
Enhancing Short-Text Topic Modeling with LLM-Driven Context Expansion and Prefix-Tuned VAEs
(Findings of EMNLP 2024)
Abstract
- Short-text topic modeling 에서 존재하는 "label sparsity problem": 전통적인 토픽 모델은 단어의 동시 발생 빈도에 의존하지만, 짧은 텍스트는 이러한 정보가 부족하여 일관성 없는 주제를 생성하는 문제가 있습니다.
- LLM-Driven Context Expansion
- Label sparsity problem 를 해결하기 위해, 거대 언어 모델(LLM)을 활용하여 짧은 텍스트를 확장하고 더 자세한 시퀀스로 만듭니다.
- LLM은 짧은 텍스트의 문맥을 풍부하게 만들고, 토픽 모델링을 적용하기 전에 텍스트의 정보 밀도를 높입니다.
LLM은 텍스트 생성 과정에서 내재된 토픽 모델링 능력을 활용하여 텍스트를 생성합니다.
- PVTM (Prefix-Tuned Variational Topic Model)
- LLM으로 생성된 텍스트의 의미론적 불일치 문제를 해결하고 효율성을 높이기 위해, Prefix Tuning을 사용합니다.
- Prefix Tuning은 작은 언어 모델 (SBERT) 을 훈련시켜 짧은 텍스트의 토픽 모델링 성능을 향상시킵니다.
- Prefix Tuning (PEFT) 은 언어 모델의 일부 파라미터만 조정하여 계산 비용을 줄이면서도 특정 작업에 맞게 (Task-Specific) 모델을 최적화합니다.
- VAE 결합: Prefix Tuning된 언어 모델은 변분 오토인코더(VAE)와 결합됩니다.
- VAE는 잠재 공간에서 토픽을 추론하고, 생성된 텍스트를 재구성하는 역할을 합니다.
- VAE는 Prefix Tuning된 언어 모델에서 추출된 특징을 사용하여 이산적인 토픽을 디코딩합니다.
- 결론
- 본 연구에서 제안된 모델은 short-text 벤치마크 데이터셋에서 state-of-the-art 토픽 모델보다 우수한 성능을 보입니다.
- 이 연구는 짧은 텍스트의 토픽 모델링에서 데이터 희소성 문제를 해결하고, LLM의 강력한 텍스트 생성 능력을 활용하여 토픽 모델링의 효율성과 정확성을 높이는 데 기여합니다.
Introduction
- Data sparsity problem in Short-text topic modeling
- 기존 토픽 모델들은 충분한 단어 co-occurrence 정보를 필요로 하지만, 짧은 텍스트는 이러한 정보가 부족합니다. 이는 데이터 희소성 문제를 야기하여 고품질의 토픽을 추출하기 어렵게 만듭니다.
- News headline 이나 image 캡션과 같은 짧은 텍스트는 내용이 제한적이어서 모델이 의미 있는 패턴을 찾기 어렵습니다.
- 주제 인지 방식
- 인간은 짧은 텍스트의 토픽을 판단할 때 배경지식과 텍스트 내의 단서를 기반으로 더 넓은 문맥을 추론합니다.
예를 들어, "No tsunami but FIFA’s corruption storm rages on"이라는 헤드라인을 보고 "FIFA"라는 단서를 통해 "스포츠"라는 토픽을 추론합니다. - LLM 활용
- LLM은 제한된 문맥에서 유창한 텍스트를 생성하는 능력이 뛰어나므로, 짧은 텍스트의 문맥 정보를 풍부하게 하는 데 활용될 수 있습니다.
- LLM은 짧은 텍스트를 확장하여 더 자세하고 문맥이 풍부한 내러티브를 생성함으로써, 기존 토픽 모델링 기술이 필요로 하는 상세한 문맥을 제공할 수 있습니다.
이는 토픽을 분석하기 전에 주어진 짧은 텍스트를 둘러싼 더 넓은 문맥을 인간처럼 추론하는 것을 모방합니다.
- 인간은 짧은 텍스트의 토픽을 판단할 때 배경지식과 텍스트 내의 단서를 기반으로 더 넓은 문맥을 추론합니다.
- LLM 활용시 발생하는 문제
- LLM이 생성한 텍스트가 원래 짧은 텍스트의 의미를 정확하게 반영하도록 보장하는 것이 어렵습니다. LLM은 특정 작업이나 도메인에 대해 미세 조정되지 않았을 수 있으므로, 관련 없는 정보나 부정확한 정보를 도입할 수 있습니다.
LLM 호출의 지연 시간으로 인해 실시간 토픽 감지가 비현실적일 수 있습니다. - 본 논문에서 제안하는 접근 방식
- LLM이 생성한 긴 텍스트를 직접 입력으로 사용하는 대신, 짧은 텍스트에서 토픽을 학습하고 LLM이 이전에 생성한 긴 텍스트를 재구성하도록 모델을 학습합니다.
- 이는 생성된 텍스트에서 의미 변화의 영향을 최소화하고, LLM의 고유한 특성(잠재 개념 공간을 탐색하여 텍스트를 생성하는 토픽 모델링 능력)과 일치합니다.
- LLM이 생성한 텍스트가 원래 짧은 텍스트의 의미를 정확하게 반영하도록 보장하는 것이 어렵습니다. LLM은 특정 작업이나 도메인에 대해 미세 조정되지 않았을 수 있으므로, 관련 없는 정보나 부정확한 정보를 도입할 수 있습니다.
- Prefix-tuned Variational Topic Model (PVTM)
- PVTM은 작은 언어 모델 (SBERT)과 VAE 를 결합하여 토픽 추론을 수행합니다.
LM 전체를 조정하는 대신, Prefix Tuning (PEFT) 을 사용하여 짧은 텍스트에서 도메인 특화된 특징을 효과적으로 캡처합니다.
VAE는 LM에서 추출된 특징 (즉, 문서의 임베딩) 을 입력으로 사용하여 이산적인 토픽을 디코딩합니다.
smaller LM (SBERT) 과 VAE는 효과적인 학습을 위해 토픽 모델링 objective 와 함께 학습됩니다. - PVTM의 주요 장점
- Semantic consistency: 짧은 텍스트로 학습하고 생성된 긴 텍스트를 출력으로만 사용하여 원래 데이터의 무결성을 보장하고 관련 없는 정보가 도입될 위험을 줄입니다.
- Efficiency: 작은 LM의 추론 시간 감소와 VAE의 이산 토픽 학습 효율성으로 인해 실시간 토픽 감지 애플리케이션에 적합합니다.
- Prefix Tuning (PEFT): 대규모 LLM을 조정하는 데 드는 계산 오버헤드 없이 도메인 특화된 특징을 캡처하여 확장성을 보장합니다.
- PVTM은 작은 언어 모델 (SBERT)과 VAE 를 결합하여 토픽 추론을 수행합니다.
- Contributions
- LLM을 사용하여 짧은 텍스트를 확장하고 확장된 텍스트에 기존 토픽 모델을 적용하는 방법을 탐구합니다.
- 효율성을 개선하고 의미론적 이동 문제를 해결하기 위해 공동으로 학습된 작은 LM과 VAE로 구성된 새로운 프레임워크인 PVTM을 제안합니다.
- 다양한 데이터 세트에 대한 포괄적인 실험을 통해 제안된 모델의 우수성을 입증합니다.
Related Work
Traditional Topic Models
- PLSA, LDA: 전통적인 확률적 토픽 모델들은 큰 문서에서 단어의 동시 발생 정보를 활용하여 잠재된 토픽 구조를 파악합니다. 하지만 뉴스 제목이나 이미지 캡션과 같은 짧은 텍스트에서는 단어의 동시 발생 정보가 부족하여 효과적인 토픽 생성이 어렵습니다.
- Existing Approaches for Short Text Topic Modeling
- BTM (Biterm Topic Model): 텍스트의 구조적, 의미적 정보를 활용하여 단어 쌍(biterm)에 집중하여 토픽을 모델링합니다.
- Metadata 활용: 해시태그나 외부 코퍼스와 같은 메타데이터를 사용하여 짧은 텍스트를 더 긴 유사 문서로 집계한 다음, 전통적인 토픽 모델을 적용합니다.
- DMM (Dirichlet Multinomial Mixture) 모델: 각 문서가 하나의 토픽에서 추출되었다고 가정하여 모델을 단순화합니다. 하지만 실제 짧은 텍스트는 여러 토픽을 포함할 수 있기 때문에 이러한 가정이 과도하게 제한적일 수 있습니다.
Neural Topic Models
- VAE의 성공과 새로운 연구 방향
- VAE(Variational Autoencoder, 변분 오토인코더)의 성공은 신경망 토픽 모델링에 새로운 연구 방향을 제시했습니다.
- NVDM 은 VAE를 토픽 모델링에 처음으로 적용한 연구로, 가우시안 분포의 재매개변수화(reparameterization) 기법을 활용하여 뛰어난 성능 향상을 이루었습니다.
- ProdLDA 는 디리클레 분포의 재매개변수화의 어려움을 해결하기 위해 Logistic Normal 분포를 사용했습니다.
재매개변수화 기법 (Reparameterization Trick): VAE에서 잠재 변수를 샘플링할 때, 역전파가 가능하도록 하는 방법입니다.
- 짧은 텍스트를 위한 NTM 연구
- Topic Memory Networks for Short Text Classification (Zeng et al., 2018)은 NTM과 메모리 네트워크를 결합하여 짧은 텍스트 분류를 수행했습니다.
- (Zhu et al., 2018)은 확률적 biterm 토픽 모델의 아이디어를 NTM에 적용하여, biterm을 샘플링한 그래프 신경망(GNN)을 인코더로 사용했습니다. 그러나 이 모델은 개별 문서의 토픽 분포를 생성하는 데는 어려움이 있습니다.
- (Lin et al., 2020)은 아르키메데스 코퓰라(Archimedean copulas) 아이디어를 신경망 토픽 모델에 도입하여 짧은 텍스트의 토픽 분포의 이산성을 조절하고, 문서가 특정 토픽에 집중되는 것을 방지했습니다.
- (Feng et al., 2022)은 각 짧은 텍스트에 대해 활성 토픽의 수를 제한하고, 사전 학습된 단어 임베딩에서 토픽의 단어 분포를 통합하는 NTM을 제안했습니다.
- (Wu et al., 2020)은 토픽 분포 양자화(quantization) 방법을 사용하여 짧은 텍스트 모델링에 더 적합한 뾰족한(peakier) 분포를 생성하는 신경망 토픽 모델을 개발했습니다.
- Biterm Topic Model: Biterm Topic Model(BTM)은 짧은 텍스트에서 토픽을 모델링하기 위해 제안된 방법입니다.
BTM은 문서 내 단어들의 동시 발생 패턴을 직접 모델링하여 토픽을 학습합니다.
기존의 토픽 모델들이 문서 수준에서의 단어 동시 발생을 분석하는 반면, BTM은 전체 코퍼스에서 단어 쌍(biterm)의 동시 발생 패턴을 활용하여 데이터 희소성 문제를 해결합니다. BTM은 각 문서가 짧더라도 코퍼스 전체의 정보를 활용하여 더 정확하고 일관성 있는 토픽을 추출할 수 있습니다.
LMs in Topic Models
- CombinedTM
- 문서의 Bag of Words (BOW) 표현과 BERT와 같은 LM에서 추출한 문맥화된 벡터를 결합합니다.
- BOW가 놓치는 문맥 정보와 단어 순서 정보를 포착합니다.
- BERTopic
- LM 기반의 문서 임베딩을 사용하여 문서를 클러스터링하고, TF-IDF를 통해 각 클러스터를 대표하는 단어를 식별하여 토픽을 추출합니다.
- 하지만 TF-IDF에 의존하기 때문에 LM의 단어 의미론적 정보를 충분히 활용하지 못한다는 한계가 있습니다.
- DeTime: Encoder-Decoder 기반의 LLM을 사용하여 임베딩의 클러스터링 성능과 토픽의 의미론적 일관성을 향상시킵니다.
- 기존 연구의 한계
- 이러한 발전에도 불구하고 기존 모델들은 짧은 텍스트의 데이터 희소성 문제를 해결하지 못하고, 이러한 연구들은 일반적인 목적의 토픽 모델링을 위한 문서 표현 개선에만 집중합니다.
- 본 연구의 차별성: 본 논문에서는 LM을 조건부 텍스트 생성에 활용하여 짧은 문서의 문맥 정보를 풍부하게 만드는 새로운 프레임워크를 제안합니다. 기존 연구들과 달리 짧은 텍스트의 데이터 희소성 문제를 해결하는 데 초점을 맞추고 있습니다.
Proposed Methodology

Short Text Extension
- [1] 에 따른 LLM의 토픽 모델링
- Demonstrations for In-Context Learning에 따르면, LLM은 텍스트를 생성할 때 잠재된 토픽을 기반으로 단어를 선택하는 방식으로 작동합니다. 즉, LLM은 텍스트 생성 과정에서 토픽 모델링을 수행합니다.
- 잠재 토픽 변수 θ: LLM은 각 토큰(단어)을 생성할 때 잠재 토픽 또는 개념 변수 θ의 영향을 받습니다. 이는 LLM이 텍스트를 이해하고 생성하는 과정이 잠재 개념 공간을 탐색하는 것과 같다는 것을 의미합니다.
- 잠재 변수의 한계: LLM이 텍스트 생성 시 잠재 토픽 변수를 사용하지만, 이 변수를 명시적으로 얻어내어 토픽을 이해하기는 어렵습니다.
- 짧은 텍스트 확장: 따라서 짧은 텍스트를 확장하는 것을 조건부 문장 생성 작업으로 공식화합니다. 즉, 짧은 텍스트가 주어졌을 때 더 긴 텍스트 시퀀스를 생성하는 문제입니다.
Topic Model on Generated Long Text
- LLM-driven Context Expansion: Table 1 과 같이 LLM 을 통해 짧은 텍스트를 긴 텍스트로 확장할 시 다음과 같은 이점이 있습니다.
- 단어 동시 발생(Co-occurrence) 정보: 확장된 텍스트는 원본 짧은 텍스트보다 단어들이 함께 나타나는(동시 발생) 맥락적인 정보가 더 풍부합니다. 이는 토픽 모델이 주제를 파악하는 데 중요한 역할을 합니다.
- 데이터 희소성(Data Sparsity) 완화: 짧은 텍스트는 단어의 동시 발생 빈도가 낮아 데이터 희소성 문제가 발생하기 쉽습니다. 긴 텍스트를 사용하면 이러한 데이터 희소성 문제를 줄일 수 있습니다.
- LLM 을 사용하여 확장된 긴 텍스트를 토픽 모델링에 직접 사용하는 경우 발생할 수 있는 몇가지 문제점
- 원래 도메인과의 차이: LLM이 생성한 텍스트가 원래 짧은 텍스트의 도메인에서 벗어나거나, 의도한 주제를 부분적으로만 다룰 수 있습니다.
- 불완전한 topic coverage: 원래 짧은 텍스트가 여러 주제를 다루고 있지만, LLM이 생성한 긴 텍스트에서 일부 주제가 누락될 수 있습니다. 이는 문서에서 다루는 주제의 완전성이 떨어지는 결과를 초래합니다.
- 이러한 문제를 해결하기 위해, 이 논문에서는 Prefix-tuned Variational Topic Model (PVTM)을 제안합니다. PVTM은 LLM이 생성한 텍스트를 직접 입력으로 사용하는 대신, 짧은 텍스트에서 재구성된 출력으로만 사용하여 토픽 모델의 성능을 향상시키는 방법입니다. 즉, 제안하는 PVTM 모델은 짧은 텍스트를 입력으로 받아 LLM이 생성한 긴 텍스트를 재구성하도록 학습됩니다. 다시말해, LLM 이 생성한 긴 텍스트를 reconstuction error loss 에 활용합니다. PVTM은 ProdLDA 모델을 기반으로 합니다.
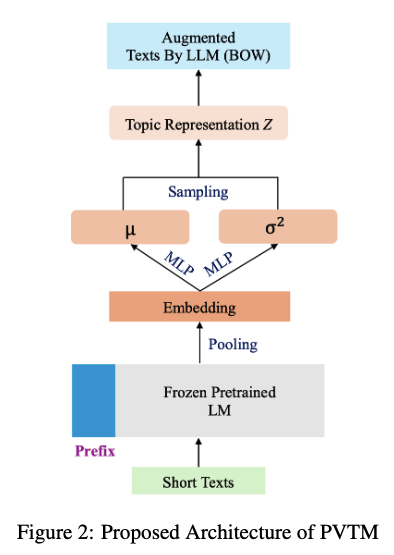
- PVTM
- PVTM은 기존의 NTM 인 ProdLDA 아키텍쳐를 기반으로 합니다.
- 제안하는 PVTM에서는 ProdLDA 에서 사용한 방식대로 BoW 를 input 으로 사용하는 대신에, 더 작은 SBERT 와 같은 smaller LM 을 사용하여 짧은 텍스트를 인코딩하고, 토픽 모델링과 관련된 풍부하고 Task-Specific 된 특징을 학습합니다. BoW 표현은 특히 짧은 텍스트에서 중요한 의미적 뉘앙스를 포착하지 못하는 단점이 있습니다.
- Prefix Tuning
- 전체 LM을 학습하는 것은 계산 비용이 많이 들기 때문에, Prefix Tuning 이라는 파라미터 효율적인 미세 조정 방법을 사용합니다.
- Prefix Tuning의 핵심 아이디어는 입력 임베딩의 각 Transformer 계층에 학습 가능한 벡터(prefix)를 추가하여 LM이 사전 훈련된 가중치를 수정하지 않고도 특정 작업에 맞게 동작을 조정하도록 하는 것입니다.
- Pre-fix Tuning 을 통한 이점
- 계산 효율성 (Computational Efficiency): Pre-trained LM 전체를 fine-tuning하는 대신, PEFT 기법은 모델의 일부 파라미터(예: prefix vectors)만 학습합니다. 따라서 학습에 필요한 계산 자원과 시간을 크게 줄일 수 있습니다.
- 메모리 효율성 (Memory Efficiency): PEFT는 전체 모델을 복제할 필요 없이, task별로 작은 prefix 또는 adapter 모듈만 저장하면 됩니다. 이는 메모리 사용량을 줄여 여러 task를 동시에 처리하거나, 자원 제약적인 환경에서 모델을 실행하는 데 유리합니다.
- 의미론적 일관성 유지 (Semantic Consistency)
- Pre-trained LM 을 그대로 사용할 경우, 생성된 텍스트가 원래 짧은 텍스트의 도메인에서 벗어나거나, 의도한 주제를 부분적으로만 다루는 문제가 발생할 수 있습니다.
- PEFT를 사용하면 LM을 특정 task에 맞게 조정하여 생성된 텍스트의 의미론적 일관성을 높일 수 있습니다.
특히 Prefix Tuning은 LM이 생성하는 텍스트에서 발생할 수 있는 의미론적 불일치(semantic drift) 문제를 완화하는 데 도움이 됩니다. - Prefix Tuning은 task-specific한 prefix를 학습하여 LM이 특정 task에 집중하도록 유도하고, 불필요한 정보 생성을 억제합니다.
- Task-Specific 특징 추출 (Task-Specific Feature Extraction)
- PEFT를 통해 LM은 topic modeling에 필요한 task-specific한 특징을 더 잘 학습할 수 있습니다.
- CTM과 같이 pre-trained LM을 feature extractor로 사용하는 경우, LM이 추출하는 특징이 topic modeling에 최적화되어 있지 않을 수 있습니다. PEFT를 사용하면 LM이 topic modeling에 필요한 특징을 더 잘 학습하도록 유도할 수 있습니다.
Experiments
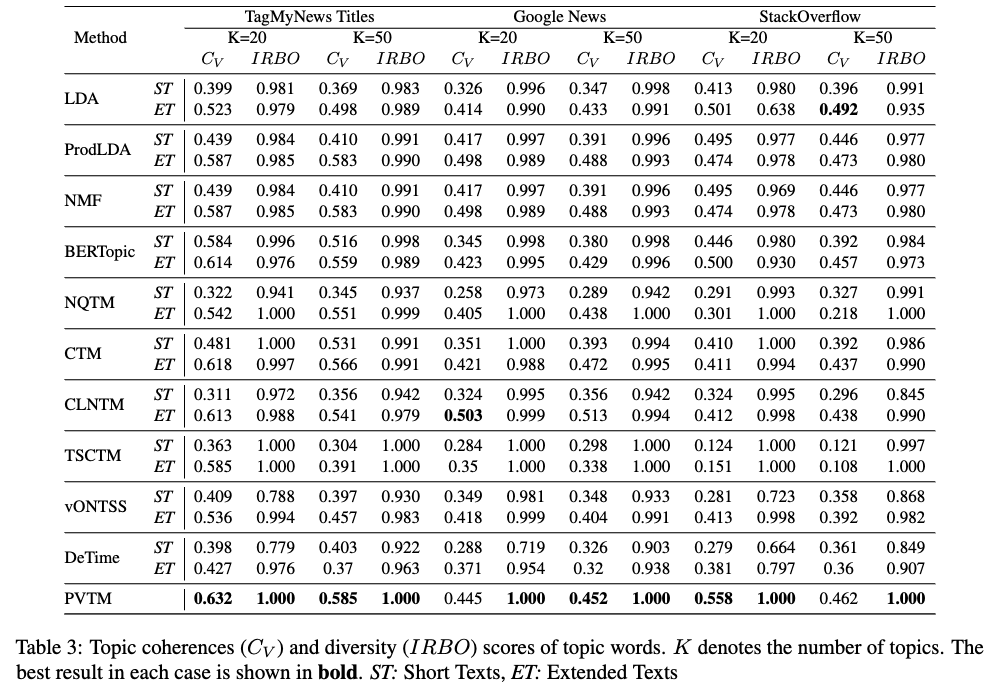
Topic Quality Evaluation
- LLM 확장 텍스트의 효과
LLM을 사용하여 짧은 텍스트를 확장했을 때, 토픽 모델의 성능이 향상되었습니다.
확장된 텍스트를 사용했을 때, 토픽의 일관성이 크게 향상되었고 다양성도 비슷하게 유지되었습니다. 이는 LLM이 짧은 텍스트에 문맥 정보를 풍부하게 추가하여 토픽 모델이 더 나은 품질의 토픽을 발견하도록 돕는다는 것을 의미합니다. - 토픽 품질과 정확성의 차이: 토픽 품질 점수가 높다고 해서 항상 추출된 토픽이 목표 데이터셋을 정확하게 나타내는 것은 아닙니다. LLM이 생성한 텍스트로 인해 토픽이 원래의 주제에서 벗어날 수 있습니다.
- 제안된 PVTM 모델의 성능
PVTM 모델은 대부분의 경우, 짧은 텍스트와 확장된 텍스트 모두에 비해 토픽 품질 점수가 향상되었습니다. 특히 coherence score(CV)와 diversity score(IRBO) 측면에서 다른 baseline 모델보다 성능이 크게 향상되었습니다.
TagMyNews 데이터셋에서 PVTM 모델의 CV 점수는 가장 유사한 모델인 CTM과 비교했을 때 0.618에서 0.632로 증가했습니다 (K=20 topics).
PVTM 모델의 다양한 입력 및 출력 유형에 따른 토픽 품질 결과는 Appendix A.2에서 추가적으로 논의됩니다. - 정리: LLM을 사용하여 짧은 텍스트를 확장하는 것은 토픽 모델링 성능을 향상시키는 데 도움이 되지만, 생성된 텍스트가 원래 주제에서 벗어날 수 있다는 점을 고려해야 합니다. PVTM 모델은 이러한 문제를 해결하고 토픽 품질을 더욱 향상시키는 데 효과적입니다.
Text Classification Evaluation

- LLM의 한계
- LLM(Large Language Model, 거대 언어 모델)은 특정 데이터에 대해 fine-tuning(미세 조정)되지 않은 경우, 생성된 텍스트가 원래 문서의 주제를 제대로 반영하지 못하거나, 주제에서 벗어나는 경향이 있습니다.
- 특히 StackOverflow 데이터셋처럼 특정 기술 분야에 대한 내용을 다룰 때, LLM은 일반적인(general) 주제의 단어를 생성할 가능성이 높습니다.
- 이로 인해 확장된 텍스트에서 학습된 주제가 원본 문서를 제대로 나타내지 못하여 분류 성능이 저하될 수 있습니다.
- PVTM의 장점
- PVTM은 생성된 텍스트와 함께 원본 텍스트를 활용하여 학습합니다. LLM이 생성한 텍스트를 직접 입력으로 사용하는 대신, 짧은 텍스트를 입력으로 사용하여 LLM이 생성한 긴 텍스트를 재구성하도록 학습합니다.
이를 통해 원본 데이터의 무결성을 유지하고, 관련 없는 정보가 유입될 위험을 줄입니다. 즉, LLM이 생성한 텍스트의 주제가 원본에서 벗어나는 문제를 완화합니다. - Prefix Tuning 방법을 사용하여 작은 언어 모델(LM)을 미세 조정함으로써, 계산 비용을 줄이면서도 특정 작업에 필요한 도메인 지식을 효과적으로 학습합니다.
- VAE 를 사용하여 잠재 공간에서 토픽을 추출하고, LLM이 생성한 텍스트를 재구성하는 방식으로 학습합니다.
- PVTM은 생성된 텍스트와 함께 원본 텍스트를 활용하여 학습합니다. LLM이 생성한 텍스트를 직접 입력으로 사용하는 대신, 짧은 텍스트를 입력으로 사용하여 LLM이 생성한 긴 텍스트를 재구성하도록 학습합니다.
- 결론: PVTM은 LLM의 생성 능력을 활용하면서도, 원본 텍스트의 정보를 보존하고 주제가 벗어나는 문제를 해결하여 분류 정확도를 향상시킵니다.
Topic Examples Evaluation

- CLNTM: 짧은 텍스트로 학습했을 때 반복적인 단어가 많이 나타나는 경향이 있습니다.
- CTM: 짧은 텍스트로 학습했을 때 다양한 토픽을 생성하지만, 정보가 부족하고 일관성이 떨어지는 경향이 있습니다 (예: iOS와 일반 애플리케이션 등 여러 토픽이 혼합됨).
- LLM으로 생성된 긴 텍스트: 반복적인 단어가 적고 일관성이 높지만, "number"나 "size"와 같은 일반적인 단어가 나타나는 경향이 있습니다.
- PVTM: 반복적이지 않으면서도 유용한 정보를 제공하는 토픽을 생성합니다. 예를 들어, 데이터베이스, 셸(Shell), 웹 프로그래밍과 같은 주제를 쉽게 파악할 수 있습니다.
Conclusion
- 문제 정의: 이 논문은 짧은 텍스트(예: 트윗, 뉴스 제목)에 대한 토픽 모델링의 어려움을 다룹니다. 짧은 텍스트는 문맥 정보가 부족하여 기존 토픽 모델링 방법으로는 효과적인 주제 추출이 어렵다는 문제가 있습니다.
- 접근 방식: 이 연구에서는 짧은 텍스트의 입력 표현을 개선하는 데 초점을 맞춥니다. 이는 모델이 제한된 문맥 정보에도 불구하고 잠재된 주제를 더 잘 파악할 수 있도록 하기 위함입니다. 이를 위해 제안된 PVTM 모델은 LLM 을 통해 확장된 긴 텍스트를 reconstruction 하기 위한 objective 로 학습됩니다.
- Data sparsity problem 해결: 짧은 텍스트의 제한된 단어 수로 인해 발생하는 데이터 희소성 문제를 해결하여 더 효과적인 토픽 모델링 프레임워크를 개발하는 것을 목표로 합니다.
Limitations
- LLM 활용의 문제점
- 제안된 프레임워크는 LLM을 사용하여 짧은 텍스트를 확장하는데, LLM이 생성하는 텍스트가 원래 텍스트의 도메인을 벗어나거나 (out-of-domain) 관련 없는 내용을 포함할 수 있습니다.
- 이는 생성된 토픽의 대표성을 떨어뜨려 토픽 모델링 결과의 품질을 저하할 수 있습니다.
- 특히 특정 분야에 대한 전문적인 내용을 다루는 텍스트의 경우, LLM이 일반적인 텍스트를 생성하는 경향이 있어 문제가 더 심각해질 수 있습니다.
- PVTM 의 한계
- 제안된 PVTM 이 이러한 문제를 해결하려고 시도하지만, 데이터가 매우 희소한 (extreme sparsity) 경우에는 제대로 작동하지 않을 수 있습니다.
- TagMyNews 데이터셋에 대한 실험에서 이러한 한계가 관찰되었습니다.
- Future Work
- LLM의 텍스트 생성 과정을 제어하여 대상 도메인과 관련된 텍스트를 생성하도록 하는 것이 중요합니다.
- 이는 생성된 토픽의 품질을 향상시키고, 토픽 모델링의 성능을 개선하는 데 도움이 될 수 있습니다.
- 정리: LLM을 사용한 텍스트 생성 시 발생할 수 있는 문제점과 PVTM 모델의 한계를 해결하기 위해, 향후 연구에서는 LLM의 생성 과정을 제어하여 대상 도메인에 더 적합한 텍스트를 생성하는 방향으로 나아가야 함을 강조합니다.
Reference
[1] Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning (Neurips 2023)