Domain-specific KG Construction
Goal
- 인간의 개입을 최소화 하면서 신뢰할 수 있는 domain 특화된 KG를 구축
- Cost-Effective KG construction method
SAC-KG: Exploiting Large Language Models as Skilled Automatic Constructors for Domain Knowledge Graphs (ACL 2024)
- LLM을 도메인 전문가처럼 활용하여 전문적이고 정밀한 다단계(multi-level) KG를 자동으로 생성하는 프레임워크 구축이 목표
- 엔티티를 추출하여 각 엔티티는 이미 정의되어 있다고 가정함
- SAC-KG: Generator + Verifier + Pruner
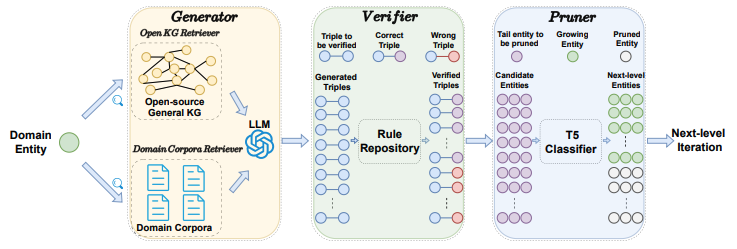
Generator
- Domain Corpora Retriever
- 주어진 엔티티(entity)에 대해 가장 관련성 높은 specialized context 을 도메인 코퍼스 검색기(domain corpora retriever) 를 통해 raw domain corpus 에서 가져옵니다. 즉, 엔티티와 가장 유사한 context 를 검색합니다.
- Process
- 문장 분할: 특정 도메인의 raw 텍스트 데이터(도메인 코퍼스)를 개별 문장으로 나눕니다.
- 관련성 순위 지정: 각 문장에서 특정 엔티티(개념 또는 객체)가 얼마나 자주 나타나는지를 기준으로 문장의 관련성을 순위 매깁니다. 즉, 엔티티 언급 빈도가 높은 문장이 더 관련성이 높다고 간주합니다.
- 텍스트 목록화 및 연결: 관련성이 높은 순서대로 문장들을 모아 텍스트 목록을 만듭니다.
- 고정 길이 텍스트 생성: 이 문장 목록을 고정된 길이의 단일 텍스트 블록으로 연결합니다.
- LLM 입력: 이렇게 생성된 텍스트를 LLM의 입력으로 제공하여, LLM이 해당 도메인과 관련된 정확한 정보를 기반으로 응답을 생성하도록 유도합니다.
- Open KG Retriever
- Open KG Retriever 가 필요한 이유: 생성되는 트리플(triple)의 형식이 잘못되거나 일관성이 없는 문제가 발생할 수 있음
- 이러한 문제를 해결하기 위해 Open KG Retriever 는 외부의 공개된 지식 그래프(open-source KG), 본 연구에서는 DBpedia를 활용
- 핵심 아이디어: LLM이 학습할 때 '인컨텍스트 러닝(in-context learning)'을 통해 관련 예시를 제공받도록 하는 것입니다.
- DBpedia에서 특정 엔티티(entity)와 관련된 실제 트리플들을 예시(examples)로 가져와 LLM에 제공합니다.
- 이 예시들은 LLM이 올바른 트리플 형식을 따르도록 유도하고, 결과물의 제어 가능성을 향상시킵니다.
- 최종 Generator 구성
- Open KG Retriever 를 통해 얻어진 트리플 예시들은 raw domain 코퍼스에서 가져온 관련 텍스트(related context), 그리고 원래의instructions 과 함께 LLM의 입력으로 결합되어 사용됩니다.
- LLM은 더 정확하고 제어 가능한 형식의 트리플을 생성할 수 있게 됩니다.
Verifier
- 목표: LLM이 생성한 triple 들 중에서 오류를 식별하고 제거하여 최종적으로 생성되는 도메인 지식 그래프(KG)의 정확성을 높히는 역할.
- 규칙 기반(Rule-based): 미리 정의된 규칙을 사용하여 오류를 탐지
- Parameter-free: 추가적인 학습이나 매개변수 튜닝이 필요 없습니다.
- 2단계 Process
- 오류 탐지 단계 (Error Detection Step)
- 수량 확인 (Quantity Check): 생성된 triple의 수가 미리 설정된 임계값(기본값 3개)보다 적은 경우 "Quantity insufficient"로 분류합니다.
- 형식 확인 (Format Check): triple이 예시 형식과 일치하지 않으면 "Format error"로 분류합니다.
헤드 개체(head entity)가 미리 정의된 개체와 일치하지 않으면 "Head entity error"로 분류합니다.
헤드 개체와 테일 개체(tail entity)가 동일하면 "Contradiction between head and tail"로 분류합니다. - 충돌 확인 (Conflict Check): RuleHub 에 포함된 규칙을 사용하여 각 triple 에 대한 포괄적인 충돌 탐지를 수행합니다.
예시: 사람의 출생일이 사망일보다 먼저인지, 나이가 음수가 아닌지 등을 확인합니다.
- 오류 수정 단계 (Error Correction Step): 오류 탐지 단계에서 식별된 오류 유형을 기반으로 해당 오류 유형에 맞는 프롬프트(prompt)를 제공합니다. LLM에게 수정된 프롬프트를 다시 제공하여(reprompting) 정확한 출력을 다시 생성하도록 요청합니다.
- 오류 탐지 단계 (Error Detection Step)
Pruner
- 목적
- Pruner는 생성된 지식 그래프(Knowledge Graph, KG)의 제어 가능성을 높이는 역할을 합니다.
- 모든 트리플(triple)의 테일 엔티티(tail entity)가 다음 레벨의 KG 생성을 위한 헤드 엔티티(head entity)로 반드시 사용될 필요는 없기 때문에 생성한 tail entity 에 대해 이를 분류할 필요가 있음.
- 작동 방식
- 입력: Verifier(검증자)를 통과하여 정확하다고 판단된 트리플들의 Tail 엔티티를 입력으로 받습니다.
- 사용모델: DBpedia와 같은 Open-source KG에서 파인튜닝된 T5 기반의 이진 분류기(binary classifier) 모델을 사용합니다.
- 출력: 각 테일 엔티티에 대해, 해당 엔티티가 "growing" 즉, 다음 레벨의 KG 생성을 위해 헤드 엔티티로 계속 사용되어야 하는지, 아니면 "pruned"(가지치기됨) 즉, 더 이상의 생성을 중단해야 하는지를 결정하는 label 을 출력합니다.
- 학습 방법
- Pruner를 훈련시키기 위해 DBpedia에서 데이터를 수집합니다.
- "growing" 범주로는 DBpedia의 헤드 엔티티 서브셋을 사용합니다.
- "pruned" 범주로는 DBpedia의 테일 엔티티 서브셋을 사용하되, 헤드 엔티티 목록과 겹치지 않는 것들로 구성합니다.
- 이 엔티티들의 텍스트를 입력으로, 해당 라벨("growing" 또는 "pruned")을 타겟으로 하여 모델을 파인튜닝합니다.
- KG 생성 과정에서의 역할
- Pruner가 "growing"으로 판단한 엔티티들은 다음 레벨 KG 생성을 위한 Generator(생성자)의 입력으로 사용됩니다.
- 이 과정을 통해 SAC-KG는 단일 레벨 KG를 생성하고, 이를 새로운 레벨의 KG에 통합하는 방식으로 계층적인 KG를 반복적으로 구축합니다. 이는 마치 나무가 층층이 성장하는 것처럼, 지식 접근을 얕은 단계에서 깊은 단계로 점진적으로 확장해 나가는 것과 같습니다.
- Pruner 장점: 이 과정은 비지도 학습(unsupervised) 방식으로, 어떤 도메인이든 방대한 양의 비정형 텍스트 데이터만 있다면 적용할 수 있으며, 별도의 레이블링된 데이터가 필요하지 않습니다.
Medical Graph RAG: Evidence-based Medical Large Language Model via Graph Retrieval-Augmented Generation (ACL 2025)
- MedGraphRAG: LLM이 증거 기반의 의료 응답을 생성하도록 강화하여, 개인 의료 데이터의 안전성과 신뢰성을 향상시키는 데 중점을 둡니다.
- Main Contributions
- Triple Graph Construction: 사용자 문서를 신뢰할 수 있는 의료 출처(credible medical sources)에 연결하여 포괄적인 지식 그래프를 구축합니다. 이는 LLM이 응답의 출처와 정의를 명확하게 추적할 수 있도록 하여 신뢰성과 설명 가능성을 높이는 데 기여합니다.
- U-Retrieval: 'Top-down Precise Retrieval'과 'Bottom-up Response Refinement'를 통합하여 사용자의 질의에 대한 균형 잡힌 문맥 인식과 정밀한 인덱싱을 가능하게 합니다. 이를 통해 총체적인 통찰력과 증거 기반의 응답 생성을 지원합니다.
Triple Graph Construction
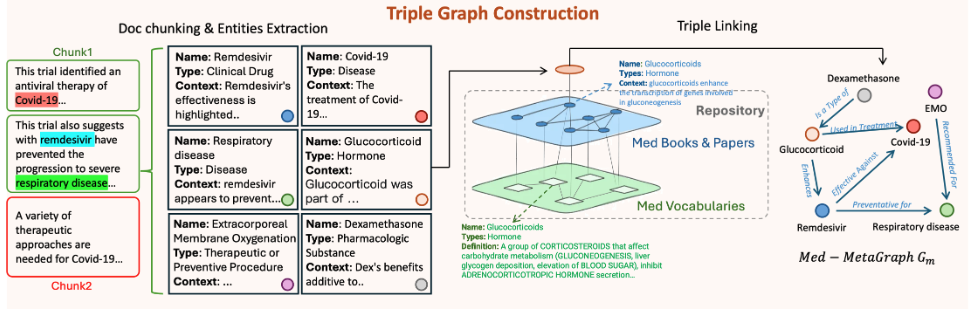
- Preliminary: Document Chunking & Entities Extraction
- Document Chunking 목적
- 방대한 의료 문서는 다양한 내용을 포함하고 있어, 대규모 언어 모델(LLM)이 한 번에 처리하기에는 너무 큽니다. 이는 LLM의 '컨텍스트 한계(context limits)' 때문에 발생합니다.
- 이러한 한계를 극복하기 위해, 문서를 더 작고 관리하기 쉬운 부분인 '청크(chunks)' 또는 'paragraphs' (P)으로 나눕니다.
이는 LLM이 각 청크를 효과적으로 처리할 수 있도록 하여, 전체 문서의 정보를 활용하는 기반을 마련합니다.
- Document Chunking 과정
- 본 논문에서는 LangChain에서 구현된 '시맨틱 청킹(semantic chunking)' 기능을 사용. 이는 단순히 고정된 길이로 나누는 것이 아니라, 텍스트의 의미적 경계를 고려하여 나누는 기법입니다.
- 텍스트 임베딩 모델(text embedding model)을 사용하여 단락 간의 의미적 유사성을 파악합니다.
- 청킹 과정에서는 '버퍼 크기(buffer size)'를 5로 설정하고, 그래프 구축에 사용되는 LLM의 '토큰 제한(token limit)'을 준수합니다.
- 엔티티 추출 (Entity Extraction)
- 청크로 나눈 문서에서 의미 있는 엔티티를 식별하고 추출하는 과정.
- 의료 분야는 고유한 용어와 개념이 많기 때문에, 이러한 엔티티들을 명확하게 정의하고 분류하는 것이 중요합니다.
- 엔티티 추출 과정
- 각 청크에서 그래프 구축 LLM(Llama3-70B)을 사용하여 모든 관련 엔티티 E = (na, ty, cx) 를 식별합니다.
- 추출된 각 엔티티(e)는 다음과 같은 구조화된 형태로 출력함
- na (name): 문서에서 가져온 엔티티의 실제 텍스트(예: "심근경색").
- ty (type): UMLS 시맨틱 타입(semantic types)에서 선택된 엔티티의 범주(예: "질병", "약물", "해부학적 구조"). UMLS는 의료 용어와 개념을 표준화한 시스템입니다.
- cx (context): 그래프 구축용 LLM 이 문서 내에서 엔티티가 언급된 맥락을 설명하기 위해 생성한 몇 문장의 설명입니다.
- 이렇게 추출된 엔티티들은 이후 'Triple Graph Construction' 단계에서 지식 그래프를 구축하는 데 활용됩니다.
- Document Chunking 목적
- Triple Linking
- 의학은 정확한 용어와 확립된 사실에 의존하므로, LLM이 신뢰할 수 있는 출처와 전문적인 정의에 기반한 응답을 제공하는 것이 필수적입니다. Triple Linking은 이러한 목표를 달성하기 위해 사용자 문서(RAG data)를 신뢰할 수 있는 의료 출처 및 전문 정의와 연결합니다.
- RepoGraph 구축
- 개념: 사용자 간에 고정되어 재사용될 수 있는 저장소 그래프(RepoGraph)를 구축합니다. 이는 사용자 RAG 문서에 대해 확립된 출처와 통제된 어휘 정의를 제공하는 역할을 합니다.
- 이중 레이어 구성: RepoGraph는 두 개의 레이어로 구성됩니다.
- 하단 레이어: UMLS (Unified Medical Language System) 그래프로 구성됩니다. UMLS는 포괄적이고 잘 정의된 의료 어휘와 그 관계를 포함합니다.
- 상단 레이어: 의료 교과서 및 학술 논문에서 동일한 그래프 구성 방식을 사용하여 구축됩니다.
- 계층적 엔티티 연결
- 세 가지 계층의 그래프(사용자 RAG 문서, 의료 서적/논문, 의료 사전)에 있는 엔티티들은 의미론적 관계를 통해 계층적으로 연결되어 최종적인 Meta Graph (Medical Doamin KG) 를 구축하게 됩니다.
- 엔티티 정의: RAG 문서에서 추출된 엔티티는 \(E_1\) 으로, 의료 서적/논문에서 추출된 엔티티는 \(E_2\)로, UMLS 사전에서 추출된 엔티티는 \(E_3\)으로 표시됩니다.
- Contents Embedding: 엔티티 간의 관련성은 콘텐츠 임베딩간의 코사인 유사도를 계산하여 결정됩니다. 여기서 엔티티의 콘텐츠는 해당 엔티티의 이름(na), 유형(ty), 그리고 문맥(cx)을 연결한 텍스트입니다:
- 참조 관계 (The Reference Of): \(E_1\)의 엔티티는 \(E_2\) 엔티티와 그 관련성을 기반으로 연결됩니다. 이 관계는 "The Reference Of" 로 명시되며, 코사인 유사도가 사전에 미리 정의된 임계값보다 크거나 같을 때 설정됩니다.
- 정의 관계 (definition of): \(E_2\)의 엔티티는 \(E_3\)의 엔티티(UMLS)와 동일한 방식으로 "definition of" 관계를 통해 연결됩니다.
- 결과: 이를 통해 RAG 엔티티는 [RAG 엔티티, 출처, 정의] 형태의 트리플로 구성됩니다.
- RAG 엔티티 간의 관계 식별
- Graph Construction LLM input: RAG 엔티티1 컨텐츠, RAG 엔티티2 컨텐츠, 참조컨텐츠1, 참조컨텐츠2
- LG(Graph Construction LLM)는 각 문서 덩어리내에서 RAG 엔티티 간의 관계를 식별하도록 지시받습니다.
- 식별된 관계
- 출처 및 대상 엔티티를 지정하고 관계에 대한 설명을 제공
- LLM LG가 관계 식별 및 생성 프롬프트를 사용하여 생성한 간결한 관계 구문입니다.
- 최종 결과: 이러한 분석을 수행한 후, 각 데이터 덩어리에 대해 Meta-MedGraphs 라는 방향성 그래프가 생성됩니다.
GraphRAG Workflow by Microsoft
From Local to Global: A GraphRAG Approach to Query-Focused Summarization
Sensemaking.
- 주어진 정보들 (e.g., 청킹된 문서들) 을 어떻게 연결시키며, 혹은 정보간의 내재적인 연결관계를 어떻게 찾을 것인가
- 주어진 정보들중에 어떤것이 더 중요한가 ?
- Global sensemaking: 방대한 양의 corpus 에서 전반적인 내용을 바탕으로 진행되는 sensemaking
- Query 특성: RAG pipeline 에서 사용하는 정보들의 연결관계를 이해하고 있어야 정확하게 답변할 수 있음
문제정의.
- 기존의 Naive RAG system 은 정보들간의 연결관계를 고려하지 못하는 문제
- 주어진 정보 (문서, 코퍼스) 의 양이 방대할 때 global sensemaking 능력이 부족함
- Global sensemaking 은 언제 필요할까 ?
- 예시 Query: 2015년 ~ 2025년 이차전지 관련 연구 분야에서 인공지능을 활용했던 연구 사례를 논문 예시를 들어 설명해 주세요
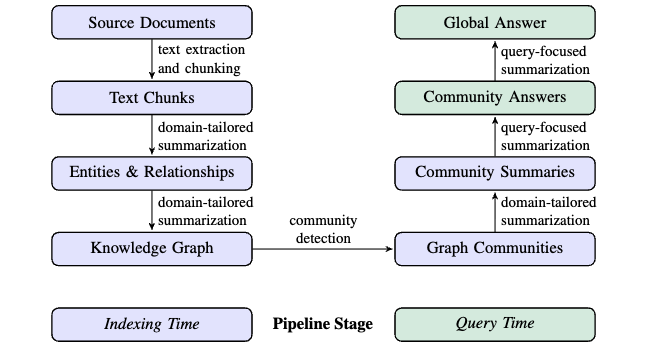
GraphRAG Pipeline.
- Indexing Time: Source Documents Graph Indexing using LLM (KG Construction)
- Source Documents -> Document Chunking
- Entity & Relationship Extraction
- KG Construction
- Community Detection by Leiden Technique (KG 클러스터링)
- Community Level: 여러 계층(\(C_0\), \(C_1\), \(C_2\), \(C_3\) 등)의 커뮤니티로 나눕니다. 각 계층은 다른 수준의 상세도와 범위를 가집니다
- 예를들어, \(C_0\)는 가장 광범위하고 적은 수의 요약, \(C_3\)는 가장 상세하고 많은 수의 요약
- Community Summary using LLM -> 각 커뮤니티를 요약하는 text 생성
- Query Time
- 각 community 로부터 query 와 연관된 요약된 정보를 추출하여 최종적으로 하나의 요약 내용을 형성한 후 query 와 함께 prompt 를 구성하여 최종적인 global answer 를 생성
- 주어진 질의에 대해 하나의 특정 커뮤니티 수준(예: C1 또는 C2)을 선택하여 해당 수준의 커뮤니티 요약들을 사용. 모든 계층의 요약들을 동시에 사용하는 것이 아님.
System Prompts: Entity & Relation Extraction for KG Construction.

- Goal: LLM에게 이 프롬프트의 목적이 무엇인지 명확하게 알려줍니다. 여기서는 "이 활동과 잠재적으로 관련된 텍스트 문서와 개체 유형 목록이 주어졌을 때, 텍스트에서 해당 유형의 모든 개체와 식별된 개체들 간의 모든 관계를 식별하라"고 지시
- Steps: LLM이 작업을 수행할 구체적인 절차를 정의
- 단계 1: 개체 식별 (Identify all entities.)
- 개체의 이름(entity name): 텍스트에서 발견된 개체의 고유한 이름을 대문자로 추출하도록 지시
- 개체 유형(entity type): [{entity types}] 부분에 미리 정의된 개체 유형 목록(예: ORGANIZATION, PERSON, LOCATION 등) 중 하나로 분류하도록 합니다. 이는 도메인에 따라 맞춤화될 수 있습니다.
- 개체 설명(entity description): 개체의 속성 및 활동에 대한 포괄적인 설명을 추출하도록 지시합니다. LLM은 텍스트 내용을 바탕으로 해당 개체가 무엇이며 어떤 역할을 하는지 요약
- 단계 2: 관계 식별 (Identify relationships.)
- 소스 개체(source entity): 관계의 시작점을 추출합니다.
- 타겟 개체(target entity): 관계의 종착점을 추출합니다.
- 관계 설명(relationship description): 두 개체가 서로 어떻게 관련되어 있는지에 대한 설명을 추출합니다.
- 관계 강도(relationship strength): 관계의 강도를 나타내는 수치(예: 1-10)를 부여하도록 지시합니다. 이는 관계의 중요성이나 텍스트 내에서의 명확성 등을 LLM이 판단하여 부여하는 값입니다.
- 단계 3: 출력 형식 정의 (Return output in English as a single list...): 식별된 모든 개체와 관계를 **{record delimiter}**로 구분된 단일 목록으로 출력하도록 합니다.
- 단계 4: 완료 지시 (When finished, output {completion delimiter}): LLM이 추출 작업을 마쳤음을 알리는 특정 토큰을 출력하도록 합니다.
- 단계 1: 개체 식별 (Identify all entities.)
- Examples
- 프롬프트는 "Input"과 "Output" 쌍으로 구성된 예시를 포함합니다. 이 퓨샷(few-shot) 예시는 LLM이 원하는 추출 형식과 내용을 더 정확하게 이해하도록 돕는 "인컨텍스트 학습(in-context learning)"의 역할을 합니다.
- 특히 도메인별 지식이 필요한 경우, 해당 도메인에 특화된 예시를 제공함으로써 추출의 정확도를 높일 수 있음. (예: 의학 논문에서 질병-치료법 관계 추출)
- 프롬프트는 "Input"과 "Output" 쌍으로 구성된 예시를 포함합니다. 이 퓨샷(few-shot) 예시는 LLM이 원하는 추출 형식과 내용을 더 정확하게 이해하도록 돕는 "인컨텍스트 학습(in-context learning)"의 역할을 합니다.
- Real Data: 실제로 정보를 추출하고자 하는 텍스트 "{input text}"와 사용할 개체 유형 "{entity types}"을 LLM에 입력합니다.
'Research in NLP' 카테고리의 다른 글
| Datasets for GraphRAG Evaluation (0) | 2025.12.22 |
|---|---|
| GraphRAG Survey-1: Introduction to Graph RAG (0) | 2025.12.09 |
| Contextual Information and Mutual Dependency between words using document graph (4) | 2024.06.10 |
| 논문 읽는 법 , AI 연구를 시작하는 방법 - MIT (0) | 2024.03.07 |
| 연구 가설이란 무엇인가 : 좋은 연구 가설을 세우는 방법 (0) | 2024.03.07 |