
HETAL: Efficient Privacy-preserving Transfer Learning with Homomorphic Encryption (ICML 2023)
Seewoo Lee, Garam Lee, Jung Woo Kim, Junbum Shin, Mun-Kyu Lee
Abstact
- 전이 학습 (Transfer Learning, TL) 의 배경 및 문제점
- 전이 학습은 데이터가 부족한 문제에 대해 효율적으로 기계 학습 모델을 훈련하기 위한 표준적인(de facto standard) 방법.
- 이는 대규모 데이터셋으로 사전 훈련된 모델에 새로운 분류 레이어를 추가하고 미세 조정(fine-tuning)하는 방식입니다.
- 기존에는 동형암호를 사용하여 전이 학습 환경에서 데이터 개인 정보 문제를 해결하려는 시도가 많았지만, 대부분 암호화된 추론(inference)에만 초점을 맞췄습니다.
- HETAL의 목표 및 해결책
- HETAL은 서비스형 머신러닝(MLaaS) 환경에서 클라이언트의 훈련 데이터 개인 정보를 보호하는 것을 목표로 합니다.
- 이를 위해 클라이언트 데이터를 CKKS 동형암호 스키마(Homomorphic Encryption Scheme)를 사용하여 암호화합니다.
- HETAL의 주요 특징
- 실용적인 암호화된 훈련: HETAL은 암호화된 훈련(encrypted training)을 엄격하게 제공하는 최초의 실용적인 스키마입니다.
- 검증 기반 조기 중단(validation-based early stopping): 비암호화된 훈련과 동일한 정확도를 달성하면서 과적합(overfitting)을 방지하기 위해 검증 기반 조기 중단 기법을 채택합니다.
- 효율적인 암호화된 행렬 곱셈 알고리즘: 기존 방법보다 1.8배에서 323배 빠른 효율적인 암호화된 행렬 곱셈 알고리즘을 제안합니다.
- 소프트맥스(Softmax) 근사 알고리즘: 적용 범위가 확장된 고정밀 소프트맥스 근사 알고리즘을 제안합니다.
- Performance: 5가지 잘 알려진 벤치마크 데이터셋에 대한 실험 결과, 총 훈련 시간은 567초에서 3442초(1시간 이내)로 나타났습니다.
- 연구의 진전
- HETAL은 기존의 동형암호 기반 전이 학습 연구들이 주로 암호화된 추론 (inference) 에 집중했던 한계를 넘어, 암호화된 훈련 (Encryted Training) 자체를 실용적인 수준으로 구현했다는 점에서 큰 진전을 보여줍니다.
- 특히, 훈련 과정에서 필수적인 검증 기반 조기 중단 기법을 동형암호 환경에서 성공적으로 적용하고, 기존 대비 현저히 빠른 행렬 곱셈 알고리즘과 더 넓은 범위에서 정밀한 소프트맥스 근사를 가능하게 함으로써 실제 서비스에 적용될 수 있는 수준의 효율성과 정확성을 달성했습니다.
- 이는 프라이버시 보존 머신러닝 분야에서 동형암호의 적용 가능성을 크게 확장한 것으로 평가할 수 있습니다.
1. Introduction
- 전이 학습 (Transfer Learning, TL)
- 전이 학습은 대규모 데이터셋으로 사전 학습된(pre-trained) 일반 모델에 새로운 분류 레이어(classification layer)를 추가하고 미세 조정(fine-tuning)하여, 데이터가 부족한 문제에 대해 효율적으로 기계 학습 모델을 훈련하는 방법입니다.
- MLaaS 설정에서 서버는 클라이언트(데이터 소유자)에게 사전 학습된 모델에 대한 접근 권한을 부여하여 특징(features)을 추출하게 하고, 클라이언트는 추출된 특징을 서버로 전송하여 미세 조정을 수행 (e.g., Cloud cumputing)합니다.
- 데이터 유출 문제
- 민감한 클라이언트 데이터가 서버에 유출될 수 있는데, 이는 특징 추출 과정에서 생성된 특징 벡터(feature vector)가 원본 데이터에 대한 상당한 정보를 포함할 수 있기 때문입니다.
- 얼굴 이미지 재구성: 예를 들어, 얼굴 이미지는 특징 벡터로부터 재구성될 수 있음이 잘 알려져 있습니다 (Mai et al., 2019). 최신 얼굴 인식 시스템인 ArcFace나 ElasticFace조차도 특징 역추적 공격(feature reversion attacks)에 취약합니다.
- NLP 데이터 재구성: 자연어 처리(NLP) 분야에서는 BERT 임베딩(embeddings)이 그 의미론적 풍부함(semantic richness) 때문에 원본 입력 단어의 50~70%까지 복구될 수 있음이 입증되었습니다 (Song & Raghunathan, 2020).
- 이러한 특징 역추적 공격은 신경망 기반 시스템에 심각한 위협을 가합니다.
- 개인정보 보호의 중요성
- 따라서 클라이언트의 사적 데이터를 보호하기 위해 전송되는 특징을 보호하는 방법은 매우 중요합니다.
- 데이터 개인정보 보호는 전 세계적인 관심사가 되었으며, EU의 일반 데이터 보호 규정(GDPR) (EU, 2016)과 같이 많은 국가에서 개인정보 보호법을 제정하고 있습니다.
- 프라이버시 보호 머신러닝 (Privacy-Preserving Machine Learning, PPML)
- Secure Multi-Party Computation (SMPC)
- 여러 당사자가 자신의 원본 데이터를 노출하지 않고 공동으로 계산을 수행할 수 있도록 하는 암호화 기술입니다.
- 장점: 데이터를 직접 공유하지 않아도 공동 계산이 가능하므로 프라이버시를 강력하게 보호합니다.
- 단점: 클라이언트와 서버 간에 상당한 양의 통신이 필요하여 효율성이 저하될 수 있습니다.
- 차등 프라이버시 (Differential Privacy, DP)
- 데이터에 노이즈를 추가하여 개별 데이터 포인트의 존재 여부가 결과에 미치는 영향을 최소화하는 프라이버시 보호 기술입니다.
- 장점: 강력한 수학적 프라이버시 보장을 제공합니다.
- 단점: 데이터에 노이즈를 추가하기 때문에 모델의 정확도가 감소할 수 있습니다.
- 동형 암호 (Homomorphic Encryption, HE)
- 데이터를 암호화된 상태에서 직접 계산(덧셈, 곱셈 등)을 수행할 수 있도록 하는 암호화 기술입니다.
- 장점: 클라이언트와 서버 간의 통신량을 줄일 수 있고, 데이터의 원본 정확도를 유지하면서 계산할 수 있습니다.
- 단점: 암호화된 데이터에 대한 계산은 복호화된 데이터에 비해 매우 많은 계산 리소스를 요구합니다. 따라서 실용적인 성능을 달성하기 위해서는 HE 연산의 최적화가 필수적입니다.
- Secure Multi-Party Computation (SMPC)
- 기존 HE 기반 전이 학습 연구의 한계
- [1], [2]
- 이 연구들은 암호화된 추론(inference)에 중점을 두었습니다. 서버가 암호화된 입력에 대해 추론을 수행하고 암호화된 특징을 생성하면, 클라이언트가 이를 복호화하여 미세 조정을 수행하는 방식입니다.
- Limitations: 미세 조정이 클라이언트 측에서 이루어지므로, 클라이언트가 머신러닝에 대한 일정 수준의 지식을 가지고 있어야 한다는 가정이 필요하지만, 이는 항상 적용 가능한 경우가 아닙니다.
- PrivGD [3]
- PrivGD 는 최초로 HE 기반의 미세 조정을 지원하는 MLaaS (Machine Learning as a Service) 솔루션입니다.
- 작동 방식: 클라이언트는 자신의 데이터에서 특징을 추출하고, 이를 HE로 암호화하여 서버에 전송합니다. 서버는 이 암호화된 특징을 사용하여 분류기를 미세 조정합니다.
- Limitations: PrivGD는 입력 특징 차원이 32인 소규모 센서 데이터셋에 맞게 설계되었습니다. MNIST와 같이 특징이 많은 데이터셋의 경우, 해당 논문의 행렬 곱셈 알고리즘은 100GB 이상의 높은 메모리를 요구하여 일반 GPU에서 구현하기 어렵다는 문제가 있었습니다.
- [1], [2]
- HETAL의 목표
- 클라이언트가 실제 미세 조정(fine-tuning) 전문 지식이 없을 때 TL 훈련 작업에서 클라이언트 (사용자) 의 프라이버시를 보호하는 것을 목표로 합니다.
- PrivGD 와 동일한 시나리오를 고려하여, 서버가 미리 학습된 모델을 제공하고 클라이언트가 암호화된 특징 데이터를 서버에 전송하여 훈련을 수행하는 방식입니다.
- 위협 모델 (Threat Model)
- 서버는 '선량하지만 호기심이 많은(honest-but-curious, HBC)' 주체로 가정됩니다. 이는 서버가 정의된 프로토콜에서 벗어나지 않지만, 합법적으로 수신한 메시지에서 가능한 모든 정보를 학습하려고 시도한다는 의미입니다 [4].
- HETAL은 서버가 클라이언트의 암호화된 키로 암호화된 최종 모델을 평문으로 얻을 수 없도록 하여 클라이언트의 데이터를 보호합니다.
- 모든 훈련 작업이 서버 측에서 수행되므로 서버의 훈련 전문성(예: 하이퍼파라미터 및 최적화된 소프트웨어)도 클라이언트로부터 보호됩니다.
- Strengths of this paper
- 최초의 실용적인 동형 암호화 기반 암호화된 훈련 방식: HETAL은 동형 암호화(HE)를 기반으로 엄격하게 암호화된 훈련을 제공하는 최초의 실용적인 방식입니다.
- 이전 연구 대부분은 암호화된 추론(inference)에 중점을 두었거나 암호화된 미세 조정을 지원하더라도 특정 환경의 소규모 센서 데이터셋)에 국한되었습니다.
- 검증 기반 조기 종료(Validation-based Early Stopping) 도입: 딥러닝에서 가장 흔히 사용되는 정규화(regularization) 방법인 조기 종료를 적용하여 훈련 중단 시점을 결정합니다.
- 이전 HE 기반 훈련 방식은 성능 문제로 인해 이를 적용하지 못했습니다. 예를 들어, PrivGD 는 HE의 곱셈 깊이(multiplication depth)와 정확도 간의 균형을 고려하여 훈련 에포크(epoch) 수를 미리 고정했습니다. HETAL은 이러한 제약을 극복합니다.
- 효율적인 암호화된 행렬 곱셈 알고리즘
- Training 작업에서 지배적인 연산인 암호화된 행렬 곱셈을 크게 가속화했습니다. 이는 이전 방법보다 1.8배에서 323배 빠릅니다.
- Softmax 근사 알고리즘: 입력 범위가 훨씬 넓은(이전 연구의 [−8, 8] 대비 [−128, 128]) 고정밀 Softmax 근사 알고리즘을 제안합니다. 이는 훈련이 진행됨에 따라 Softmax 함수의 입력 값이 크게 증가하는 문제를 해결합니다.
- Main Contributions
- HETAL 제안 및 프라이버시 보호
- HETAL은 동형암호(Homomorphic Encryption, HE) 기반의 효율적인 전이 학습(Transfer Learning, TL) 알고리즘입니다.
- 클라이언트의 데이터를 HE를 사용하여 암호화한 후 서버에 전송함으로써 학습 작업 중 클라이언트의 프라이버시를 보호합니다.
- 특히, 실수(real numbers)에 대한 암호화된 연산을 지원하는 CKKS 동형암호 스킴(Cheon et al., 2017)을 활용합니다.
- 강력한 실험결과: 실용적인 성능 및 정확도 달성
- MNIST, CIFAR-10, Face Mask Detection, DermaMNIST, SNIPS 와 같은 5가지 잘 알려진 벤치마크 데이터셋과 ViT [5] 및 MPNet [6] 두 가지 사전 학습된 모델을 사용하여 HETAL을 구현하고 평가했습니다.
- 실험 결과, 반복당 4.29~15.72초, 총 567~3442초(1시간 미만)의 학습 시간을 보였습니다.
암호화되지 않은 학습과 거의 동일한 분류 정확도를 달성했으며, 암호화된 학습으로 인한 정확도 손실은 최대 0.5%였습니다.
- 향상된 Softmax 근사 알고리즘 제안
- 기존 연구들보다 훨씬 더 넓은 범위([−128, 128])를 높은 정밀도로 커버하는 새로운 Softmax 근사 알고리즘을 제안했습니다.
이는 PrivGD 가 [−8, 8] 범위만 지원했던 것과 비교하여 훨씬 넓은 범위이며, 기존의 도메인 확장 기술 [7] 을 직접 적용해서는 불가능했던 수백 단계의 모델 학습을 가능하게 했습니다. - 제안된 근사 알고리즘의 오차 한계에 대한 엄격한 수학적 증명도 제공합니다.
- 기존 연구들보다 훨씬 더 넓은 범위([−128, 128])를 높은 정밀도로 커버하는 새로운 Softmax 근사 알고리즘을 제안했습니다.
- 최적화된 행렬 곱셈 알고리즘 개발
- 암호화된 행렬에 대해 행렬 곱셈을 계산하는 최적화된 DiagABT 및 DiagATB 알고리즘을 제안했습니다.
- 이 행렬 곱셈 최적화는 전체 학습 시간의 18%~55%를 차지하는 핵심 작업이므로 HETAL의 뛰어난 속도에 크게 기여했습니다.
- 제안된 알고리즘은 이전 연구 (PrivGD [3], [8])보다 메모리 및 계산 효율성 측면에서 우수하며, 1.8배에서 323배 빠른 성능 향상을 보였습니다.
- HETAL 제안 및 프라이버시 보호
2. Preliminaries
2.1. Transfer learning
- Goal: 본 연구는 멀티 클래스 분류작업을 위한 사전학습 모델 효율적인 fine-tuning (즉, transfer learning) 하는것을 목표로 합니다. 특히, 대규모 데이터셋으로 사전 학습된 모델을 특징 추출기(feature extractor)로 활용하고, 새로운 분류 레이어(classification layer)를 추가하여 미세 조정(fine-tuning)하는 방식에 중점을 둡니다.
- Nesterov's Accelerated Gradient (NAG): 미세 조정은 NAG 방법을 사용하여 크로스-엔트로피 손실을 최소화합니다. NAG는 일반적인 확률적 경사 하강법(vanilla SGD)보다 더 빠른 수렴을 보장하며, 동형 암호화(Homomorphic Encryption, HE) 환경에서도 사용하기에 적합하다고 설명합니다.
2.2. Homomorphic Encryption: CKKS Scheme
- CKKS 스킴 개요
- 실수 및 복소수에 대한 근사(approximate) 산술 연산을 지원하는 동형 암호 스키마입니다.
- 여러 개의 복소수를 하나의 ciphertext(암호문)로 암호화할 수 있으며, 이는 SIMD(Single Instruction Multiple Data) 연산을 지원하여 여러 연산을 동시에 수행할 수 있게 합니다.
- CKKS는 "leveled HE scheme"으로, 이는 특정 "곱셈 깊이(multiplicative depth)" 내에서만 다항식 연산을 수행할 수 있다는 의미입니다. 임의의 복소수 상수를 곱하는 것도 이 깊이를 소모합니다.
- CKKS 에서의 연산
- 덧셈 (Addition): 두 암호문의 요소별 덧셈을 지원합니다.
- 곱셈 (Multiplication)
- Mult: 암호문과 암호문 간의 요소별 곱셈을 의미합니다.
- CMult: 평문(plaintext)과 암호문(ciphertext) 간의 곱셈을 의미합니다.
- x ⊙ y: x와 y가 암호화되었는지 여부와 관계없이 이들의 곱셈을 나타냅니다.
- CKKS는 leveled HE이기 때문에, 연산의 곱셈 깊이가 제한됩니다.
- 회전 (Rotation): 암호문 ct에 있는 평문 벡터 m (plaintext) 의 요소를 r 만큼 왼쪽으로 순환 회전시킵니다.
- Complex Conjugation: 암호문의 요소별 복소수 켤레 연산을 수행합니다.
- Bootstrapping: 이 연산은 임의의 다항식 차수(degrees)에 대한 다변수 다항식 연산을 가능하게 하는 고유한 기능입니다. 동형 암호화의 모든 기본 연산 중에서 가장 계산 비용이 많이 드는 연산입니다. 따라서 부트스트래핑 횟수를 줄이기 위해 회로의 곱셈 깊이를 줄이는 것이 중요합니다.

2.3. Threat Model
- AutoML과 같은 서비스 환경
- 이 연구에서는 클라이언트(데이터 소유자)가 머신러닝 모델 학습 작업을 서버에 위임하는 AutoML(Automated Machine Learning)과 유사한 서비스를 가정합니다.
- 클라이언트 (Client): 자신의 데이터를 소유하며, 머신러닝에 대한 전문 지식이 없을 수도 있습니다.
- 서버 (Server): 머신러닝 학습 서비스를 제공하며, 모델 학습을 담당합니다.
- HETAL 프로토콜의 목표: 클라이언트의 데이터 프라이버시를 보호하면서도 서버가 모델 학습을 수행할 수 있도록 하는 것이 이 프로토콜의 핵심 목표입니다.
- Pre-trained 모델 공유
- 클라이언트와 서버는 Vision Transformer (ViT)와 같이 공개적으로 사용 가능한 사전 학습된 일반 모델을 '특징 추출기(feature extractor)'로 공유합니다.
- 클라이언트의 역할: 학습 과정에서 자신의 개인 데이터로부터 특징(features)을 추출합니다.
- 데이터 전송: 추출된 특징들은 동형 암호화(Homomorphic Encryption, HE) 방식으로 암호화되어 서버로 전송됩니다.
- 서버 (Server): 서버는 전이 학습(Transfer Learning, TL)을 위해 암호문 도메인(ciphertext domain) 에서 미세 조정(fine-tuning)을 수행하며, 그 결과로 암호화된 모델을 생성합니다.
- Honest-But-Curious (HBC) 서버 가정: 이 연구는 서버가 '성실하지만 호기심이 많은(Honest-But-Curious, HBC)' 주체라고 가정합니다.
- HBC의 의미: 서버는 정의된 프로토콜에서 벗어나지 않고 정직하게 작동하지만, 합법적으로 수신한 모든 메시지로부터 가능한 모든 정보를 학습하려고 시도할 수 있습니다 [4].
- 동형 암호화(HE)의 방어 기능: 서버는 복호화 키를 알지 못하므로 암호화된 데이터에 대해 연산을 수행하게 됩니다. 이는 HBC 서버로부터 클라이언트의 데이터를 보호하는 강력한 방어 수단이 됩니다.
3. Protocol
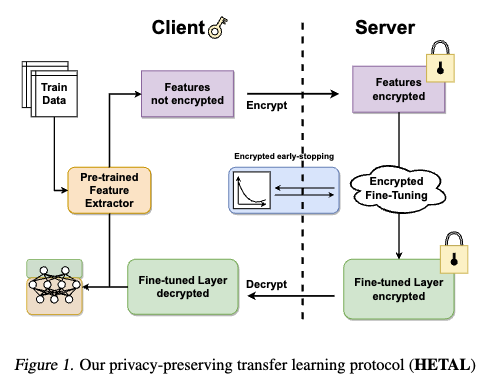
3.1. HETAL Protocol

- 용어 정의
- ct: 암호화된(encrypted) 행렬을 나타냅니다.
- pt: 암호화되지 않은(not encrypted) 행렬을 나타냅니다.
- 클라이언트와 서버의 역할
- 클라이언트: 데이터 소유자로, 자신의 데이터를 암호화하여 서버에 전송하고, 최종 암호화된 모델을 복호화하여 사용합니다.
- 서버: 머신러닝 학습 서비스를 제공하며, 클라이언트의 데이터를 복호화하지 않고 암호화된 상태에서 연산을 수행합니다.
- HETAL 프로토콜 절차
- Feature 추출 (클라이언트): 클라이언트는 사전에 학습된 모델(pre-trained model)을 사용하여 자신의 training data 및 validation data 로부터 임베딩 (features)을 추출합니다. 이 단계에서는 데이터가 암호화되지 않습니다.
- 암호화된 특징 전송 (클라이언트 → 서버): 클라이언트는 추출된 특징과 레이블을 CKKS 동형암호 방식을 사용하여 암호화한 후 서버로 전송합니다. 검증 세트의 특징도 암호화하여 보냅니다. 클라이언트의 개인 데이터는 암호화된 상태로 유지되어 서버에 노출되지 않습니다.
- 암호화된 미세 조정 학습 (서버): 서버는 전송받은 암호화된 임베딩 데이터를 사용하여 모델의 classification layer 을 미세 조정(fine-tuning)합니다.
Nesterov의 가속 경사(NAG) 사용: 미세 조정 학습은 NAG 방법을 사용하여 수행되며, 이는 교차 엔트로피 손실(Cross-Entropy Loss 을 최소화합니다. - 검증 기반 조기 종료(Early Stopping): 서버는 학습 과정 중 오버피팅(overfitting)을 방지하기 위해 validation sets 의 로짓(logits)을 계산합니다. 서버는 암호화된 validation logits 을 클라이언트에게 보냅니다. 클라이언트는 이 logits 을 복호화하여 validation loss 을 계산하고, 손실이 일정 횟수(patience) 동안 감소하지 않으면 학습 중단 신호를 서버에게 보냅니다. 서버는 이 신호를 받아 학습을 조기 종료하거나, 현재의 최적 모델을 업데이트합니다.
- 암호화된 모델 전송 및 복호화 (서버 → 클라이언트): 서버는 미세 조정이 완료된 최종 암호화된 모델을 클라이언트에게 전송합니다. 클라이언트는 이 모델을 복호화하여 추론(inference)에 사용할 수 있습니다.
- 대안적 활용: 프로토콜의 4단계에 대한 대안으로, 암호화된 모델을 서버에 저장하여 암호화된 추론을 수행할 수도 있습니다. 이 경우 클라이언트는 암호화된 임베딩을 서버에 보내고, 암호화된 결과를 받아 복호화합니다.
3.2. Security Analysis
- 클라이언트 데이터 보호
- HETAL은 동형 암호(Homomorphic Encryption, HE)를 사용하여 클라이언트의 데이터를 암호화합니다.
- 서버는 암호화된 특징(features)만 볼 수 있으며, 훈련 epoch 수가 고정되어 있거나 검증 기반의 조기 종료(early stopping)를 사용하더라도 클라이언트의 민감한 원본 데이터를 복구하기 어렵습니다.
- 조기 종료 시 서버로 전송되는 유일한 추가 정보는 "훈련 중지 신호"이며, 이는 클라이언트의 개인 데이터를 복구하는 데 유용하지 않다고 언급됩니다.
- 최종적으로 미세 조정(fine-tuned)된 모델도 클라이언트만 해독할 수 있으므로 서버로부터 보호됩니다.
- 클라이언트 소프트웨어 신뢰성
- MLaaS(Machine Learning as a Service) 환경에서는 ML 비전문가 클라이언트를 위해 서버가 클라이언트 소프트웨어를 제공할 수 있습니다. 이 경우, 클라이언트 데이터의 보안은 해당 소프트웨어의 신뢰성에 달려 있습니다.
- HETAL은 클라이언트 소프트웨어의 소스 코드를 공개하여 제3자가 검증할 수 있도록 함으로써 신뢰성을 확보할 수 있다고 제안합니다
사전 훈련된 모델과 암호화 기능은 서버의 비밀이 아니므로, 소스 코드를 공개해도 서버에 해가 되지 않습니다.
- 서버 전문성 보호: HETAL은 모든 훈련 작업이 서버 측에서 수행되므로, 하이퍼파라미터(hyper-parameters) 및 최적화된 훈련 소프트웨어와 같은 서버의 전문 지식을 보호합니다.
4. Algorithm
This paper propose the following:
1) 이전 연구 [3] 보다 넣은 범위의 A novel softmax approximation algorithm
2) Two novel encrypted matrix multiplication algorithms -> DiagABT and DiagATB
4.1. Softmax Approximation
- 기존 Softmax 근사 방식의 한계점
- 동형 암호화(Homomorphic Encryption, HE) 환경에서 머신러닝 모델을 훈련할 때에는 Softmax 함수의 다항식 근사(polynomial approximation) 가 매우 중요합니다.
- [9,10,11] 등 여러 연구에서 Softmax 함수를 다항식으로 근사하는 방법을 제안했지만, 이들은 다음과 같은 문제점을 가집니다.
- 낮은 정밀도: Appendix의 Table 3에서 볼 수 있듯이, 기존 방법들은 Softmax 값 자체의 정확한 계산보다는 주로 추론(inference) 목적으로 설계되어 정밀도가 낮습니다.
- 작은 근사 도메인: 이 방법들은 입력값이 작은 특정 범위([−4, 4] 또는 [−8, 8]) 내에 있을 때만 효과적으로 작동합니다.
- 훈련 과정에서의 문제: 모델 훈련이 진행될수록 Softmax 함수의 입력값이 0.38에서 100 이상으로 크게 증가하는 경향을 보입니다(Figure 3 참조). 기존의 작은 근사 도메인으로는 이러한 넓은 입력 범위를 처리할 수 없어, 많은 Epochs에 걸쳐 훈련을 수행하기 어렵습니다.
- HETAL의 Softmax 근사 확장 솔루션
- 도메인 확장 기술 적용: HETAL은 Softmax 함수를 넓은 구간에서 효율적으로 근사하기 위해 [7] 에서 제안된 도메인 확장 기술을 적용합니다.
- 이 기술은 DEF(Domain Extension Functions) 및 DEP(Domain Extension Polynomials)를 도입하여 입력값을 고정된 작은 구간으로 '클리핑(clip)'하고, 이를 낮은 차수의 다항식 조합으로 근사하여 지수적으로 넓은 구간에서도 함수를 근사할 수 있도록 합니다.
- 정규화(Normalization)를 통한 문제 해결
- [7] 의 도메인 확장 알고리즘을 Softmax에 직접 적용할 경우, 입력값의 상대적 크기 차이를 무시하고 모두 동일한 값으로 클리핑하여 큰 오차를 발생시키는 문제가 발생합니다.
- 이 문제를 해결하기 위해 HETAL은 Softmax 입력값을 정규화하는 단계를 추가합니다.
- 근사 최대값 계산: 먼저 입력 벡터에서 근사 최대값을 계산합니다. 이 과정에는 [12] 에서 제안된 동형 비교(homomorphic comparison) 알고리즘이 사용되며, 이는 O(log c) 비교 및 회전(rotation) 연산을 필요로 합니다.
- 정규화된 벡터 생성: 계산된 최대값 m 을 입력 벡터의 각 요소에서 빼서 새로운 정규화된 벡터를 생성합니다.
- Softmax 속성 유지: Softmax 함수의 특성을 활용하여, 정규화 과정을 통해 Softmax 결과의 정확성을 유지하면서 입력값이 도메인 확장 기술이 처리할 수 있는 범위로 조정됩니다.
4.2. Encrypted Matrix Multiplication
- 주요 목표: HETAL 알고리즘의 가장 중요한 목표는 동형 암호(Homomorphic Encryption, HE) 환경에서 암호화된 데이터에 대한 행렬 곱셈을 수행할 때 발생하는 회전(rotations) 및 곱셈(multiplications) 연산의 수를 줄이는 것입니다. 이러한 연산들은 알고리즘의 전체 실행 시간(runtime)에서 가장 큰 비중을 차지하기 때문에 이를 최적화하는 것이 중요합니다(논문의 5.1 섹션 참고).
- AB^T 및 A^T B 형태의 효율성
- HETAL은 AB^T (A 곱하기 B의 전치) 또는 A^T B (A의 전치 곱하기 B) 형태의 행렬 곱셈을 사용하는 것이 AB 형태의 직접적인 행렬 곱셈보다 더 효율적이라고 설명합니다.
- 그 이유는 머신러닝 모델 학습의 각 반복(iteration)마다 행렬 전치(transpose) 연산이 필요하기 때문입니다. AB 형태로 계산할 경우, 매번 전치 연산을 수행해야 하는데, 이 전치 연산은 계산 비용이 높고, 동형 암호에서는 추가적인 곱셈 깊이(multiplicative depth)를 요구하게 됩니다.
- 곱셈 깊이는 동형 암호의 중요한 제약 조건 중 하나로, 깊이가 깊어질수록 연산에 필요한 자원이 증가하고 효율성이 떨어집니다. 따라서 전치를 곱셈 연산 자체에 포함시키는 방식이 전체적인 효율성 측면에서 유리합니다.
4.2.1. ENCODING
- 이 연구에서는 효율적인 동형 암호화 연산을 위해 행렬을 암호문으로 인코딩하는 특정 방법을 사용합니다.
- 하위 행렬(Submatrix) 분할: 주어진 행렬을 고정된 크기의 작은 하위 행렬들로 나눕니다.
- 행 우선(Row-major) 순서 인코딩: 각 하위 행렬은 행 우선 순서로 인코딩되어 단일 암호문(ciphertext)에 저장됩니다. 이는 하위 행렬의 항목 수가 단일 암호문의 슬롯(slot) 수 s 와 같도록 설계됩니다.
- 편의를 위한 가정: 설명의 편의를 위해 처음에는 모든 행렬이 단일 암호문에 들어갈 만큼 충분히 작다고 가정합니다.
- 제로 패딩(Zero Padding): 행렬의 행과 열의 수가 2의 거듭제곱이 되도록 필요에 따라 제로 패딩을 적용합니다. 이는 연산 효율성을 높이기 위한 일반적인 방법입니다.
- 확장성: 이 인코딩 방법은 여러 개의 암호문으로 구성된 더 큰 행렬에도 쉽게 확장될 수 있습니다.
4.2.2. COMPUTATION OF AB^T
- 목표: A 와 B 두 행렬에 대해 AB^T 를 기본 HE 연산(덧셈, 곱셈, 회전)을 사용하여 계산하는 것입니다. 효율적인 계산을 위해 타일링(tiling), 오프-다이아고널 마스킹(off-diagonal masking), 그리고 복소화(complexification) 기법을 사용합니다.
- RotUp(B, k) (행렬의 행을 위로 회전)
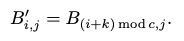
- SumCols(X) (행렬의 열 합계): 행렬 X 에 대해 각 열의 모든 요소를 합산하여 새로운 행렬을 생성하는 연산입니다.
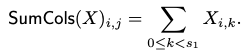
- Bcplx (행렬 복소화): 행렬 B 를 복소화하여 Bcplx = B + sqrt{-1} RotUp(B, c/2)로 정의합니다.
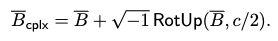
- HE 환경에서 허수 단위 i 를 곱하는 것은 추가적인 곱셈 깊이(multiplicative depth)를 소모하지 않습니다. 이는 HE 연산의 효율성에 중요한 이점입니다.
- AB^T 계산 원리: 이러한 접근 방식은 행렬 곱셈에서 발생하는 주요 비용인 회전(rotations) 및 곱셈(multiplications)의 수를 줄여 전반적인 계산 복잡도를 낮추는 데 기여합니다. 특히, tiling과 complexification은 이러한 최적화에 중요한 역할을 합니다.
4.2.3. COMPUTATION OF A⊺B
- RotLeft(A, k)
- 정의: 행렬 A 의 열을 왼쪽으로 k 만큼 회전시켜 새로운 행렬을 생성하는 연산입니다.
- 특징: 이 연산은 행렬 AB^T 계산 시 사용되는 RotUp과는 달리 곱셈 깊이(multiplicative depth)를 소모합니다. 이는 동형 암호에서 연산의 복잡성을 나타내는 중요한 지표입니다. 곱셈 깊이가 소모되면 암호문의 노이즈가 증가하여 특정 횟수 이상의 곱셈 연산이 불가능해집니다.
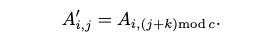
- SumRows(X)
- 정의: 행렬 X 에서 각 행의 모든 요소를 합산하여 새로운 행렬을 생성하는 연산입니다. 즉, 각 열의 모든 행을 더하는 것과 같습니다.
- 특징: 이 연산은 log s_0번의 회전(rotations)으로 수행될 수 있으며, 추가적인 곱셈 깊이를 소모하지 않습니다. 이는 암호화된 데이터를 다룰 때 매우 중요한 장점입니다.
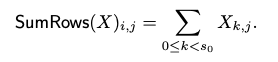
- 복소수화 (Complexification) -> A_{cplx}
- AB^T 연산과 유사하게, 계산 복잡도를 줄이기 위해 행렬 A 를 복소수화 합니다.
- 하지만 RotLeft 연산이 곱셈 깊이를 소모하기 때문에, 복소수화한 A_{cplx}의 동형 암호 레벨(level)은 A 보다 하나 낮아집니다.
이는 A^TB 계산 시 A 의 레벨이 B 의 레벨보다 낮은 경우, 전체 연산의 곱셈 깊이를 증가시킬 수 있는 문제가 발생합니다.
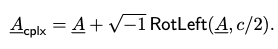
- PRotUp(-, k) (새로운 부분 회전 연산)
- A_{cplx} 의 레벨 문제(즉, A^TB) 연산의 곱셈 깊이 증가 문제)를 해결하기 위해 제안된 새로운 연산입니다.
- 목적: A 의 레벨이 아닌 B 의 레벨을 소모하도록 알고리즘을 설계하여 곱셈 깊이 증가를 방지합니다.
- 정의: 이 연산은 행렬 B 의 마지막 k 개의 열을 한 위치 위로 회전시키는 방식으로 정의됩니다.
- 특징: 이 연산은 단일 CMult(상수 곱셈)와 Lrot(왼쪽 회전) 연산으로 동형적으로 계산될 수 있으며, 곱셈 깊이를 소모합니다.
5. Experimental results
5.1. Experimental setup
- 동형 암호화 라이브러리 및 스킴
- HEaaN (CryptoLab): 연구에 사용된 동형 암호화 라이브러리입니다.
- CKKS 스킴의 RNS 버전: HEaaN은 CKKS(Cheon-Kim-Kim-Song) 동형 암호화 스킴을 기반으로 합니다. CKKS는 실수 및 복소수에 대한 근사 연산(덧셈, 곱셈)을 암호화된 상태로 수행할 수 있게 해주는 특징이 있습니다. 특히 RNS(Residue Number System) 버전은 큰 정수 연산을 효율적으로 처리하기 위한 최적화 기법이 적용되어 있습니다.
- 부트스트래핑 지원: HEaaN은 [13] 논문에서 제안된 부트스트래핑(Bootstrapping) 기능을 지원합니다. 부트스트래핑은 동형 암호화 연산 중 발생하는 노이즈(noise)를 제거하여 무한한 횟수의 연산을 가능하게 하는 핵심 기술이지만, 동형 암호화 연산 중 가장 많은 비용이 드는(159ms) 작업입니다.
- 128비트 보안 수준: [14] 논문의 SparseLWE 추정기를 사용하여 128비트의 보안 수준을 보장했습니다. 이는 현재까지 알려진 공격 방식으로는 2^{128} 번의 연산에 해당하는 계산량 없이는 암호문을 해독하기 매우 어렵다는 것을 의미합니다.
- 하드웨어 구성
- CPU: Intel Xeon Gold 6248 CPU (2.50GHz, 64 스레드)
- GPU: 단일 Nvidia Ampere A40 GPU
- 각 연산의 실행 시간
- Add (덧셈): 0.085 ms
- Rotate (회전): 1.2 ms
- CMult (상수 곱셈): 0.9 ms
- Mult (암호문-암호문 곱셈): 1.6 ms
- Bootstrap (부트스트래핑): 159 ms
5.2. Transfer learning
- 벤치마크 데이터셋: 이미지 분류 및 감성 분석을 위해 5가지 데이터셋이 사용되었습니다.
- MNIST: 0부터 9까지의 손글씨 숫자 이미지 7만 개로 구성된, 가장 널리 사용되는 이미지 분류 데이터셋 중 하나입니다.
- CIFAR-10: 비행기, 자동차, 새, 고양이, 사슴, 개구리, 말, 배, 트럭 등 10가지 클래스의 컬러 이미지 6만 개로 구성된 또 다른 유명한 이미지 분류 데이터셋입니다.
- Face Mask Detection: Kaggle에서 제공하는 데이터셋으로, 마스크 착용 여부 및 올바른 착용 상태를 분류하는 데 사용됩니다. (이 논문에서는 원본 이미지에서 얼굴을 잘라내어 총 4072개의 이미지를 사용했습니다.)
- DermaMNIST: 의료 이미지 데이터셋인 MedMNIST 컬렉션의 일부로, 흔한 색소성 피부 병변 이미지 10015개로 구성되며 7가지 질병으로 분류됩니다.
- SNIPS: Snips Voice Platform에서 수집된 크라우드소싱 쿼리 데이터셋으로, 7가지 사용자 의도를 분류하는 데 활용됩니다.
- 사전 학습 모델
- 특징 추출기(feature extractor)로 2가지 사전 학습 모델이 사용되었습니다.
- ViT (Vision Transformer, ViT-Base): 이미지 데이터의 특징을 추출하는 데 사용되었습니다.
- MPNet-Base: 자연어 데이터의 특징을 추출하는 데 사용되었습니다.
두 모델 모두 데이터 포인트를 단일 768차원 벡터로 임베딩합니다.
- Transfer Learning
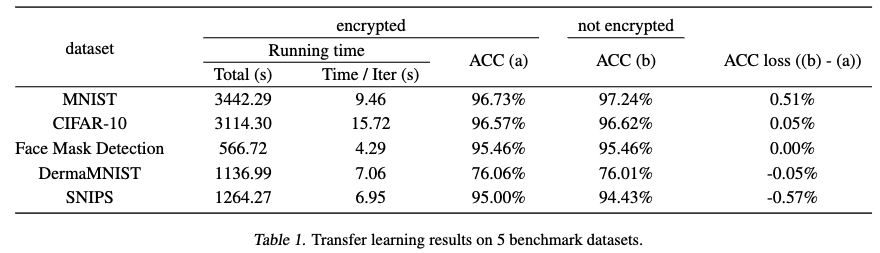
- 훈련 시간: HETAL은 Table 1에 제시된 5가지 벤치마크 데이터셋에서 암호화된 모델을 한 시간 이내로 미세 조정(fine-tuning)했습니다. 이는 실용적인 성능을 보여줍니다.
- 정확도 손실: 암호화된 모델의 분류 정확도는 암호화되지 않은 모델과 비교했을 때, 최대 0.51% 의 미미한 정확도 손실을 보였습니다. 이는 암호화 상태에서도 비암호화 훈련과 거의 동일한 정확도를 달성했음을 의미합니다.
- 조기 종료 (Early Stopping) 및 Patience: 과적합(overfitting)을 방지하기 위해 훈련 중 조기 종료 기법을 사용했습니다. 여기서 'patience'를 3으로 설정했는데, 이는 검증(validation) 손실이 3 에포크(epochs) 동안 개선되지 않으면 훈련을 중단하도록 설정했다는 의미입니다.
- 로짓(Logits) 전송 시간: 검증 데이터셋의 로짓을 전송하는 데 필요한 시간은 총 실행 시간에 비해 무시할 수 있을 정도로 작았습니다. 각 에포크당 암호화된 로짓의 총 크기가 최대 8.8MB에 불과했기 때문입니다.
- 확장성: HETAL 방법은 데이터 포인트를 1024차원 벡터로 임베딩하는 ViT-Large와 같은 더 큰 모델에서도 강력한 확장성을 보여주었습니다 (Appendix C.4 및 Table 8 참조).
5.3. Softmax Approximation
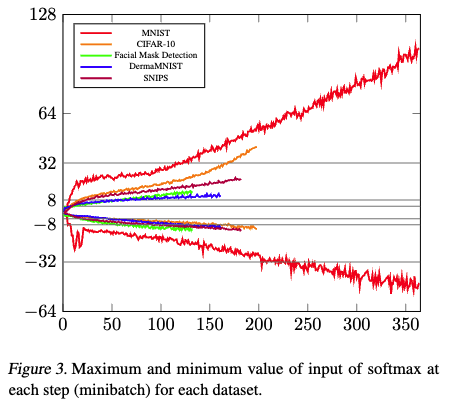
- 새로운 소프트맥스 근사 범위: HETAL은 [−128, 128] 범위의 입력값을 처리할 수 있는 새로운 소프트맥스 근사 알고리즘을 사용합니다. 이는 기존 방법론들이 다룰 수 있는 범위보다 훨씬 넓은 범위입니다.
- 오차 추정 방법: 여러 변수를 가진 함수의 정확한 최대 오차를 찾는 것은 계산적으로 매우 어렵기 때문에, 연구팀은 몬테카를로 시뮬레이션을 사용하여 근사 오차를 추정했습니다. 이 시뮬레이션을 위해 도메인에서 3억 개(300M)의 샘플 포인트를 추출했습니다.
- 오차 결과
- 최대 오차는 입력 차원에 따라 0.0037에서 0.0224 사이로 나타났습니다.
- 평균 오차는 0.0022에서 0.0046 사이였습니다.
- 기존 방법 대비 개선: Appendix A.3의 Table 3에서 볼 수 있듯이, 이러한 오차는 기존 연구 [9,10,11] 에서 제안된 방법들보다 현저히 작습니다.
- 동적 입력 범위 처리: Figure 3은 훈련이 진행됨에 따라 소프트맥스 함수의 입력값이 어떻게 변화하는지 보여줍니다. 특히, 입력값은 두 자릿수(예: MNIST 데이터셋에서 0.38에서 100 이상으로 변화)로 증가하는 경향을 보입니다. 기존의 근사 방법들은 이러한 동적으로 변화하는 넓은 입력 범위를 처리할 수 없었기 때문에, 원하는 만큼 많은 에포크(epoch) 동안 모델을 훈련하기 어려웠습니다. HETAL의 새로운 근사 방법은 이러한 한계를 극복하여 훈련의 실용성을 높였습니다.
5.4. Encrypted Matrix Multiplication
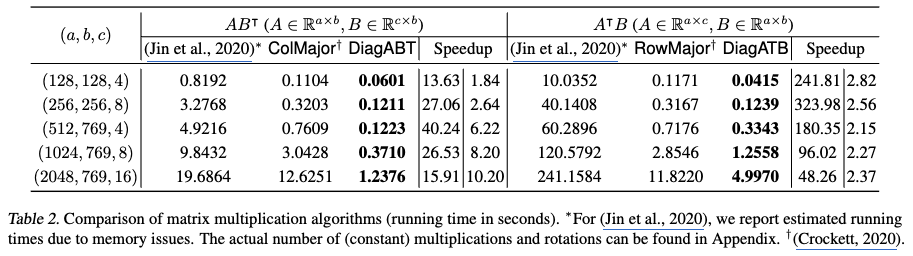
- 행렬 곱셈의 높은 비중: 전이 학습의 전체 훈련 시간에서 행렬 곱셈이 차지하는 비중이 매우 크다는 점을 강조합니다. 예를 들어, CIFAR-10 데이터셋의 모델 미세 조정(fine-tuning)에서는 행렬 곱셈이 전체 훈련 시간의 55% 이상인 약 1712초를 차지했습니다. 이는 효율적인 행렬 곱셈 알고리즘 개발이 필수적임을 보여줍니다.
- 효율성 개선: 이 연구에서 제안하는 행렬 곱셈 알고리즘(DiagABT 및 DiagATB)은 기존의 방법 [3,8] 과 비교하여 1.8배에서 최대 323배까지 속도 향상을 이루었습니다.
- 회전(Rotation) 및 곱셈(Multiplication) 최소화의 중요성
- 동형 암호화 연산에서 단일 곱셈이 단일 회전보다 더 많은 시간을 소요하더라도, 알고리즘 설계 시 회전 및 곱셈 연산의 수를 모두 최소화하는 것이 중요하다고 언급합니다.
- 예시: A ∈ R^(2048×769)와 B ∈ R^(16×769) 크기의 행렬에 대한 AB^T 계산에서, ColMajor 알고리즘은 784번의 곱셈과 8703번의 회전이 필요하여 회전이 전체 비용의 약 90%를 차지했습니다. 이는 회전 연산의 수가 전체 실행 시간에 미치는 영향이 매우 크다는 것을 보여줍니다.
6. Related Work
Softmax Approximation
- Privft [15]
- 이 연구에서는 Softmax 함수를 직접적으로 근사하기보다는 2차 다항식 근사를 사용했습니다.
- Minimax 근사 알고리즘을 활용했으며, 지수 함수 근사에서는 Minimax와 L2-근사 간에 정확도 차이가 없음을 발견했습니다.
- [9] Privacy-Preserving Machine Learning With Fully Homomorphic Encryption for Deep Neural Network
- 원래의 Softmax 함수 대신 Gumbel Softmax 함수를 사용했습니다.
- 이는 Softmax 입력이 근사 영역에 잘 맞도록 하기 위함입니다.
- [11] Secure tumor classification by shallow neural network using homomorphic encryption
- 스케일된 지수 함수(\(A_{E_{r,L}}(x) = ((2r + x)/L)^{2r}\))를 근사하여 사용했습니다.
- 이것을 Goldschmidt의 알고리즘과 결합하여 Softmax를 근사했습니다.
- 하지만 이 방법은 스케일링 팩터 L 을 신중하게 선택해야 하는 어려움이 있습니다.
- [10] Secure transfer learning for machine fault diagnosis under different operating conditions
- 암호화된 데이터로 모델을 학습시켰지만, Softmax 대신 'one-vs-each Softmax' (One-vs-each approximation to softmax for scalable estimation of probabilities)를 사용했습니다.
- 이를 3차 L2-근사된 시그모이드(sigmoid) 함수의 곱으로 근사했습니다.
Encrypted Matrix Multiplication (암호화된 행렬 곱셈 알고리즘 연구)
암호화된 행렬 곱셈 알고리즘에 대해 이전 연구들과 HETAL의 방식을 비교하고 있습니다. 효율적인 암호화된 행렬 곱셈은 전체 학습 시간의 상당 부분을 차지하기 때문에 매우 중요합니다.
- [10] Secure Transfer Learning for Machine Fault Diagnosis Under Different Operating Conditions
- 이 연구에서는 세 가지 다른 패킹(packing) 방식(Row-majored packing, Column-majored packing, Replicated packing)을 사용했습니다.
- 특히 가중치 행렬(weight matrix)에는 REP(Replicated packing)를, 입력/레이블 행렬(input/label matrices)에는 CP(Column-majored packing)를 적용했습니다.
- 장점: 단 하나의 곱셈 깊이(multiplicative depth)만을 소모합니다. 이는 HE 연산에서 중요한 요소 중 하나입니다.
- 단점: HETAL의 방식보다 계산 복잡도가 훨씬 높으며, 행렬을 패킹하기 위해 많은 블록(block)이 필요합니다.
- [8] A low-depth homomorphic circuit for logistic regression model training
- ColMajor 및 RowMajor 알고리즘을 제안했습니다.
- 이 알고리즘들은 행/열을 추출하고 복제하여 이를 행렬-벡터 또는 벡터-행렬 곱셈으로 간주하는 방식입니다.
- 단점: HETAL의 실험 결과, Crockett, 2020의 알고리즘보다 HETAL의 알고리즘(DiagABT, DiagATB)이 훨씬 더 빠른 실행 시간을 보였습니다.
- [16] Secure outsourced matrix computation and application to neural networks, [17] More efficient secure matrix multiplication for unbalanced recommender systems
- 이 알고리즘들은 AB 형태의 행렬 곱셈을 다루며, 전치(transpose) 연산을 포함하지 않습니다.
- 단점: HETAL의 목적(학습)에는 적합하지 않습니다. 왜냐하면 학습의 각 반복(iteration)마다 전치 연산을 추가해야 하므로 비효율적이기 때문입니다.
- 또한, [16] 의 경우 입력 및 가중치 행렬을 단일 블록으로 패킹할 수 없다는 한계도 있습니다.
7. Conclusion
- HETAL
- 본 연구는 데이터를 암호화하여 개인 정보 보호를 제공하는 효율적인 동형 암호(Homomorphic Encryption, HE) 기반 전이 학습(Transfer Learning) 알고리즘인 HETAL을 제안했습니다.
- 5가지 벤치마크 데이터셋에 대한 광범위한 실험을 통해 HETAL의 실용성을 입증했습니다.
- 다양한 domain 분야로의 확장 가능성: HETAL은 음성 분류와 같은 다른 도메인에도 적용될 수 있습니다.
- 핵심 기술의 범용성: HETAL 개발 과정에서 제안된 효율적인 행렬 곱셈 알고리즘과 소프트맥스(softmax) 근사 알고리즘은 소프트맥스 활성화 함수를 사용하는 신경망의 암호화된 추론(encrypted inference)과 같이 다른 다양한 목적으로도 활용될 수 있습니다.
Reference
[1] SEALion: a Framework for Neural Network Inference on Encrypted Data
[2] CryptoTL: Private, Efficient and Secure Transfer Learning
[3] Secure Transfer Learning for Machine Fault Diagnosis Under Different Operating Conditions
[4] Foundations of Cryptography: Volume 2, Basic Applications
[5] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[6] MPNet: Masked and Permuted Pre-training for Language Understanding
[7] Efficient Homomorphic Evaluation on Large Intervals
[8] A low-depth homomorphic circuit for logistic regression model training
[9] Privacy-Preserving Machine Learning With Fully Homomorphic Encryption for Deep Neural Network
[10] Secure Transfer Learning for Machine Fault Diagnosis Under Different Operating Conditions
[11] Secure tumor classification by shallow neural network using homomorphic encryption
[12] Efficient Homomorphic Comparison Methods with Optimal Complexity
[13] Bootstrapping for approximate homomorphic encryption
[14] Practical FHE parameters against lattice attacks
[15] Privft: Private and fast text classification with homomorphic encryption
[16] Secure outsourced matrix computation and application to neural networks
[17] More efficient secure matrix multiplication for unbalanced recommender systems