을 수행하는 사용자입니다.
- 내부 악의적인 사용자: 금융과 같이 엄격한 개인정보 보호가 필요한 특정 도메인에서는 서비스 제공자를 포함한 내부 사용자조차도 데이터 접근이 차단되어야 합니다.
- Motivation
- HE의 보안 안정성: 동형 암호화는 데이터를 복호화하지 않고도 암호화된 상태에서 모든 계산을 수행할 수 있습니다 [2]. 이로 인해 매우 엄격한 개인 정보 보호 요건을 충족할 수 있습니다.
- Inversion Attacks 방어: 이 기술은 텍스트 임베딩에서 원본 텍스트를 복구하려는 반전 공격으로부터 사용자의 데이터를 보호합니다. 이는 서비스 외부의 공격자뿐만 아니라, 금융이나 의료와 같이 엄격한 개인 정보 보호가 필요한 산업에서 서비스 제공자까지 포함한 '내부 악의적인 사용자'로부터도 데이터를 안전하게 지킬 수 있다는 것을 의미합니다.
- 다른 암호화 기술의 한계: 다른 대부분의 암호화 기술은 계산을 수행하기 위해 서버 측에서 데이터의 복호화가 필요합니다 [3]. 이는 복호화 과정에서 데이터가 노출될 위험이 있어 엄격한 개인 정보 보호 요구 사항을 충족하기 어렵게 만듭니다.
- dχ-privacy의 한계: Local Differential Privacy(LDP)의 변형인 dχ-privacy와 같은 다른 개인 정보 보호 방법은 '개인 정보 보호-유틸리티 균형(privacy-utility trade-off)' 문제를 고려해야 합니다 [4]. 이는 개인 정보 보호 수준을 높일수록 데이터의 유용성(성능)이 저하될 수 있음을 의미하며, 이 논문의 연구 목표인 높은 성능 유지를 만족시키지 못할 수 있습니다.

- HE 기반 텍스트 유사도 추론 과정
- 서버 측 사전 준비: 검색 문서와 같은 대량의 서버 측 텍스트 임베딩은 미리 계산되어 중앙 집중식 서버에 업로드됩니다. 서비스 제공자는 이 데이터베이스에 접근할 수 있으므로, 서버 측 임베딩은 암호화되지 않은 상태로 가정합니다.
- 사용자 키 생성 및 쿼리 암호화: 서비스 사용자는 동형 암호화(HE)를 위한 공개키(public key)와 비밀키(secret key)를 생성합니다. 이어서 사용자의 쿼리 텍스트를 임베딩으로 변환한 후, 이 임베딩을 자신의 공개키로 암호화합니다.
- 암호화된 쿼리 전송 및 외부 공격 방어 (a): 사용자가 암호화된 쿼리 임베딩을 서버로 전송할 때, 데이터는 이미 암호화되어 있으므로 어떠한 외부 악의적인 사용자도 원본 데이터에 접근할 수 없습니다. 이는 (a) 지점에서의 역변환 공격을 효과적으로 방어합니다.
- 서버 내 암호화된 연산 및 내부 공격 방어 (b): 암호화된 쿼리 임베딩이 서버에 도달하면, 서버는 데이터를 복호화하지 않고도 HE 기반 유사도 함수를 사용하여 추론을 수행할 수 있습니다. 서비스 제공자조차도 사용자의 비밀키를 가지고 있지 않기 때문에 암호화된 데이터로부터 어떤 정보도 추출할 수 없으며, 따라서 (b) 지점에서의 역변환 공격으로부터 안전합니다.
- 암호화된 결과 전송 및 사용자 복호화: 서버는 여전히 암호화된 상태의 결과를 사용자에게 안전하게 전송하며, 사용자는 자신의 비밀키를 이용하여 최종 결과를 복호화합니다.
- dχ-privacy와의 비교
- dχ-privacy는 지역 차등 프라이버시(Local Differential Privacy, LDP)의 한 변형으로, 텍스트 임베딩에 노이즈를 주입하여 정보 유출을 방지하는 방법입니다.
- 이 방법은 프라이버시-유용성(privacy-utility) 트레이드오프 문제에 직면하며, 실험 결과 낮은 노이즈 설정에서도 모델 성능이 최대 10%까지 저하되고 여전히 정보 유출의 가능성을 보였습니다.
- 논문에서 제안하는 HE 기반 접근 방식은 역변환 공격으로부터 완전한 보호를 제공하면서도 모델의 성능 저하를 거의 발생시키지 않습니다.
- Main Contributions
- 인버전 공격(Inversion Attacks)에 대한 취약성 입증
- 연구는 널리 사용되는 벤치마크 데이터셋(benchmark datasets)과 사전 훈련된(pretrained) 텍스트 임베딩 모델들이 'inversion attacks'에 취약하다는 것을 보여줍니다.
- Inversion attacks 이란 텍스트 임베딩(텍스트를 수치화한 벡터 표현)으로부터 원래의 텍스트를 복구하려는 시도를 말합니다. 겉으로는 암호화된 것처럼 보이는 텍스트 임베딩도 이러한 공격을 통해 민감한 정보가 노출될 수 있음을 증명했습니다.
- 기존의 개인정보 보호 방식 (PPML) 중 하나인 dχ-privacy (노이즈 기반 Local Differential Privacy의 변형)는 이러한 공격을 완전히 방지하지 못하며, 성능 저하를 수반한다는 점을 지적합니다.
- 동형 암호(HE) 기반 텍스트 유사성 함수 구현
- 이 논문은 동형 암호 기술을 활용하여 암호화된 상태에서 텍스트 유사성을 계산할 수 있는 함수를 구현했습니다.
동형 암호는 데이터를 복호화(decryption)하지 않고도 암호화된 상태에서 직접 연산을 수행할 수 있게 하는 암호 기술입니다. 이는 서비스 제공자조차도 사용자 데이터를 볼 수 없도록 보장하여, 금융 및 헬스케어와 같이 엄격한 개인정보 보호가 요구되는 산업에 특히 중요합니다 - 이를 통해 원본 텍스트의 성능을 거의 정확하게 근사하면서(precisely approximate) 잠재적인 정보 유출을 완전히 방지할 수 있습니다.
- 이 논문은 동형 암호 기술을 활용하여 암호화된 상태에서 텍스트 유사성을 계산할 수 있는 함수를 구현했습니다.
- 완전한 개인정보 보호 유사성 작업 달성 및 성능 유지
- 다양한 실험(Semantic Textual Similarity 및 Text Retrieval)을 통해 제안된 HE 기반 방법이 모델 성능 저하 없이 완전한 개인정보 보호 텍스트 유사성 작업을 달성함을 입증했습니다. 이는 기존의 텍스트 유사성 측정 및 임베딩 방식이 가진 한계를 보완하는 중요한 진전입니다.
- 기존의 dχ-privacy 방식이 노이즈 추가에 따라 성능이 최대 10%까지 저하되면서도 정보 유출 가능성을 완전히 막지 못하는 것과 달리, 이 논문의 HE 기반 접근 방식은 거의 동일한 성능을 유지하면서 강력한 보안을 제공합니다.
- 인버전 공격(Inversion Attacks)에 대한 취약성 입증
2 Related Work
2.1 Text similarity with embeddings
- 텍스트 유사도의 중요성: 검색 엔진이나 챗봇과 같은 자연어 애플리케이션을 구축하는 데 텍스트 유사도 측정은 매우 핵심적인 기능입니다.
- 어휘적 매칭 방식의 한계 극복: TF-IDF, BM25와 같은 기존의 전통적인 어휘적 매칭 방식은 단어의 표면적인 일치 여부에 기반하여 의미를 제대로 포착하지 못하는 한계가 있습니다.
- 텍스트 임베딩의 등장: 이러한 한계를 극복하기 위해 자연어 텍스트를 의미론적 정보를 담은 벡터 형태인 '텍스트 임베딩'으로 변환하는 방식이 널리 사용됩니다. 텍스트 임베딩을 사용하면 텍스트 간의 유사도는 벡터 공간 내 데이터 포인트 간의 '거리'로 해석될 수 있습니다.
- 효율적인 계산: 임베딩은 미리 계산(precompute)될 수 있어, 대규모 텍스트 유사도 추론(inference)을 실시간 애플리케이션에서 효율적으로 수행할 수 있게 합니다 [5]. 예를 들어, 검색 문서와 같은 대량의 서버 측 텍스트 임베딩은 미리 계산되어 저장되고, 사용자 쿼리와 같은 실시간 데이터는 즉시 임베딩 처리됩니다.
- 유사도 함수: 쿼리와 문서 간의 관련성은 코사인 유사도(cosine similarity)나 내적(dot product)과 같은 유사도 함수를 사용하여 계산됩니다.

- 식 (1)의 상세 설명
- 텍스트 임베딩 기반 유사도 측정은 식 (1) 으로 표현됩니다.
- sim: 쿼리 q와 문서 d 간에 계산된 최종 유사도 값을 의미합니다.
- funct 함수: 두 텍스트 임베딩 간의 유사도를 계산하는 함수입니다. 주로 코사인 유사도나 내적(dot product)이 사용됩니다.
- E(q): 사용자 쿼리 텍스트 q를 벡터 형태로 변환한 텍스트 임베딩을 나타냅니다.
- E(d): 서버에 저장된 문서 d를 벡터 형태로 변환한 텍스트 임베딩을 나타냅니다.
2.2 Privacy-preserving in NLP
- 동형암호(HE)의 기본 개념 및 NLP applications
- 동형암호는 기본적으로 숫자 데이터에 대한 연산을 지원하지만, 최근에는 [6,7] 와 같은 연구를 통해 텍스트 데이터에도 적용하려는 시도가 많아지고 있습니다.
- 그러나 이러한 연구들은 주로 텍스트 임베딩을 이용한 암호화된 분류(classification) 작업에 초점을 맞춥니다.
- 텍스트 유사도 작업에 HE 가 적합한 이유
- 분류 작업과 비교하여 텍스트 유사도 기반 서비스 시나리오(예: 검색 엔진, 챗봇)는 HE의 이점을 활용하기에 더 적합합니다.
- 이는 대량의 텍스트 임베딩이 중앙 서버에 저장되어 있고, 사용자가 민감한 정보를 포함할 수 있는 쿼리 텍스트를 서버로 보내 추론 결과를 받아야 하는 상황이기 때문입니다. HE를 사용하면 사용자의 쿼리가 서버에 노출되지 않으면서도 원하는 응답을 받을 수 있습니다.
- 다른 PPML 방식과의 비교
- Privacy- and Utility-Preserving Textual Analysis via Calibrated Multivariate Perturbations에서 제안된 dχ-privacy는 텍스트 데이터의 개인정보 보호를 위한 또 다른 방법입니다.
- 하지만 dχ-privacy는 프라이버시 매개변수 epsilon 을 매우 신중하게 선택해야 하며, 이 논문의 실험 결과에서는 성능이 낮게 나타났습니다. (성능-프라이버시 trade-off 발생)
- 반면, 이 논문에서 제안하는 CKKS (Cheon-Kim-Kim-Song) 방식 기반의 HE 는 128비트 수준의 보안을 제공하며, 비밀키 없이 정보가 유출되지 않아 실질적으로 완전한 보안을 보장합니다.
- 이전의 다른 HE 기반 연구들 [8,9] 은 CKKS 스킴이 아닌 부트스트랩(bootstrapping)을 지원하지 않는 HE 스킴을 사용했기 때문에 코사인 유사도를 직접적으로 계산하지 못하는 한계가 있었습니다.
3 Method
- 목표: 이 연구의 목표는 CKKS(Cheon-Kim-Kim-Song) 스킴을 사용하여 암호화된 텍스트 임베딩에서 텍스트 유사도 함수를 근사(approximate)하여 텍스트 데이터의 프라이버시를 보호하는 것입니다.
- sim* 함수 정의: 논문은 암호화된 유사도 함수를 구현하여 암호화된 유사도 결과를 계산합니다. 이는 원본 텍스트 임베딩을 통해 얻는 유사도 결과와 최대한 비슷하도록 근사하는 것을 목표로 합니다. 즉, 근사하여 구한 유사도 sim* 가 식 (1) 의 유사도 sim 과 최대한 유사하게 계산되도록 해야 합니다.

- 프라이버시 보호 메커니즘: 이 방법은 쿼리 텍스트 임베딩을 암호화하여 서버에 전송함으로써, 서비스 제공자를 포함한 외부 또는 내부의 악의적인 사용자가 원본 텍스트를 복구(inversion attack)하는 것을 방지합니다. 서버는 암호화된 상태에서 유사도 계산을 수행하며, 사용자만이 비밀 키를 사용하여 결과를 복호화할 수 있습니다.
3.1 Homomorphic Encryption : CKKS Scheme
- 동형 암호화(Homomorphic Encryption, HE) 기술
- 데이터를 암호화된 상태 그대로 연산(computation)할 수 있도록 지원하는 암호화 기술입니다.
- 암호화된 데이터를 가지고 계산을 수행한 후, 그 결과를 복호화하면 마치 암호화되지 않은 원본 데이터(plaintext)로 계산한 것과 동일한 결과가 나옵니다.
- 이는 특히 금융이나 헬스케어와 같이 사용자 데이터의 엄격한 프라이버시 보호가 요구되는 분야에서 서비스 제공자조차도 원본 데이터를 보지 않고 연산을 수행할 수 있게 하여 보안을 강화합니다.
- CKKS 스킴의 특징
- 본 논문에서 채택한 동형 암호화 방식은 [2] 등에서 제안된 CKKS(Cheon-Kim-Kim-Song) 스키마입니다.
- CKKS는 암호화된 실수(real-valued) 및 복소수(complex numbers) 벡터에 대한 근사(approximate) 산술 연산을 지원하는 것이 특징입니다.
- 다른 동형 암호화 스키마인 BGV(Brakerski et al., 2011)나 BFV(Fan and Vercauteren, 2012)가 주로 정수(integers)에 대한 연산을 지원하는 것과 대조됩니다.
- 실수 및 복소수 연산 지원은 실제 세계의 다양한 응용 분야에서 암호화된 계산의 **확장성(scalability)**을 제공하는 장점이 있습니다.
- 레벨드 HE(Leveled HE) 스킴과 부트스트래핑(Bootstrapping)
- CKKS는 레벨드 HE(leveled HE) 스키마입니다. 이는 암호문이 연산을 수행할 수 있는 '깊이(bounded depth)'를 가진다는 의미입니다.
- 암호화된 데이터에 대해 연산을 반복적으로 수행할수록 노이즈(noise)가 증가하게 되며, 이 노이즈가 특정 임계치를 넘으면 더 이상 정확한 연산을 할 수 없게 됩니다. 특히 두 암호문을 곱할 때마다 암호문의 '레벨(level)'이 1씩 감소하며, 이는 수행할 수 있는 남은 연산 횟수가 줄어든다는 것을 의미합니다.
- 이러한 레벨 감소 문제를 해결하기 위해 부트스트래핑(bootstrapping) 이라는 고유한 연산이 필요합니다. 부트스트래핑은 암호문을 '새로 고쳐' 암호문의 레벨을 다시 높여주어, 가능한 연산 횟수를 늘려줍니다.
- CKKS 스킴에서 지원하는 주요 동형 연산
- Add(ct1, ct2): 평문 pt1과 pt2의 덧셈(pt1 + pt2) 결과에 해당하는 암호문을 출력합니다. (slot-wise addition: 벡터의 각 요소별 덧셈)
- Mult(ct1, ct2): 평문 pt1과 pt2의 곱셈(pt1 ⊙ pt2) 결과에 해당하는 암호문을 출력합니다. (slot-wise multiplication: 벡터의 각 요소별 곱셈)
- Bootstrap(ct1): pt1의 암호문을 새로 고쳐진 레벨로 출력합니다.
- 암호문끼리의 연산 외에도 평문(plaintext)과 암호문(ciphertext)을 함께 사용하여 연산하는 것이 가능합니다. 이 경우, 두 암호문 간의 연산보다 노이즈 증가가 적다는 이점이 있어 다양한 사용자 시나리오에 유연하게 적용될 수 있습니다.
- 평문-암호문 연산의 장점
- 동형 암호화 연산은 평문(plaintext)과 암호문(ciphertext)을 함께 사용하여 수행할 수 있습니다.
- 두 개의 암호문을 연산하는 것보다 평문과 암호문을 연산할 때 노이즈(noise) 증가가 적다는 장점이 있습니다. 이러한 유연성은 보호해야 할 대상에 따라 다양한 사용자 시나리오를 고려할 수 있게 합니다.
- 코사인 유사도 근사: 이 논문에서는 관련성 점수(relevance score)로 코사인 유사도(cosine similarity)를 사용합니다. 두 벡터의 코사인 유사도는 아래와 같이 정의됩니다
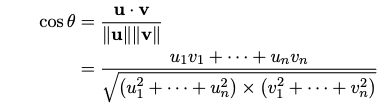
- HE는 기본적으로 덧셈(addition)과 곱셈(multiplication)만 지원합니다. 따라서 코사인 유사도 계산에 필요한 역제곱근 함수와 같은 임의의 연산은 적절한 다항식(polynomial)으로 근사해야 합니다.
- 이 논문에서는 역제곱근 함수를 암호화된 상태에서 근사하기 위해 뉴턴 방법(Newton's method)을 적용합니다. 뉴턴 방법의 반복 공식은 아래와 같습니다:

- 보안성
- 이 논문에서 제안하는 HE 방법은 128-bit 보안 수준을 보장합니다. 이는 현재까지 알려진 최상의 알고리즘으로 암호문(ciphertext)으로부터 평문(plaintext)을 복구하려면 2^{128} 번의 연산이 필요하다는 것을 의미합니다.
- 따라서 동형 암호화된 암호문은 비밀 키(secret key)에 대한 접근 없이는 안전하게 보호되며 정보가 노출되지 않습니다.
- 이러한 보안 메커니즘은 [2,10] 와 같은 이전 연구의 기반 위에 구축되었습니다.

Inference
- HE 기반 유사도 추론 워크플로우 (Procedure 1)
- 클라이언트의 키 생성: 사용자는 HE를 위한 공개키(Public Key, pk)와 비밀키(Secret Key, sk)를 생성합니다.
- 쿼리 암호화: 사용자가 입력한 쿼리 텍스트는 먼저 텍스트 임베딩으로 변환된 후, 생성된 공개키를 사용하여 암호화됩니다
- 암호화된 쿼리 전송: 암호화된 쿼리 임베딩은 서버로 전송됩니다. 이 단계에서 데이터가 암호화되어 있기 때문에 (a) 외부의 악의적인 사용자가 원본 쿼리 데이터에 접근하여 정보를 탈취하는 것을 방지합니다.
- 서버 측 유사도 추론: 서버는 클라이언트로부터 받은 암호화된 쿼리 임베딩과 미리 계산된 문서 임베딩을 활용하여 유사도 함수 funct* 를 실행합니다. 이때 서버는 암호화된 데이터를 복호화하지 않고도 계산을 수행하며, 이는 사용자의 비밀키를 서버가 소유하고 있지 않으므로 (b) 서비스 제공자를 포함한 내부의 악의적인 사용자로부터도 원본 데이터가 안전함을 의미합니다.
- 암호화된 결과 전송: 서버는 계산된 암호화된 유사도 결과 sim* 를 클라이언트에게 다시 보냅니다.
- 클라이언트의 결과 복호화 및 인덱스 식별: 클라이언트는 자신의 비밀키를 사용하여 서버로부터 받은 암호화된 유사도 결과를 복호화하고, 이 복호화된 결과 sim 에서 가장 관련성이 높은 문서의 인덱스 argmax(sim) 를 식별합니다.
- 문서 요청 및 전달: 클라이언트는 식별된 인덱스를 서버로 보내고, 서버는 해당 인덱스의 문서를 클라이언트에게 전달합니다.
- 가장 관련성 높은 문서 인덱스 유출 우려 및 해결책
- 우려: 클라이언트가 최종적으로 가장 관련성이 높은 문서의 인덱스를 식별한 후, 이 인덱스를 서버에 다시 보내 해당 문서를 요청할 때, 이 인덱스 자체가 쿼리에 대한 민감한 정보를 암시할 수 있다는 우려가 있습니다. 예를 들어, 특정 인덱스가 매우 민감한 내용의 문서와 연결되어 있다면, 서버는 해당 인덱스가 요청되었다는 사실만으로도 사용자의 쿼리 내용을 유추할 수 있습니다.
- 해결책: 이러한 우려를 해소하기 위해 논문에서는 클라이언트가 실제 타겟 인덱스 외에 여러 개의 무작위 인덱스들을 함께 서버로 보낼 것을 제안합니다. 이렇게 하면 서버는 클라이언트가 요청하는 여러 인덱스 중 어느 것이 실제 쿼리와 가장 관련 있는 문서에 해당하는지 알 수 없으므로, 쿼리에 대한 정보 유출 위험을 효과적으로 줄일 수 있습니다.
- 추가적인 고려사항
- 이 논문의 Limitations 섹션에 언급된 바와 같이, 암호화된 상태에서의 연산은 여전히 계산 비용이 높다는 한계가 있습니다. 예를 들어, 벡터-벡터 곱셈에는 평균 30~40ms, 1,000개의 문서에 대한 벡터-행렬 곱셈에는 평균 0.6~0.7초가 소요됩니다. 이는 대규모 말뭉치(예: 수백만 개의 문서를 포함하는 Wikipedia)에 대한 실시간 검색 서비스에 적용하기 위해서는 효율성 개선이 필요함을 시사합니다.
- 또한, 현재의 HE 구현은 코사인 유사도와 같은 비교적 간단한 유사도 함수에 초점을 맞추고 있어, FAISS와 같은 기존의 근사 검색 프레임워크나 해싱, 그래프 기반 검색과 같이 복잡한 데이터 구조 및 연산을 활용하는 기술들과 직접 통합하기 어렵다는 점도 중요한 과제입니다. 이러한 한계점들은 향후 연구를 통해 HE 기반의 효율적인 검색 방법을 개발해야 할 필요성을 제기합니다.
Security
- 128비트 보안 수준: 이는 암호화된 데이터(ciphertext)에서 원문(plaintext)을 복구하는 데 현재까지 알려진 가장 효과적인 알고리즘으로도 2^{128} 번의 연산이 필요하다는 것을 의미합니다. 이러한 수준의 보안은 [10] 에서 제시된 HE 파라미터가 보장하는 수준입니다.
- 완전한 보호: 따라서 동형 암호화된 암호문은 복호화에 필요한 비밀키(secret key) 없이는 절대 정보가 노출되지 않아 안전하게 보호됩니다. 이는 서비스 제공자를 포함한 어떤 악의적인 사용자로부터도 사용자 데이터를 보호할 수 있게 합니다.
4 Experiments
4.1 Text Similarity Tasks (STS, Text Retrieval)
Task: STS (Semantic textual similarity)
- 목표: 모델이 두 텍스트가 얼마나 유사한 의미를 갖는지 판단하는 능력을 평가합니다.
- 평가 방식: 사람이 직접 판단한 '실제(ground truth) 레이블'과 모델이 예측한 '유사성 점수' 사이의 상관관계를 측정합니다. 즉, 모델의 예측이 사람의 판단과 얼마나 일치하는지를 확인합니다.
- 사용 데이터셋: 7가지 잘 알려진 의미론적 텍스트 유사성 데이터셋을 사용합니다.
- STS 2012–2016
- STS Benchmark
- SICK-Relatedness
- 각 데이터셋은 텍스트 쌍과 이 텍스트 쌍의 의미적 관련성을 나타내는 실제(ground truth) 레이블을 포함하고 있습니다.
- 유사성 계산: 모델은 텍스트를 임베딩(text embeddings)으로 변환한 후, 이 임베딩들 사이의 코사인 유사성(cosine similarity)을 계산하여 유사성 점수를 얻습니다.
- 상관관계 측정 도구: 계산된 유사성 점수와 실제(ground truth) 레이블 간의 상관관계를 측정하기 위해 SentEval toolkit 의 Spearman’s correlation 평가 스크립트를 사용합니다
Task: Text Retrieval
- 목표: 쿼리(질의)와 문서(documents) 간의 관련성 점수를 계산하여 문서를 정렬하고, 올바른 문서의 순위(rank)를 기반으로 텍스트 검색 품질을 평가하는 것입니다.
- 점수 계산: 쿼리와 문서 간의 관련성 점수는 dot product(내적)을 사용하여 계산됩니다.
- 평가 방식: 최신 연구(Condenser, ColBERTv2 등)를 따라 BEIR 벤치마크(BEIR)를 사용하여 텍스트 임베딩 모델의 zero-shot retrieval 성능을 평가합니다. Zero-shot retrieval은 사전학습된 모델이 fine-tuning 없이 학습되지 않은 새로운 데이터셋에서도 직접 검색 성능을 평가하는 것을 의미합니다.
- 데이터셋
- FiQA-2018
- NFCorpus
- ArguAna
- SCIDOCS
- SciFact
- 이 데이터셋들은 각각 특정 도메인(domain-specific)의 텍스트 데이터를 포함하고 있습니다. 예를 들어, FiQA-2018은 금융 검색 쿼리로 구성되어 있으며, 이는 개인 정보 보호에 민감한 텍스트의 대표적인 예시입니다.
Pre-trained Text Embedding Models
- 추가적인 파인 튜닝(fine-tuning) 없이 공개적으로 사용 가능한 사전 학습된(pre-trained) 텍스트 임베딩 모델을 사용했습니다.
- SimCSE / DistilBERT: 이 두 모델은 텍스트를 벡터 공간의 임베딩으로 변환하는 데 사용되는 백본 모델(backbone models) 입니다. 백본 모델은 특정 작업(여기서는 텍스트 유사성 추론)을 수행하기 위한 기반이 되는 주된 모델을 의미합니다.
- SimCSE: STS(Semantic Textual Similarity, 의미론적 텍스트 유사성) 작업에 사용되었습니다.
- DistilBERT: 텍스트 검색(Text Retrieval) 작업에 사용되었습니다. BERT 의 경량화된 버전으로, 더 빠르고 효율적이면서도 BERT와 유사한 성능을 낼 수 있도록 고안되었습니다.
4.2 Privacy-Preserving Baseline
- Plaintext
- 정의: 이 논문에서 "Plaintext"는 개인 정보 보호(privacy-preserving) 기술을 적용하지 않은 일반 텍스트 임베딩(text embedding)의 결과를 의미합니다.
- 기준점: 이는 논문에서 제안하는 동형 암호(Homomorphic Encryption, HE) 기반 방법이나 다른 프라이버시 보호 기준선(dχ-privacy 등)과 비교하기 위한 성능의 기준선(baseline) 또는 참조점(reference point) 으로 사용됩니다.
- 성능 비교 대상: "Plaintext"의 결과는 프라이버시 보호가 적용된 방법들이 원본 정보 노출을 막으면서도 얼마나 정확하게 원래의 모델 성능을 유지하는지를 평가하는 데 사용됩니다. 즉, 프라이버시 보호 방법의 목표는 "Plaintext"의 성능을 최대한 가깝게 모방하는 것입니다.
- 프라이버시 위험: "Plaintext" 상태의 텍스트 임베딩은 역공격(inversion attacks)을 통해 원본 텍스트로 복구될 수 있는 프라이버시 위험을 내포하고 있습니다. 이 논문은 이러한 위험을 "Plaintext" 임베딩에서 증명하고, 이를 방지하기 위한 HE 기반 솔루션을 제시합니다.
- dχ-privacy (Local Differential Privacy)
- 개념 및 목표
- dχ-privacy는 텍스트 임베딩에서 발생할 수 있는 정보 유출(information leakage)을 방지하는 것을 목표로 합니다.
- 이는 사용자의 민감한 데이터가 서비스 제공자를 포함한 잠재적 악의적인 사용자에게 노출되는 것을 막기 위함입니다.
- 작동 원리 (노이즈 주입)
- 주어진 임베딩 x 에 샘플링된 노이즈 N 을 더하여 프라이버시가 보호된 임베딩 P(x) 를 생성합니다.
- 수식으로 표현하면 다음과 같습니다: P(x) = x + N, where N = rp
- η 파라미터의 역할
- η 값은 노이즈 수준을 나타내는 중요한 파라미터입니다.
- η 값이 낮을수록 임베딩에 더 많은 노이즈가 추가됩니다.
- Privacy-Utility Trade-off
- 낮은 η: 노이즈 수준이 높아져 프라이버시 보호는 강화되지만, 원래 임베딩 정보가 많이 손실되어 모델 성능이 저하될 수 있습니다.
- 높은 η: 노이즈 수준이 낮아져 프라이버시 보호는 약화되지만, 모델 성능은 Plaintext 와 비교하여 비교적 잘 유지됩니다.
- 개념 및 목표
4.3 Text Embedding Inversion

- 역변환 공격의 유형 [1]
- White-box inversion: 공격자가 임베딩 모델 자체에 접근할 수 있다고 가정하는 공격입니다.
- Black-box inversion: 공격자가 모델에는 접근할 수 없고 오직 텍스트 임베딩에만 접근할 수 있다고 가정하는 공격입니다. 이 논문에서는 서비스 제공자가 미리 계산된 임베딩을 활용하는 시나리오에서 개인 정보 보호 문제를 다루기 때문에, 공격자가 임베딩만 접근 가능한 'black-box inversion' 방식을 선택하여 연구합니다.
- Black-box inversion 작동 방식
- 핵심 아이디어는 텍스트 임베딩을 입력으로 받아 원래 텍스트의 단어를 예측하는 '다중 레이블 분류기(multi-label classifier)'를 훈련시키는 것입니다.
- 이 분류기는 역변환 모델이라고 불리며, 주어진 임베딩으로부터 원본 텍스트에 포함된 단어들을 예측하는 확률을 최대화하도록 학습됩니다.
- 역변환 모델 Training Objective
- 역변환 모델 phi 를 학습하기 위해 다음 로그-우도(log-likelihood) 함수를 최대화합니다.
- 역변환 모델 phi 가 임베딩 E(s) 가 주어졌을 때, 해당 임베딩으로부터 단어 w 를 성공적으로 예측할 확률을 나타냅니다.
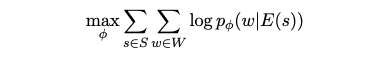
- 구현 및 실험 설정
- 역변환 모델로는 간단한 1-layer MLP(다층 퍼셉트론)를 사용했습니다.
- 훈련 데이터는 BookCorpus 에서 샘플링한 문장들과 벤치마크 데이터셋의 훈련 스플릿 텍스트를 사용했습니다.
- 검증 데이터는 BookCorpus 와 벤치마크 데이터셋의 개발 스플릿을 사용하여 최적의 임계값(threshold)과 체크포인트를 선택했습니다.
- 실험 결과 (Table 2 참조)
- 원본 텍스트 복구 가능성: 역변환 모델은 암호화되지 않은(Plaintext) 임베딩에서 원래 텍스트의 단어를 성공적으로 추출할 수 있음을 확인했습니다.
- 성능 제한: 그러나 대부분의 경우 일반적인 분류 작업에 비해 F1 점수가 0.5점 미만으로 낮게 나타났습니다 (FIQA-2018 및 SciFact 제외). 이는 약 20,000개의 단어(어휘 크기)를 분류해야 하는 "extreme multi-label classification" 작업의 특성 때문입니다.
- 데이터셋별 성능 차이
- ArguAna 검색 데이터셋에서는 다른 데이터셋보다 성능이 가장 낮았습니다. 이는 ArguAna가 다른 데이터셋보다 검색 질의의 길이가 훨씬 길기 때문입니다.
- STS(Semantic Textual Similarity) 데이터셋에서는 텍스트 검색 데이터셋보다 전반적인 성능이 낮았는데, 이는 데이터셋의 도메인 차이(일반 문장 vs. 다양한 도메인의 검색 질의)와 사용된 텍스트 임베딩 모델(SimCSE vs. DistilBERT)의 차이 때문일 수 있습니다.
- dχ-privacy와의 비교
- dχ-privacy와 같은 노이즈 기반 개인 정보 보호 방식은 노이즈가 증가할수록 추출되는 원본 정보의 양이 줄어들지만, 여전히 정보 유출이 발생할 수 있음을 보여줍니다 (Table 4의 Qualitative Analysis 참조).
- HE(동형 암호)의 완전한 보안: 본 논문의 HE(Homomorphic Encryption) 접근 방식은 테스트에 포함되지 않았는데, 이는 섹션 3.1에서 설명했듯이 "완전한 보안"을 제공하여 원본 정보를 복구할 수 없기 때문입니다.

- Qualitative Analysis 목표
- 텍스트 임베딩이 역변환 공격에 얼마나 취약한지, 즉 임베딩만으로 원본 텍스트 정보를 얼마나 추출할 수 있는지 보여줍니다.
- dχ-privacy와 같은 노이즈 기반 개인 정보 보호 방식이 이러한 공격을 얼마나 효과적으로 방어하는지 평가합니다.
- Qualitative Analysis 방법 (Table 4)
- 예시 텍스트: FIQA-2018 및 STS-B 데이터셋에서 두 가지 텍스트 예시를 선정했습니다.
- 추출 단어 수: 각 텍스트 임베딩에서 역변환 모델이 예측한 단어 중 가장 가능성이 높은 상위 6개 단어를 순서대로 나열했습니다. 이는 Table 3에서 대부분의 데이터셋의 평균 단어 수가 약 6개임을 고려한 것입니다.
- 역변환 모델: 간단한 1계층 MLP(Multi-Layer Perceptron) 모델을 사용하여 텍스트 임베딩을 입력받아 원본 텍스트의 단어들을 예측하도록 훈련했습니다.
- FIQA-2018 데이터셋 예시 분석 (원본 텍스트: "15 year mortgage vs 30 year paid off in 15")
- Plaintext (평문) 임베딩: vs, year, mortgag, 30, paid, 15와 같이 원본 텍스트의 의미론적 정보를 정확하게 나타내는 단어들을 성공적으로 추출했으며, 잘못 예측된 단어(false positive)는 없었습니다.
- 최소 노이즈 (η = 175): 임베딩에 노이즈를 추가하자 mortgag이 loan으로, paid가 pay로 바뀌는 등 의미적으로 관련은 있지만 원본과 다른 단어들이 추출되기 시작하며 혼동을 보였습니다.
- 최고 노이즈 (η = 50): 노이즈 수준이 가장 높은 경우, common, hunch와 같이 원본 텍스트와 전혀 관련 없는 단어들이 추출되기 시작했습니다. 이는 노이즈가 많을수록 원본 정보가 크게 손상되어 모델이 정확한 예측을 하지 못함을 의미합니다.
- STS-B 데이터셋 예시 분석 (원본 텍스트: "a man is singing and playing a guitar"):
- Plaintext (평문) 임베딩: guitar, sing, man, play와 같이 중요한 단어들을 모두 성공적으로 추출했으며, fluid라는 오탐 단어가 하나 포함되었습니다.
- 최고 노이즈 (η = 50): 노이즈를 최대로 주입한 경우, 모델은 임계값(threshold)에 따라 필터링된 후 어떤 단어도 추출하지 못했습니다. 이는 높은 수준의 노이즈가 원본 정보 유출을 효과적으로 차단할 수 있음을 보여줍니다.
- dχ-privacy의 한계: 이러한 Qualitative Analysis 결과는 dχ-privacy 방법이 임베딩 역변환 공격을 "완전히" 방지하기에는 불충분하며, 단지 완화하는 데에 그친다는 것을 보여줍니다.
4.4 Text Similarity Evaluation
Implementation
- CKKS 스킴과 RNS
- 이 논문에서는 CKKS 라는 동형 암호 스킴을 사용했습니다. CKKS는 실수 및 복소수에 대한 근사 연산을 지원하는 특징이 있어 실제 세계의 다양한 애플리케이션에 적용하기 용이합니다.
- RNS(Residual Number System, 나머지 시스템)는 CKKS 스킴의 효율적인 구현을 위한 기술입니다. 이는 암호화된 데이터에 대한 연산을 더욱 빠르고 효율적으로 수행할 수 있도록 돕습니다.
- GPU 기반 부트스트래핑
- 동형 암호는 연산을 수행할수록 암호문에 노이즈가 축적되어 연산 가능한 횟수가 제한됩니다. '부트스트래핑(bootstrapping)'은 이 노이즈를 줄여 암호문을 "새로 고쳐" 더 많은 연산을 가능하게 하는 핵심 기술입니다.
- GPU(그래픽 처리 장치)를 활용하여 이 부트스트래핑 과정을 가속화함으로써, 복잡한 암호화 연산의 계산 시간을 단축시킵니다.
- 제곱근 역수 근사
- 코사인 유사도(cosine similarity)는 두 벡터의 내적을 각 벡터의 길이(노름, norm)의 곱으로 나눈 값입니다.
- 동형 암호는 기본적으로 덧셈과 곱셈만 지원하므로, 위 수식의 분모에 있는 제곱근 연산을 직접 수행할 수 없습니다. 따라서 논문에서는 뉴턴 방법(Newton's method)을 사용하여 제곱근 역수를 다항식으로 근사하여 계산했습니다.
- 유사도 계산 방식
- STS(Semantic Textual Similarity) 태스크에서는 텍스트 임베딩 간의 벡터-벡터 곱셈을 통해 코사인 유사도를 계산합니다.
- 텍스트 검색(Text Retrieval) 태스크에서는 벡터-행렬 곱셈을 통해 내적(dot product)을 계산합니다. 이는 쿼리 임베딩과 다수의 문서 임베딩 간의 유사도를 동시에 계산할 때 효율적입니다.
- 암호화 범위
- 텍스트 검색 시에는 서버에 저장된 문서들은 일반적으로 공개되어 있다고 가정하여 암호화하지 않고, 사용자 쿼리 텍스트 임베딩만 암호화하여 전송합니다. 이를 통해 사용자의 민감한 쿼리 정보가 서버에 노출되는 것을 방지합니다.
- 동형 암호의 덧셈 및 곱셈 지원 덕분에 코사인 유사도뿐만 아니라 내적과 같은 다른 유사도 함수들도 암호화된 상태에서 쉽게 구현할 수 있습니다.
Semantic Textual Similarity

- STS(Semantic Textual Similarity) 태스크
- 주어진 텍스트 쌍의 의미론적 유사도를 추론하는 능력을 평가하는 태스크입니다
- 이 논문에서는 인간이 판단한 Ground Truth 레이블과 모델이 예측한 유사도 점수 간의 상관관계를 측정합니다.
- 평가 지표: Spearman's correlation score를 사용하여 성능을 평가합니다. 이 점수는 두 변수(여기서는 Ground Truth와 모델 예측 유사도) 사이의 순위 상관관계를 나타냅니다.
- 세 가지 method 비교
- Plaintext: 개인 정보 보호 기법이 적용되지 않은 일반적인 텍스트 임베딩 결과입니다. 이는 다른 개인 정보 보호 기법들이 목표로 해야 할 성능의 기준점(baseline)이 됩니다.
- dχ-privacy
- 노이즈 주입을 통해 텍스트 임베딩의 정보 유출을 막는 방법입니다. η 값은 노이즈 수준을 나타내며, η 값이 낮을수록 더 많은 노이즈가 주입되어 개인 정보 보호 수준은 높아지지만 성능 저하가 발생할 수 있습니다 (예: η = 175는 낮은 노이즈, η = 50은 높은 노이즈).
- η = 175일 때, dχ-privacy는 Plaintext 성능에서 평균적으로 약 10%의 성능 손실을 보입니다. STS-12 데이터셋에서 가장 큰 폭(75.2961809 → 51.7546246)으로 떨어지는 것을 확인할 수 있습니다.
- 노이즈 수준이 가장 높은 η = 50일 때는 평균 상관관계 점수가 Plaintext의 절반 수준(81.5561381 → 41.1161135)으로 크게 하락합니다. 이는 노이즈가 많을수록 임베딩 표현이 심하게 붕괴되어 성능이 저하됨을 의미합니다.
- HE (Ours)
- 본 논문에서 제안하는 동형 암호(Homomorphic Encryption) 기반 방법입니다.
- HE 방법은 Plaintext의 성능을 거의 완벽하게 보존합니다. Plaintext와 비교했을 때, 대부분의 경우 10^{-5} 점 미만의 매우 작은 차이(최대 STS-15에서 0.0000049점)를 보입니다.
- STS-12, STS-14, STS-B, SICK-R 데이터셋에서는 오히려 점수가 약간 증가하는 현상도 관찰되었습니다. 이는 암호화 과정에서 발생하는 미세한 노이즈가 점수 계산에 긍정적인 영향을 미칠 수 있기 때문이라고 설명합니다.
- 평균적으로 Plaintext와 HE 방법은 10^{-3} 점 미만의 차이로 거의 동일한 점수를 보입니다.
Plaintext 코사인 유사도 점수와 암호화된 코사인 유사도 점수 간의 평균 절대 편차(average absolute deviation)는 STS15에서 가장 낮은 3.89 × 10^{-8}, STS12에서 가장 높은 5.08 × 10^{-8}로 매우 작습니다.
- 결론: dχ-privacy와 같은 노이즈 기반 방법은 개인 정보 보호를 위해 성능 저하를 감수해야 하지만, 본 논문의 HE 기반 접근 방식은 성능 저하 없이 완전한 개인 정보 보호를 달성할 수 있음을 실험적으로 증명합니다.
Text Retrieval
- dχ-privacy
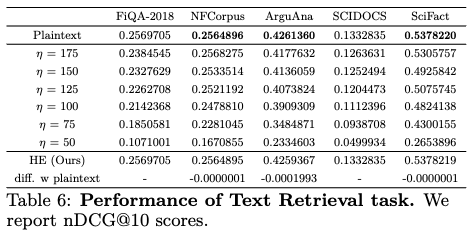
- Table 6에 제시된 텍스트 검색 데이터셋(FiQA-2018, NFCorpus, ArguAna, SCIDOCS, SciFact)에 대한 실험 결과에 따르면, dχ-privacy 방식은 STS(Semantic Textual Similarity) 데이터셋과 달리 비교적 견고한 성능을 보였습니다.
- 대부분의 데이터셋에서 성능 저하가 5% 미만이었으며(FiQA-2018 제외), 노이즈를 더 추가하더라도 10% 미만의 적은 저하를 유지했습니다.
- 그러나 가장 높은 노이즈 레벨(η=50)에서는 원래 점수의 50% 미만으로 점수가 떨어지는 모습을 보였습니다.
- Homomorphic Encryption (HE)
- HE 방식은 STS 결과와 마찬가지로 텍스트 검색에서도 plaintext(개인 정보 보호 기법을 적용하지 않은 원본)와 거의 동일한 성능을 유지했습니다.
- ArguAna 데이터셋에서 최대 0.0001993점의 미미한 성능 저하만을 보였습니다.
- plaintext와 암호화된 상태에서의 내적(dot-product) 간의 평균 절대 편차는 매우 작았습니다.
- 평가 지표에 따른 성능 차이
- 연구진은 dχ-privacy 방식이 STS와 텍스트 검색에서 다른 성능 양상을 보이는 것이 평가 지표의 특성에서 비롯된다고 설명합니다.
- Spearman's correlation: STS 데이터셋에 사용되는 이 지표는 실제 값과 예측 값 간의 유사성(상관 관계)을 측정하므로, dχ-privacy가 추가하는 작은 노이즈라도 최종 상관 점수에 직접적인 영향을 미쳐 성능 저하가 컸습니다.
- nDCG (Normalized Discounted Cumulative Gain): 텍스트 검색에 사용되는 이 지표는 검색 결과 문서의 순위에 기반하여 측정됩니다. dχ-privacy가 노이즈를 추가하여 관련성 점수 자체는 변경되더라도, 문서들의 상대적인 순위가 크게 변하지 않는다면 nDCG 점수에는 큰 영향이 없을 수 있습니다. 이것이 dχ-privacy 방식이 텍스트 검색에서 비교적 견고한 성능을 보인 이유입니다.
5 Conclusions
- 제안된 방법론의 효과: 이 논문에서는 동형 암호 기반 텍스트 유사성 추론 방법을 제안했습니다. 이 방법을 통해 사용자는 원본 텍스트를 노출하지 않고도 텍스트 임베딩 기반 서비스를 이용할 수 있습니다.
- 이는 실험 4.3에서 입증된 바와 같이, 원본 텍스트가 역공격(inversion attack)을 통해 복구될 수 있는 잠재적 위험으로부터 사용자의 프라이버시를 보호합니다.
- 성능 검증
- 광범위한 실험(4.4)을 통해 제안된 동형 암호 기반 접근 방식이 모델의 성능을 저하시키지 않음을 입증했습니다.
- 반면, 비교 대상인 dχ-privacy 방식은 성능 저하 없이 역공격을 방지하는 데 실패했습니다. 이는 이 논문에서 제안하는 동형 암호 방식이 기존의 다른 프라이버시 보존 방식들보다 텍스트 유사성 추론 태스크에서 더 효과적임을 시사합니다.
- 결론: 이 연구는 금융 및 의료와 같이 프라이버시 보호가 엄격하게 요구되는 산업에서 텍스트 임베딩을 안전하게 사용하는 데 중요한 기반을 마련했습니다.
Limitations
- 높은 계산 비용: 암호화된 상태에서 연산을 수행하는 동형 암호의 특성상 계산 비용이 많이 듭니다.
- STS (Semantic Textual Similarity) 작업: 텍스트 간의 의미론적 유사성을 측정하는 작업으로, 벡터-벡터 곱셈(vector-vector multiplication)에 텍스트당 평균 약 30~40밀리초(ms)가 소요됩니다.
- 텍스트 검색 (Text Retrieval) 작업: 질의(query)와 다수의 문서 간의 유사도를 계산하는 작업으로, 1,000개 문서에 대해 질의당 벡터-행렬 곱셈(vector-matrix multiplication)에 평균 약 0.6~0.7초가 소요됩니다.
- 문서 수가 증가함에 따라 계산 시간이 선형적으로 증가하기 때문에, 대규모 코퍼스(corpus)에 대한 문서 검색 서비스를 실용적으로 제공하기 위해서는 연산 효율성 개선이 필수적입니다.
- 기존 검색 프레임워크와의 통합 어려움
- 최신 애플리케이션들은 효율적인 텍스트 임베딩 유사도 검색을 위해 Faiss 와 같은 근사 검색(approximate search) 프레임워크를 활용합니다. 이는 특히 위키피디아와 같이 5백만 개 이상의 문서가 있는 대규모 오픈 도메인 검색 코퍼스를 다룰 때 매우 중요합니다.
- 이 논문에서 구현한 동형 암호는 코사인 유사도(cosine similarity)와 같은 비교적 단순한 유사도 함수에 초점을 맞추고 있습니다. 따라서 해싱(hashing)이나 그래프 기반(graph-based) 검색과 같은 복잡한 데이터 구조 및 연산을 사용하는 기존 프레임워크 (e.g., Faiss) 및 알고리즘에 직접 통합하기 어렵습니다.
- 연산 방식의 근본적인 차이
- 동형 암호(HE): 이 논문에서 사용하는 CKKS 스킴(scheme)과 같은 동형 암호는 암호화된 상태에서 덧셈(addition)과 곱셈(multiplication)과 같은 단순한 산술 연산만 직접적으로 지원합니다. 다른 복잡한 연산(예: 나눗셈, 제곱근, 비교 등)은 다항식 근사(polynomial approximation)를 사용하거나 반복적인 계산을 통해 간접적으로 수행해야 합니다.
- 근사 검색 프레임워크 (예: Faiss): Faiss 는 효율적인 대규모 검색을 위해 해싱(hashing), 트리(tree), 그래프(graph) 기반 인덱스(index)와 같은 복잡한 데이터 구조와 연산을 활용합니다. 예를 들어, K-평균 군집화(K-means clustering)를 통한 인덱스 생성, K-NN 그래프(K-Nearest Neighbor graph) 탐색, 또는 양자화(quantization)를 위한 비트 연산(bitwise operation) 등이 포함됩니다.
- 이러한 연산들은 단순한 덧셈이나 곱셈으로 직접 표현하기 어렵고, 조건부 분기(conditional branching)나 메모리 접근 패턴이 복잡하여 암호화된 상태에서 효율적으로 수행하기가 매우 까다롭습니다.
- 정보 흐름 및 노이즈 관리의 복잡성
- 근사 검색 알고리즘은 검색 과정에서 데이터의 특정 속성(예: 해시 값, 거리 값)을 기반으로 판단을 내리고 탐색 경로를 결정합니다. 이 과정에서 암호화된 데이터를 기반으로 이러한 판단을 내리려면, 그 판단 자체가 암호화된 상태에서 이루어져야 합니다.
- 복잡한 알고리즘은 많은 수의 곱셈 연산을 포함하게 되는데, 동형 암호에서는 곱셈 연산마다 암호문에 노이즈(noise)가 증가합니다.
- 노이즈가 특정 한계를 넘어서면 복호화(decryption)가 불가능해지므로, "부트스트래핑(bootstrapping)"이라는 노이즈 제거 작업을 수행해야 합니다. 이 부트스트래핑은 계산 비용이 매우 비싸기 때문에, 복잡한 검색 알고리즘에 적용하면 전반적인 성능이 크게 저하될 수 있습니다.
- 이러한 한계를 해결하기 위해 논문에서는 동형 암호 기반의 효율적인 검색 방법 구현에 대한 연구를 향후 과제로 제시하고 있습니다.
Reference
[1] Information leakage in embedding models
[2] Homomorphic encryption for arithmetic of approximate numbers.
[3] A survey on homomorphic encryption schemes: Theory and implementation.
[4] Natural language understanding with privacy-preserving bert.
[5] Dense Passage Retrieval for Open-Domain Question Answering
[6] Privacy-preserving text classification on BERT embeddings with homomorphic encryption
[7] THE-X: Privacy-preserving transformer inference with homomorphic encryption
[8] Vector based privacy-preserving document similarity with lsa
[9] Homomorphic encryption for speaker recognition: Protection of biometric templates and vendor model parameters.
[10] Practical FHE parameters against lattice attacks