
Improved Graph Contrastive Learning for Short Text Classification (AAAI 2024)
Abstract
- Short text classification: 짧은 텍스트 분류는 의미적 희소성 및 레이블된 데이터 부족 (label sparsity) 으로 인해 더 어려운 과제이다.
- Related works and several Issues: 기존의 연구들은 그래프 학습과 대조 학습을 결합 (GCL, graph contrastive learning) 하여 짧은 텍스트 분류의 문제점을 해결하려 했지만, 다음과 같은 몇 가지 한계가 있었습니다.
- Data augmentation: 증강된 뷰를 생성하는 과정에서 텍스트 내의 의미 구조가 손상될 수 있으며, 노이즈로 인해 부정적인 영향이 발생할 수 있습니다.
- 클러스터링 특징 무시: 레이블이 없는 데이터에서 클러스터링에 유리한 특징을 무시하고, 소수의 유용한 레이블된 데이터에 있는 사전 정보를 충분히 활용하지 못합니다.
- Proposed method: 이러한 한계를 해결하기 위해, 본 논문에서는 개선된 그래프 대조 학습을 활용한 새로운 모델인 GIFT(Improved Graph contrastIve learning for short text classiFicaTion)를 제안합니다.
- Heterogeneous graph construction: 내부 말뭉치에서 마이닝하고 외부 지식 그래프를 도입하여 여러 구성 요소 그래프를 포함하는 heterogeneous graph 를 구성합니다.
- SVD를 이용한 data augmentation: 특이값 분해(SVD)를 사용하여 그래프 대조 학습을 위한 증강된 뷰를 생성합니다.
- Constrained K-means: 레이블된 텍스트에 대해 제약된 k-means를 사용하여 클러스터링에 유리한 특징을 학습하고, 더 나은 범주 경계를 얻도록 돕습니다.
Introduction
- Two main issues
- Traditional text augmentation method for contrastive learning
- Random word deletion(단어 무작위 삭제) 또는 random noise injection(무작위 노이즈 주입)과 같은 전통적인 텍스트 증강 방법을 사용합니다.
문제점: 이러한 방법들은 텍스트의 의미를 왜곡시키고 정보 손실을 초래할 수 있습니다 (Zhang et al. 2021).
예시: 영화 리뷰 문장 "this film is not funny"에서 "not"을 삭제하면 문장의 의미가 완전히 바뀌어 오해를 일으킬 수 있습니다. - 기존의 Graph 증강 방법의 문제점
정의: 텍스트 그래프에서 edge/node에 perturbation을 가하는 graph 증강 방법을 사용합니다.
문제점: 이는 필연적으로 노이즈를 발생시킵니다 (Yu et al. 2022).
예시: 중요한 의미적 연결(semantic edge)을 제거하면 문장의 의미가 크게 변경되어 augmented graph가 원래 그래프와 거의 유사성을 공유하지 못하게 되어 모델 학습을 오도할 수 있습니다. - 제안하는 해결 방향
- SVD를 이용한 특징 추출 및 노이즈 제거
원본 텍스트의 중요한 의미 구조를 보존하기 위해, term-document (TD) 행렬 에 Singular Value Decomposition (SVD)을 수행하여 재구성된 TD 행렬을 얻습니다. 이는 각 component graph의 augmented view를 생성하는 데 사용됩니다. 이 접근 방식은 TD 행렬 내에 잠재된 의미 구조가 존재한다고 가정하는 Latent Semantic Indexing (LSI) Latent semantic analysis에서 영감을 받았습니다.
SVD를 통해 차원 축소를 수행함으로써, 단어 오용이나 관련 없는 단어의 존재와 같은 노이즈를 제거하면서 유용한 정보를 보존합니다. Truncated SVD를 채택하여 TD 행렬의 low-rank approximation을 얻고, global TD co-occurrence 신호를 캡처하여 contrastive learning (CL) 학습 과정에 주입합니다.
- SVD를 이용한 특징 추출 및 노이즈 제거
- Random word deletion(단어 무작위 삭제) 또는 random noise injection(무작위 노이즈 주입)과 같은 전통적인 텍스트 증강 방법을 사용합니다.
- Classical instance discrimination CL paradigm such as Mutual Information Maximization
- Negative pair의 의미 유사성: 기존의 인스턴스 식별 CL은 같은 출처에서 생성된 positive pair 간의 상호 정보량을 최대화하고, 다른 인스턴스에서 온 negative pair는 멀리 떨어뜨립니다(Chen et al., 2020). 하지만 이 과정에서 의미적으로 유사한 negative pair들이 임베딩 공간에서 멀어지게 되어 표현 학습에 부정적인 영향을 미칠 수 있습니다(Li et al., 2021).
- 클러스터링 특성 무시: 더 나은 일반화를 위해서는 같은 클래스 내 샘플들의 유사성을 포착하고, 다른 클래스의 샘플들과 대조하는 것이 중요합니다. 즉, 데이터셋 내에 존재하는 클러스터링 친화적인 특징을 활용해야 합니다.
- Unlabeled 데이터 활용의 어려움: 레이블이 없는 짧은 텍스트 데이터에 기존의 k-means clustering 알고리즘을 적용하는 것은 자연스러운 접근 방식일 수 있지만, 제한된 레이블 데이터로부터 얻은 숨겨진 클래스 레이블의 분포에 대한 사전 지식을 활용하지 못합니다.
- 제안하는 해결 방향
- 사전 지식 활용: 제한된 레이블 데이터를 활용하여 클러스터링 과정을 안내하고, 탐색 공간에서 유리한 영역을 탐색하도록 편향시켜 최적의 솔루션으로 수렴할 위험을 줄여야 합니다. (Heterogeneous graph, Constrained K-means)
- 클러스터링 기반 학습: 유사한 의미를 가진 unlabeled 짧은 텍스트들이 동일한 약한 레이블을 공유하도록 하여, 다른 범주 간의 비교를 용이하게 해야 합니다. 클러스터링 -> 수도레이블링 -> supervised contrastive learning !
- Traditional text augmentation method for contrastive learning
Main Contributions
- Short text classification (STC) 를 위한 GIFT 모델 제안: GIFT can learn better short text representations and solve
the challenges of existing models. - CL 을 위한 새로운 data augmentation method, 그리고 기존의 k-means clustering 기반 수도레이블링을 더 개선한 cluster-oriented CL 제안
- 벤치마크 데이터셋에서 다양한 실험을 통해 저자들이 제안하는 GIFT 의 효과를 보였음
Related Work
Short Text Classification
- STC의 고유한 어려움
- 짧은 텍스트는 길이가 짧고 문법 구조가 엄격하지 않아 의미를 파악하기 어렵습니다.
- limited length and lack of strict syntactic structure
- 기존 방법들의 한계: 기존 방법들은 외부 말뭉치에서 잠재 토픽을 추출하거나 지식베이스에서 엔티티 정보를 가져와 의미를 풍부하게 하려고 시도했지만, 부족한 labeled 데이터 문제를 해결하지 못해 만족스러운 결과를 얻지 못했습니다.
- GNN 기반 모델의 등장: 그래프 신경망(GNN) 기반 모델은 텍스트를 단어 또는 구문 간의 관계를 나타내는 그래프로 표현하여 더 나은 성능을 보였습니다. 이러한 모델은 그래프에서 메시지 전달을 통해 레이블 정보를 전파합니다.
- CL과 GNN의 결합
- 최근 연구[1] 에서는 unsupervised representation learning에서 contrastive learning(CL)의 성공에 영감을 받아, GNN과 CL을 결합하여 unlabeled 데이터에서 self-supervised 신호를 활용하고 유용한 특징을 추출하는 방법을 모색했습니다.
- [1] 는 heterogeneous 그래프 어텐션 네트워크와 대조 학습을 통해 짧은 텍스트 분류를 수행했습니다.
- CL 기반 방법의 문제점: 이러한 방법들의 효과는 생성된 contrastive view에 크게 의존하며, view 생성 방식에 따라 잘못된 self-supervised 신호가 발생하여 모델 학습을 방해할 수 있습니다.
- 개선 방향: 따라서 self-supervised 신호의 정확도를 높이는 것이 중요하며, 본 논문에서는 이 문제를 해결하기 위한 새로운 모델을 제시합니다.
Contrastive Learning
- Instance discrimination (인스턴스 판별): 초기 CL 모델들은 주로 unsupervised 방식으로 인스턴스들을 구별하는 데 초점을 맞췄습니다.
- Category discrimination (범주 판별): 이후 모델들은 레이블 정보를 통합하여 범주를 구별하는 fully supervised CL 패러다임을 제안했습니다 (Supervised Contrastive Learning).
- Prototype-based approach (프로토타입 기반 접근 방식): Image classfication task 를 위한 비지도학습 기반 인코더 학습에서는 인스턴스의 embedding을 해당 프로토타입에 가깝게 만들고, 다른 프로토타입에서는 멀어지도록 하는 프로토타입 개념이 도입되었습니다.
Low-Rankness in Data Mining
- Low-rankness: 행렬(matrices)이 가지는 속성으로, 행 또는 열 간의 상관관계를 나타냅니다 (Robust Tensor Graph Convolutional Networks via T-SVD based Graph Augmentation). 데이터 마이닝에서 low-rankness는 주로 특이값 분해(SVD)와 같은 행렬 분해(matrix decomposition) 기법과 관련되어 사용됩니다.
- 행렬 분해를 통한 Low-rankness 활용: 높은 랭크(high-rank)의 행렬을 low-rank 행렬로 근사화(approximate)하여, 데이터의 차원 축소(dimension reduction)를 수행할 수 있습니다. 이를 통해 숨겨진(latent) 특징이나 구조를 추출하고, 노이즈나 불필요한 정보를 제거할 수 있습니다 (Latent semantic analysis).
- Low-rankness의 활용 예시
- Graph adversarial attack: All You Need Is Low (Rank): Defending Against Adversarial Attacks on Graphs에서는 인접 행렬(adjacency matrix)의 low-rank 근사를 통해 그래프의 higher-order component를 제거합니다.
- Graph-based recommendation: LightGCL [2] 에서는 사용자-아이템 상호 작용 행렬에 low-rank approximation을 적용하여, global collaborative context를 주입하고 그래프 증강(graph augmentation)을 유도합니다.
Method
Graph Construction
저자들은 GNN-based STC 프레임워크를 위해 3가지 유형의 그래프를 구축하여 텍스트의 의미론적, 구문론적 정보를 최대한 활용하고자 합니다. word graph, entity graph, POS tag graph 를 construction 합니다.
- 단어 그래프 (Word Graph)

- V: 텍스트를 구성하는 단어들을 노드로 표현합니다.
- X: 단어 임베딩(word embeddings)입니다. 각 단어를 벡터로 표현하며, 여기서는 GloVe 의 pre-trained 단어 임베딩을 사용하여 초기화합니다.
- A: adjacency matrix 입니다. 단어 간의 동시 발생 통계(co-occurrence statistics)를 기반으로 단어 간의 관계를 나타냅니다. 각 값은 점별 상호 정보량(Point-wise Mutual Information, PMI)을 사용하여 계산됩니다.
- i 번째 단어와 j 번째 단어 사이의 PMI 값을 계산하고, 0보다 작은 경우 0으로 설정합니다. PMI는 두 단어가 동시에 나타나는 경향을 측정하는 방법입니다. PMI 값이 클수록 두 단어는 더 강한 연관성을 가집니다.
- 개체 그래프 (Entity Graph)
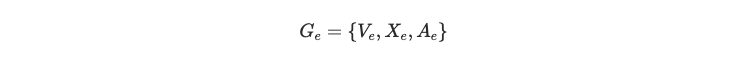
- V: 개체(entities) 집합입니다. 외부 지식 그래프(knowledge graphs)에 존재하는 개체들을 노드로 표현합니다.
- X: entity 임베딩입니다. 각 개체를 벡터로 표현하며, 여기서는 TransE 를 사용하여 초기화합니다. TransE 는 지식 그래프 (knowledge graph) 의 관계를 임베딩하는 방법입니다.
- A: 인접 행렬입니다. 개체 쌍(entity pair) 간의 코사인 유사도(cosine similarity)를 기반으로 개체 간의 관계를 나타냅니다.
- i 번째 개체와 j 번째 개체 사이의 코사인 유사도를 계산하고, 0보다 작은 경우 0으로 설정합니다.
- POS 태그 그래프 (POS Tag Graph)

- V: POS(Part-of-Speech) 태그 집합입니다. 명사, 동사 등과 같은 POS 태그들을 노드로 표현합니다. POS 태그는 단어의 구문 역할을 지정하여 의미의 모호성 (ambiguity) 을 제거하는 데 도움을 줍니다.
- X: 태그 노드 특징(tag node features)입니다. 각 태그를 벡터로 표현하며, 원-핫 벡터(one-hot vectors)를 사용하여 초기화합니다.
- A: 인접 행렬입니다. 단어 그래프와 마찬가지로 PMI를 사용하여 계산합니다.
- i 번째 POS 태그와 j 번째 POS 태그 사이의 PMI 값을 계산하고, 0보다 작은 경우 0으로 설정합니다.
이러한 그래프들을 결합하여 텍스트의 다양한 측면을 포착하고, 특히 짧은 텍스트에서 발생할 수 있는 semantic sparsity problem 를 해결하고자 합니다.
이후에는 이러한 그래프들을 GNN(Graph Neural Network)을 사용하여 인코딩하여 노드 간의 관계와 특징 정보를 활용합니다.
이러한 graph 기반의 접근 방식은 짧은 텍스트 분류(STC) task 에서 더 나은 성능을 얻기 위한 중요한 단계입니다.
Text Representation Learning
- GCN 을 통한 그래프 인코딩
- H: 노드의 임베딩
- W: 학습 가능한 파라미터

- 텍스트 임베딩
- M: 텍스트 임베딩을 얻기 위해, text-specific matrix (TD matrix) 를 구성
- 여기서는 단어와 POS 태그의 경우에만 해당합니다.
- M 는 텍스트와 단어 또는 POS 태그 사이의 TF-IDF 값을 나타냅니다. 여기서 N 은 텍스트 (문서) 의 수입니다.
- Entity 의 경우: M (text-specific matrix) 에서 i번째 텍스트가 j번째 개체를 포함하면 1, 그렇지 않으면 0입니다.

Z_org는 세 가지 텍스트 관련 feature를 concat 하여 얻은 text representation 입니다.
Improved Graph Contrastive Learning
- 기존의 Contrastive Learning (CL) 방법들의 문제점을 개선하기 위해 SVD 를 사용하여 텍스트 뷰 (augmented view) 를 생성하고, 이를 통해 텍스트 분류 성능을 향상시키는 방법을 설명합니다.
- 기존 텍스트 분류 방법들은 augmented view 생성 시 중요한 의미 정보를 손실하거나 노이즈를 추가하여 Contrastive Learning (CL) 학습을 방해하는 문제가 있었습니다. 이를 해결하기 위해 이 논문에서 저자들은 SVD를 사용하여 TD(Term-Document) 행렬을 분해하고, 차원 축소 및 노이즈 제거를 수행하여 augmented view 를 생성합니다.
- SVD를 통한 목표
- TD (text-specific Term-Document metrix) Co-occurrence 신호 강화: 텍스트 표현에 중요한 TD co-occurrence 신호를 강화하고 노이즈 신호를 줄입니다.
- Semantic ambiguity 해결: 지역적인 TD co-occurrence 신호의 한계를 극복하기 위해, 전체 TD 쌍에서 global TD co-occurrence 신호를 활용합니다.
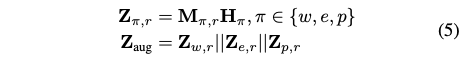
식 (6) 의 CL 손실 함수는 feature space에서 positive sample 쌍은 더 가깝게, negative sample 쌍은 더 멀리 떨어지도록 학습하여, downstream task에 더 구별력 있는 embedding을 유도합니다.

-> 정리: SVD를 사용하여 TD (term-document) matrix 의 차원을 축소하고 노이즈를 제거함으로써 augmented text representation 의 품질을 향상시키고, 이를 통해 graph contrastive learning의 효과를 높여 텍스트 분류 성능을 개선하는 방법을 제안합니다.
Cluster-oriented Contrastive Learning
- 기존 CL 패러다임의 한계: k-means 와 같은 클러스터링을 이용하여, pseudo-labeling 하여 supvervised CL 을 할 수 있는데, 데이터 내 클러스터링 특징을 무시하고 개별 인스턴스만 고려하여 유사한 의미의 샘플들을 잘못된 negative pair로 간주하는 문제점을 지적합니다. 즉, clustering 결과를 100% 신뢰할 수 없습니다. (false negative 존재할 수 있습니다.) 이는 모델이 데이터의 전반적인 구조를 파악하는 데 방해가 됩니다.
- 제안하는 해결책: Apply constrained k-means
제한된 labeled 데이터에서 얻은 사전 지식을 활용하여 unlabeled 데이터에 약한(weak) 라벨을 할당합니다.
Constrained seed k-means 알고리즘을 사용하여 클러스터링 친화적인 특징을 찾고, 더 나은 클래스 경계를 얻도록 돕습니다. - Constrained seed k-means 알고리즘
기존 k-means 알고리즘과 달리, 초기 중심점을 무작위로 선택하지 않고 labeled 데이터(seed samples)를 사용하여 초기 클러스터를 형성합니다. 클러스터 업데이트 시, seed samples의 클러스터 할당은 고정하고 non-seed samples만 업데이트합니다.
이후 표준 k-means 알고리즘과 동일한 단계를 수행합니다.
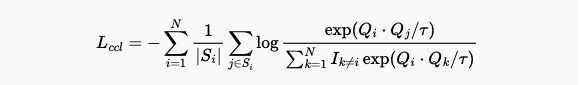
Experiments
Datasets
- Twitter: NLTK에서 수집한 두 가지 감정을 표현하는 다수의 트윗으로 구성된 이진 분류 데이터 세트입니다.
- MR (Movie Reviews): 영화 리뷰에 대한 이진 분류 데이터 세트이며, 각 리뷰는 긍정 또는 부정으로 레이블이 지정된 문장을 포함합니다.
- Snippets: Google 검색 엔진에서 반환된 웹 검색 스니펫으로 구성됩니다.
- StackOverflow: StackOverflow 웹사이트에서 크롤링한 20개의 질문 제목 카테고리를 포함합니다.
Baselines
- Traditional methods
- TF-IDF+SVM: TF-IDF (Term Frequency-Inverse Document Frequency) 특징과 SVM (Support Vector Machine)을 결합한 모델입니다. TF-IDF는 텍스트 내 단어의 중요도를 평가하는 데 사용되며, SVM은 분류를 위한 지도 학습 알고리즘입니다.
- LDA+SVM: LDA (Latent Dirichlet Allocation) 토픽 모델링 기법과 SVM을 결합한 모델. LDA는 문서의 잠재된 토픽을 추출하는 데 사용됩니다.
- PTE: PTE (Predictive Text Embedding)는 이종 텍스트 그래프에서 단어 임베딩을 학습하고, 이를 평균내어 문서 임베딩으로 사용하는 모델.
- DNN-based methods
- CNN: CNN (Convolutional Neural Network)은 사전 훈련된 GloVe 단어 임베딩으로 초기화된 텍스트를 입력받아 특징을 추출하고 분류하는 모델입니다.
- LSTM: LSTM (Long Short-Term Memory)은 순환 신경망의 한 종류로, 텍스트의 순차적인 정보를 처리하는 데 효과적입니다. CNN과 마찬가지로 GloVe 임베딩을 사용하여 초기화됩니다.
- BERT, RoBERTa: BERT (Bidirectional Encoder Representations from Transformers)와 RoBERTa는 대규모 코퍼스로 사전 훈련된 트랜스포머 기반 모델입니다. 문맥적 임베딩을 생성하며, 짧은 텍스트 분류를 위해 추가적인 분류기와 함께 미세 조정됩니다.
- Graph-baed methods: TLGNN, HyperGAT, TextING, DADGNN, TextGCN: 다양한 그래프 신경망 (GNN) 기반 모델들이 포함됩니다. 이러한 모델들은 텍스트를 그래프 구조로 표현하고, GNN을 사용하여 노드 간의 관계를 학습합니다.
- Deep short text methods: STCKA, STGCN, HGAT, SHINE, NC-HGAT: 짧은 텍스트 분류를 위해 특별히 설계된 심층 모델들입니다.
Implementation Details
- GCN: 2-layer GCN을 사용하여 각 component graph를 인코딩합니다. Hidden dimension은 128로 설정됩니다.
- Contrastive Learning(CL): CL과 cluster-oriented CL에서 temperature parameter 는 0.5로 설정됩니다. Projection head는 hidden layer를 가진 MLP 로 구현됩니다.
- SVD
- 큰 TD(Term-Document) 행렬에 SVD를 직접 수행하는 대신, randomized SVD 를 사용하여 계산 복잡도를 줄입니다.
Randomized SVD는 입력 행렬의 주요 특징을 담는 subspace를 random sampling을 통해 찾고, 그 subspace에 행렬을 projection한 다음 SVD를 수행합니다. - Approximate 행렬의 required rank는 15로 설정됩니다.
- 큰 TD(Term-Document) 행렬에 SVD를 직접 수행하는 대신, randomized SVD 를 사용하여 계산 복잡도를 줄입니다.
- Loss function: Loss function의 control parameter 는 모두 0.5로 설정됩니다.
- 최적화 방법: Adam 을 사용하여 GIFT 모델을 최적화하며, learning rate는 0.001입니다.
- Baselines: 다른 baseline 모델들은 default parameter를 사용하거나, grid search를 통해 최적의 parameter를 찾습니다.
- 평가 지표: 모델 평가 지표로는 accuracy(ACC)와 macro F1-score(F1)를 사용합니다.
Results
Model Performance

- GIFT 모델의 우수성
제안하는 GIFT 모델이 STC(Short Text Classification) task에서 가장 좋은 성능을 보임을 강조합니다.
다양한 평가 데이터셋에서 관련 메트릭(정확도, F1-score) 기준으로 다른 모델들보다 우수한 성능을 보입니다. - 성능 향상 요인
SVD를 활용한 데이터 증강: 텍스트 특정 TD(Term-Document) 행렬에 SVD를 적용하여 텍스트의 augmented view를 얻습니다. 이는 유용한 정보를 보존하고 노이즈를 제거합니다.- Global TD co-occurrence signal 활용: CL(Contrastive Learning) 과정에서 잘못된 방향으로 학습될 수 있는 부분을 보정하기 위해 global TD co-occurrence 신호를 도입합니다.
- Weak label assignments: 소수의 레이블된 텍스트에 포함된 사전 지식을 활용하여 수많은 레이블되지 않은 텍스트에 약한 레이블을 할당합니다. 이는 클러스터링 친화적인 특징을 활용하고 instance discrimination CL 패러다임으로 인한 false negative 문제를 완화합니다.
- Heterogeneous Graph 구성: 텍스트 자체의 의미 및 구문 정보와 외부 지식 그래프의 정보를 최대한 활용하기 위해 여러 component graph로 구성된 heterogeneous graph를 구성합니다.
- Deep short text models
- GNN과 결합된 심층 숏 텍스트 모델(HGAT, NC-HGAT)이 다른 모델에 비해 경쟁력 있는 성능을 보입니다.
- 이는 이러한 모델들이 STC task를 위해 특별히 설계되었고 다양한 보조 지식을 도입하여 short text representation 을 풍부하게 하기 때문입니다.
- NC-HGAT는 corpus-level 그래프에 random perturbation을 적용한 CL을 수행하지만, GIFT 모델보다 성능이 떨어집니다.
- 이는 NC-HGAT의 augmented view가 텍스트의 중요한 정보를 버릴 수 있으며, 이는 모델 학습을 저해하기 때문입니다.
- Pre-trained language encoder models 의 한계: BERT, RoBERTa와 같이 대규모 corpus에서 일반적인 지식을 통합한 fine-tuning된 사전 학습 모델은 레이블된 텍스트 부족으로 인해 특정 task에서 만족스럽지 못한 성능을 보입니다.
- Graph 기반 모델의 장점: Graph 기반 모델은 구문 구조 정보를 명시적으로 모델링하고 레이블 전파의 이점을 얻을 수 있기 때문에 경쟁력이 있습니다.
Ablation Study
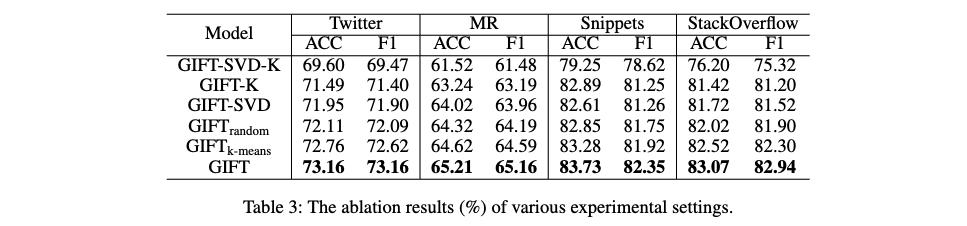
- GIFT-SVD-K
- SVD 기반의 Contrastive Learning (CL)과 constrained seed k-means를 사용한 cluster-oriented CL을 모두 제거합니다.
- 제거 후에는 cross-entropy loss를 사용하여 텍스트 representation을 직접 분류합니다.
- 이는 GIFT 모델의 핵심 구성 요소인 CL과 클러스터링 방식이 없는 기본적인 모델 성능을 측정하기 위함입니다.
- GIFT-K: cluster-oriented CL만 제거하고, 나머지 부분은 원래대로 유지합니다.
- GIFT-SVD
- SVD를 사용한 CL만 제거하고, 나머지 부분은 원래대로 유지합니다.
- 이는 SVD 기반 CL이 모델 성능에 미치는 영향을 평가하기 위한 것입니다.
- GIFT (random)
- SVD를 random perturbations (TD 행렬에 무작위로 마스킹)으로 대체합니다.
- SVD를 통한 augmented view 생성 대신 무작위 노이즈를 사용했을 때의 성능 변화를 비교합니다.
- 이는 SVD가 단순히 노이즈를 추가하는 것 이상의 효과가 있는지 확인하기 위함입니다.
- GIFT (k-means)
- cluster-oriented CL에서 constrained seed k-means를 기존 k-means 알고리즘으로 대체합니다.
- Constrained seed k-means가 초기 클러스터 중심 설정에 prior knowledge를 활용하는 반면, 기존 k-means는 무작위로 초기 중심을 설정합니다. 따라서 이 실험은 constrained seed k-means의 효과를 평가합니다.
- 실험 결과: 모든 구성 요소를 제거했을 때 성능이 저하되었으며, GIFT 모델이 GIFT (k-means) 와 GIFT (random) 보다 성능이 우수했습니다. 이는 각 요소가 GIFT 모델에서 중요한 역할을 수행하며, SVD와 constrained seed k-means가 무작위적인 방법이나 기존 클러스터링 방법보다 효과적임을 보여줍니다.
Hyperparameter Study
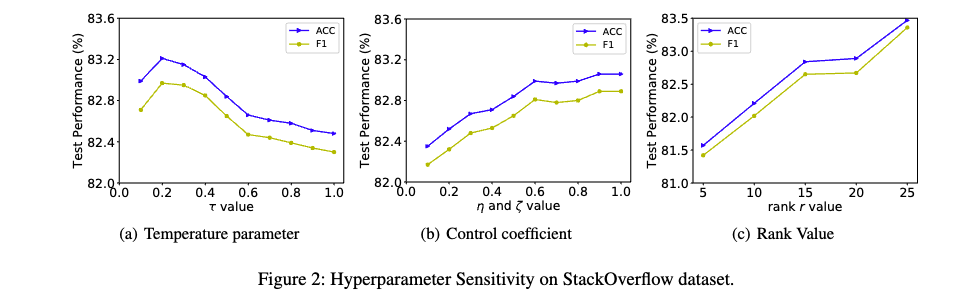
- Temperature (τ)
- Temperature 가 증가함에 따라 모델 성능이 처음에는 증가하다가 감소하는 경향을 보입니다.
- 낮은 Temperature: 모델이 hard negative sample에 집중하게 되어 유사한 의미를 공유하는 긍정적인 샘플(positive sample)들을 멀리 밀어낼 수 있습니다. 즉, 긍정적인 샘플을 제대로 학습하지 못할 가능성이 있습니다.
- 높은 Temperature: 모델이 negative sample들을 동등하게 취급하여 구별 능력을 감소시킬 수 있습니다. 즉, negative sample들을 구별하는 데 어려움을 겪을 수 있습니다.
- 제어 계수 (Control Coefficients, η, ζ)
- 하이퍼파라미터 값이 증가함에 따라 결과가 증가하는 경향을 보입니다. η과 ζ가 증가함에 따라 두 종류의 Contrastive Learning (CL)이 최종 손실 함수에 미치는 기여도가 증가하기 때문입니다. 여기서 Contrastive Learning은 데이터 내의 유사성을 학습하는 방법입니다.
- 랭크 값 (Rank Value, r)
- 랭크 값 r이 증가함에 따라 결과가 증가하는 경향을 보입니다.
- 랭크 r이 증가함에 따라 증강된 Term-Document (TD) 행렬이 더 많은 글로벌 동시 발생 신호(global co-occurrence signals)를 캡처할 수 있기 때문입니다.
- 여기서 TD 행렬은 텍스트와 단어 간의 관계를 나타내는 행렬이며, SVD를 통해 차원 축소 및 노이즈 제거를 수행합니다.
Case Study

- GIFT 모델이 어떻게 단어와 문서 간의 연결을 재확립하는지 보여주는 사례 연구입니다.
- 2 Term-Document Matrix (TD Matrix): word-document and entity-document matrix
- SVD-reconstructed word-document matrix: SVD 를 통해 재구성된 단어-문서 행렬에서 GIFT 모델은 잠재적으로 중요한 단어와 문서 간의 연결을 재확립합니다. 예를 들어, "delightful"과 "honeyed"는 "sweet"을, "smile"은 "laugh"를 강화합니다.
- Entity-document matrix: Reconstructed entity-document matrix 에서는 "soul"과 문서 간의 연결이 다시 설정됩니다.
- Global co-occurrence information 는 짧은 텍스트를 정확하게 이해하는 데 중요한 역할을 합니다.
Conclusion
- GIFT 모델: 본 연구에서는 단문 텍스트 분류(STC)를 위한 새로운 모델인 GIFT를 제안합니다.
- SVD를 활용한 데이터 증강: GIFT 모델은 텍스트별 TD 행렬에 SVD를 적용하여 데이터의 augmented view를 얻는 접근 방식을 활용합니다.
- 이는 Contrastive Learning (CL)을 위함입니다.
- SVD (Singular Value Decomposition)
- TD 행렬은 텍스트(문서)와 단어 간의 관계를 나타내는 행렬입니다.
- SVD는 이 행렬을 분해하여 중요한 의미 구조를 추출하고 노이즈를 제거하는 데 사용됩니다.
- Cluster-Oriented CL
- 데이터에서 클러스터링 친화적인 특징을 탐색하기 위해 constrained k-means 기반의 클러스터 중심 Contrastive Learning을 통합합니다.
- Constrained k-means: 제한된 k-means 알고리즘을 사용하여 레이블이 없는 텍스트에 약한 레이블을 할당합니다. 이를 통해 클러스터링 정보를 Contrastive Learning에 통합합니다.
- SOTA performance: 광범위한 실험을 통해 제안된 모델이 다른 최첨단 모델보다 훨씬 우수한 성능을 보임을 입증했습니다.
- TL;DR: 이 논문에서는 short text classification task를 해결하기 위해 graph contrastive learning 을 개선한 GIFT라는 새로운 모델을 제안합니다. 이 모델은 SVD를 사용하여 텍스트의 augmented view를 생성하고, constrained k-means를 사용하여 클러스터링 친화적인 특징을 활용합니다. 다양한 실험에서 GIFT 모델이 baselines 모델보다 우수한 성능을 보임을 입증했습니다.
Reference
[1] Contrarning with heterogeneous graph attention networks on short text classification (IJCNN 2022)
[2] LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation (ICLR 2023)