[Paper Review] Groupwise Query Specialization and Quality-Aware Multi-Assignmentfor Transformer-based Visual Relationship Detection (CVPR 2024)

Groupwise Query Specialization and Quality-Aware Multi-Assignmentfor Transformer-based Visual Relationship Detection (CVPR 2024)
Abstract
- Visual Relationship Detection (VRD)은 이미지 내 객체들 [주체 (subject), 객체 (object)] 과 그들 사이의 관계(relationship)를 감지하는 컴퓨터 비전의 중요한 task입니다.
- 최근 Transformer 기반 아키텍처가 VRD 분야에서 상당한 발전을 이루었지만, 연구자들은 Transformer 기반 VRD 모델을 훈련하는 데 사용되는 기존의 라벨 할당 방식에서 두 가지 주요한 한계를 발견했습니다.
- 기존의 라벨 할당 방식의 한계
- Unspecialized Query Training (특화되지 않은 쿼리 학습)
- Issue: 기존 방식에서는 모델의 각 쿼리가 모든 종류의 관계(e.g., "앉아 있다", "들고 있다", "위에 있다")를 감지하도록 기대하고 훈련됩니다.
- 결과: 쿼리들이 특정 관계에 전문적으로 특화되기 어렵게 만들고, 이는 전반적으로 모호한 학습 신호를 제공합니다. 결과적으로 모델의 잠재력을 충분히 활용하지 못하게 됩니다.
- Insufficient Training (불충분한 학습)
- Issue: Ground-Truth (GT) 관계 하나가 오직 하나의 예측에만 할당됩니다. 따라서 모델이 GT에 매우 가깝거나 심지어 올바른 예측을 여러 개 하더라도, 그중 하나에만 GT가 할당되고 나머지 '괜찮은' 예측들은 '관계 없음'으로 할당되어 부정적인 학습 신호를 받게 됩니다.
- 결과: 이는 정확하거나 거의 정확한 예측들을 억제하여 모델의 학습을 저해합니다. 예를 들어, Visual Genome 벤치마크에서 고품질 예측의 약 45%가 '관계 없음'으로 잘못 할당됩니다.
- Unspecialized Query Training (특화되지 않은 쿼리 학습)
- 제안하는 해결책: SpeaQ (Groupwise Query Specialization and Quality-Aware Multi-Assignment)
- Groupwise Query Specialization (그룹별 쿼리 특화)
- 목표: 각 쿼리가 특정 관계에 전문적으로 특화되도록 훈련시킵니다.
- 모델의 모든 쿼리(queries)와 전체 관계(relations)를 서로 분리된 그룹으로 나눕니다.
- 특정 '쿼리 그룹'에 속한 쿼리는 오직 해당 '관계 그룹' 내의 관계들만을 감지하도록 학습 방향을 제시합니다.
- 기대 효과: 쿼리들이 여러 역할을 동시에 수행하며 겪는 어려움을 줄이고, 더 명확하고 집중된 학습 신호를 받아 특정 관계 감지에 '전문적'으로 특화될 수 있게 합니다.
- Quality-Aware Multi-Assignment (품질 인식 다중 할당)
- 목표: 모델이 풍부하고 적절한 학습 신호를 받을 수 있도록 합니다.
- 하나의 GT 관계에 대해 주체(subject), 객체(object), 그리고 그들 사이의 관계(relationship) 측면에서 GT와 상당히 유사한 여러 개의 예측이 있을 경우, 이 모든 "고품질 예측"에 해당 GT를 할당합니다.
- 기대 효과: 기존 방식처럼 '관계 없음'이라는 잘못된 부정적 신호를 받는 것을 방지하고, 모델이 올바른 예측에 대해 더 많은 긍정적 학습 신호를 받아 충분히 훈련될 수 있도록 돕습니다.
- Groupwise Query Specialization (그룹별 쿼리 특화)
- SpeaQ 의 실험 결과
- 실험 결과 및 분석에 따르면 SpeaQ는 '특화된' 쿼리를 효과적으로 훈련시켜 모델의 잠재력을 더 잘 활용하게 합니다.
- 이는 다양한 VRD 모델과 벤치마크에서 추가적인 추론 비용 없이 일관된 성능 향상을 가져오는 것으로 나타났습니다.
1. Introduction
- Issue 1: Unspecialized Query Training
- 모든 관계 감지 기대: 표준 할당 방식에서는 하나의 쿼리가 특정 관계에 집중하기보다는, 모든 가능한 관계를 감지하도록 훈련됩니다.
- 모호한 훈련 신호: 쿼리가 여러 역할을 동시에 수행해야 하므로, 훈련 신호가 모호해져 특정 역할에 전문화되기 어렵습니다. 예를 들어, 'on'과 'next to'처럼 의미가 다른 관계를 같은 쿼리가 학습해야 하는 상황이 발생할 수 있습니다.
- Long-tail 분포 악화: VRD 데이터셋의 '롱테일 속성(long-tailed property)'은 이러한 문제를 더욱 심화시킵니다. 특정 관계는 매우 자주 나타나고(common relations), 다른 관계는 매우 드물게 나타나기(rare relations) 때문에, 쿼리가 불균형한 훈련 신호 속에서
- 결과: 여러 관계 사이의 균형을 맞추기가 더욱 어려워지며 쿼리가 특정 관계에 특화되지 못하고, 모델의 용량(capacity)이 충분히 활용되지 않게 됩니다.
- Issue 2: Single GT Assignment Constraint
- GT의 단일 예측 할당: 표준 할당 방식의 제약 사항은 하나의 Ground Truth (GT)가 오직 하나의 예측에만 할당될 수 있다는 것입니다.
- '관계 없음'으로 처리되는 좋은 예측: 이로 인해 실제로는 정답에 매우 가깝거나 심지어 올바른 예측임에도 불구하고, 다른 더 좋은 예측이 GT를 가져가 버리면 해당 예측은 '관계 없음(no relation)'으로 할당됩니다.
- 억제되는 학습: 이러한 '관계 없음' 할당은 해당 예측에 대한 부정적인 신호를 제공하여, 모델이 올바른 예측을 억제하도록 만듭니다. 논문에서는 Visual Genome 벤치마크에서 모델이 훈련될 때 고품질 예측의 약 45%가 '관계 없음'으로 할당되었다고 언급하며 이 문제의 심각성을 강조합니다.
- 결과: 모델이 잠재적으로 유용한 학습 기회를 잃게 되어 훈련 효율성이 저하됩니다.
- SpeaQ 의 구성 요소
- Groupwise Query Specialization (그룹별 쿼리 특화)
- 문제: 기존 방식에서는 하나의 쿼리가 모든 종류의 관계를 감지하도록 훈련되어 쿼리의 역할이 불분명해지고 특정 관계에 특화되기 어려웠습니다.
- 해결책: 쿼리와 관계(predicate)를 여러 개의 독립적인 그룹으로 나눕니다. 그리고 특정 쿼리 그룹에 속한 쿼리는 해당 그룹에 할당된 관계들만을 감지하도록 훈련됩니다.
- 결과: 쿼리가 "특정" 훈련 신호를 받아 모든 관계를 감지하려 애쓰는 대신, 지정된 관계 그룹에 대해 "특화된" 역할을 학습하게 됩니다.
- Quality-Aware Multi-Assignment (품질 인식 다중 할당)
- 문제: 기존 방식은 하나의 Ground Truth (GT)를 단 하나의 예측에만 할당했기 때문에, GT에 매우 근접한 고품질 예측들이 "관계 없음"으로 잘못 할당되어 학습에 필요한 긍정적인 신호를 충분히 받지 못했습니다.
- 해결책: GT와 주체(subject), 객체(object), 그리고 그 사이의 관계(predicate) 측면에서 상당히 유사한 여러 개의 "고품질" 예측에 GT를 할당합니다.
- 결과: 특화된 쿼리 훈련을 더욱 촉진하기 위해 "풍부한" 훈련 신호를 제공합니다.
- Groupwise Query Specialization (그룹별 쿼리 특화)
- SpeaQ 주요 성과
- 다양한 적용 및 성능 향상: Scene Graph Generation (SGG) 및 Human-Object Interaction (HOI) Detection과 같은 다양한 시각적 관계 감지 작업의 여러 아키텍처에 적용 가능하며, 일관된 성능 향상을 보였습니다.
- 광범위한 관계 감지: 특화된 쿼리 덕분에 기존 모델이 실패했던 "희귀한 관계"를 포함하여 더 넓은 범위의 관계를 성공적으로 감지합니다. 동시에 기존 모델의 성능이 좋았던 관계에서도 성능을 개선합니다.
- 균형 잡힌 성능: Visual Genome (VG) 벤치마크에서 일반적인 관계에 유리한 R@k 지표와 희귀한 관계에 유리한 mR@k 지표라는 상반된 두 지표 모두에서 최고 성능을 달성했습니다.
- 효율성: 이러한 성능 향상은 추가적인 후처리 과정, 모델 파라미터, 추론 비용 없이, 그리고 추론 파이프라인의 변경 없이 달성되었습니다.
2. Related Works
2.1. Transformers for Visual Relationship Detection
- VRD 란 무엇인가요?
- VRD는 이미지 내에서 트리플릿(triplet) 형태로 존재하는 개체(subject, object)와 그 개체들 사이의 관계(predicate)를 찾아내는 작업입니다.
- 예를 들어, "남자가 공을 던진다"라는 이미지에서 '남자'는 주체 (subject), '던진다'는 관계(술어) (predicate), '공'은 객체 (object) 가 됩니다.
- VRD는 단순히 이미지 내의 객체를 인식하는 것을 넘어, 객체들 간의 의미 있는 상호작용과 관계를 이해하는 데 초점을 맞춥니다.
- VRD의 주요 하위 작업
- 장면 그래프 생성(Scene Graph Generation, SGG): 이미지의 내용을 주체-관계-객체 트리플릿의 집합, 즉 그래프 형태로 표현하는 작업입니다.
- 이는 이미지 이해, 질문 답변 등 다양한 상위 레벨 비전 작업의 기반이 됩니다.
- 인간-객체 상호작용 감지(Human-Object Interaction Detection, HOI Detection): 특히 사람과 객체 사이의 상호작용을 감지하는 데 초점을 맞춘 작업입니다.
- 트랜스포머 기반 아키텍처의 부상
- 최근 DETR(Detection Transformer)의 성공 이후, 트랜스포머 기반의 신경망 아키텍처가 VRD 작업에서도 널리 채택되고 있습니다.
- 트랜스포머는 전체 이미지 또는 객체 간의 관계를 효과적으로 모델링할 수 있는 어텐션(attention) 메커니즘을 사용하기 때문에, 복잡한 시각적 관계를 파악하는 데 강점을 보입니다.
- 이러한 접근 방식은 기존 모델들에 비해 뛰어난 성능을 보여주며, 다양한 VRD 관련 연구 [1,2,3] (Scene Graph Generation) 은 이미지의 객체와 그들 간의 관계를 그래프 형태로 표현하는 작업입니다. 이 그래프는 이미지의 내용을 이해하는 데 도움이 됩니다.
2.2. Effective training of VRD models
- VRD 롱테일 속성 문제 및 기존 해결 전략
- VRD 데이터셋은 일부 관계(predicate)는 매우 흔하게 나타나지만, 다른 관계는 매우 드물게 나타나는 불균형한 분포('long-tailed property')를 가지고 있습니다. 이는 모델이 드문 관계를 잘 학습하기 어렵게 만듭니다.
- 이러한 문제를 완화하기 위해 여러 학습 전략이 제안되었습니다.
- 데이터 리샘플링 (Data resampling): 학습 데이터의 분포를 조절하여 드문 클래스(관계)의 샘플을 더 많이 학습하거나 흔한 클래스의 샘플을 덜 학습하는 방식입니다
- 손실 재가중치 (Loss re-weighting): 학습 과정에서 각 클래스의 중요도를 조절하는 손실 함수를 사용하여 드문 클래스에 더 높은 가중치를 부여하는 방식입니다
- 클래스별 분류기 구축 (Building class-specific classifiers): 각 관계 클래스에 특화된 분류기를 별도로 만들거나 활용하는 방식입니다
- 기존 접근 방식의 한계
- 이러한 기존 방법들은 동일한 모델의 capability 안에서 흔한 클래스와 드문 클래스 간의 성능 균형을 맞추려는 trade-off 을 추구합니다.
- 결과적으로 드문 클래스의 성능을 향상시키면 필연적으로 흔한 클래스의 성능 손실을 초래하는 경우가 많습니다.
- SpeaQ 의 차별점
- 본 논문의 접근 방식은 기존 방법들과 달리 모델 자체의 능력(capability)을 향상시키는 데 초점을 맞춥니다.
- 이를 위해 '특화된 쿼리(specialized query)'를 학습시켜 모델의 표현력을 높입니다.
- 결과적으로 특정 클래스의 빈도(frequency)에 관계없이 모든 클래스에 걸쳐 성능을 향상시킬 수 있다고 주장합니다.
- Object Detection 분야의 관련 연구 및 VRD로의 확장
- 최근 객체 감지 분야에서는 탐지기(detector)를 위한 '라벨 할당(label assignment)' 과정을 세밀하게 조정하려는 연구가 활발히 진행되었습니다. 이러한 연구들은 특히 '낮은 지역화 비용(low localization costs)'을 가진 예측(즉, 객체의 위치를 잘 맞춘 예측)에 적극적으로 학습 신호를 제공하는 데 중점을 둡니다
- DETR 은 트랜스포머를 사용하여 객체 감지를 수행하는 모델입니다. 이 모델은 이 논문에서 라벨 할당 전략의 표준으로 언급됩니다.
- 본 논문은 이러한 연구들에서 영감을 받아 VRD 작업을 위한 향상된 라벨 할당 전략을 제안합니다.
- 이 전략은 객체 감지에서 단일 객체에 초점을 맞추는 것과 달리, '트리플릿 [subject-relation-object] 수준'에서의 지역화 및 분류 품질을 종합적으로 고려하여 라벨 할당을 수행합니다.
- 이는 VRD 작업에서 더 나은 라벨 할당 전략을 탐색하는 선구적인(initiative) 작업으로 강조됩니다.
3. Method
3.1. Preliminary
Transformer-based Visual Relationship Detection (VRD).
- Visual Relationship Detection (VRD) 데이터셋 개요
- VRD 데이터셋 \(D\)는 이미지 \(I_{i}\)와 이에 해당하는 Ground Truth (GT) 세트 \(T_{i}\)의 쌍으로 이루어져 있습니다.
- \(|D|\)는 데이터셋의 전체 이미지 개수입니다.
- GT 세트 \(T_{i}\): 각 이미지 \(I_{i}\)에는 여러 개의 GT 삼중항(triplet) \(t_{j}\)가 포함될 수 있으며, 이들의 집합을 \(T_{i}\) 로 표현합니다.
- GT 삼중항 (t_jtjt_jtj): 하나의 삼중항은 주체(subject) s_jsjs_jsj, 술어(predicate) p_jpjp_jpj, 객체(object) o_jojo_joj로 구성됩니다. 여기서 'relation'이라는 용어 대신 'predicate'라는 용어가 주로 사용됩니다.
정보 표현: - 주체 (subject), 술어 (predicate), 객체 (object) 는 각각 바운딩 박스와 클래스 레이블로 표현됩니다.
- 여기서 \({R}^4\) 는 바운딩 박스를 나타내는 4개의 좌표를 의미합니다.
- GT 세트 \(T_{i}\) 는 디코더 쿼리(decoder queries)의 개수 \(N_{q}\) 에 맞춰 'no relation' 레이블로 채워져(padded) 있습니다. 즉, \(|T_i| = N_q\)가 됩니다. 이는 Transformer 모델에서 고정된 수의 출력을 다루기 위함입니다.
- Transformer 기반 VRD 모델의 구조
- 입력 및 출력: 모델은 이미지 \(I_i\)를 입력으로 받아 \(N_{q}\) 개의 예측된 삼중항을 출력합니다.
- CNN 백본 (CNN backbone): 일반적인 CNN(e.g., ResNet)을 사용하여 입력 이미지 \(I_i\) 로부터 시각적 특징을 추출합니다. 여기서 \(C\) 는 채널 수, \(H\)는 높이, \(W\) 는 너비를 나타냅니다.
- Transformer 인코더 (Transformer encoder): 추출된 시각적 특징 \(F_i\) 를 입력으로 받아 인코딩된 특징 \(Z_i\) 를 생성합니다. \(HW\)는 공간 차원의 총 픽셀 수를 의미합니다.
- Transformer 디코더 (Transformer decoders): 인코더의 출력 \(Z_i\)를 교차 어텐션(cross-attention)의 특징으로 사용합니다. 초기에는 학습 가능한 \(N_q\)개의 쿼리(query) 집합 \(Q\) 을 입력받아 이를 출력 임베딩(output embeddings)으로 변환합니다.
- 최종 예측 (Final predictions): 디코더의 출력 임베딩은 최종 예측 triple 로 변환됩니다. 최종적으로 Predicted triple 는 모델이 감지한 모든 주체-술어-객체 (subject, predicate, object) 관계의 집합을 나타냅니다.
Label assignment for Transformer-based VRD models.
- Label Assignment (라벨 할당) 의 필요성
- 트랜스포머 기반 VRD 모델은 정해진 위치에 고정적으로 예측을 수행하는 것이 아니라, 여러 개의 "예측(prediction)"을 생성합니다.
- 이 예측들을 실제 "정답(Ground Truth, GT)"에 어떻게 대응시켜야 모델이 올바르게 학습될 수 있을지 결정하는 과정이 바로 라벨 할당입니다.
- 여기에서는 이 라벨 할당이 예측 집합과 정답 집합을 매칭하는 과정이라고 설명합니다.
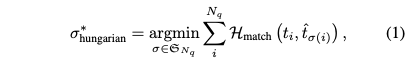
- 헝가리안 매칭 알고리즘 (Hungarian Matching Algorithm) (식 (1))
- 이 알고리즘은 트랜스포머 기반 아키텍처에서 정답과 예측 간에 "일대일(one-to-one)" 매칭을 찾는 표준적인 방법으로 널리 채택됩니다.
- 일대일 매칭을 통해 중복된 예측을 방지하고, 각 정답에 대해 가장 적절한 예측을 하나씩 대응시킵니다.
- 헝가리안 알고리즘을 통한 1-1 매칭의 목적은 "최소 매칭 비용(minimal matching cost)"을 갖는 순열(permutation)을 찾는 것입니다. 즉, 예측과 정답 간의 불일치 비용을 최소화하는 방식으로 최적의 짝을 찾아냅니다.
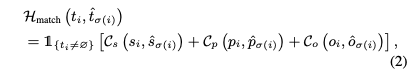
- 매칭 비용(Matching Cost) \(H_{match}\)의 구성 (식 (2))
- 정답 \(t_{i}\)가 'no relation' 라벨이 아닐 경우에만 1의 값을 가지고, 그 외의 경우(즉, 'no relation'인 경우)에는 0의 값을 가집니다.
- 이는 실제 정답 관계가 있는 경우에만 매칭 비용을 계산하겠다는 의미입니다.
- 총 매칭 비용은 subject, predicate, object 의 매칭비용의 합으로 구성됩니다.
- 각 매칭 비용의 구성
- 분류 비용(classification cost): 예측된 클래스(예: 주체 클래스)와 실제 정답 클래스 간의 차이를 측정합니다 (e.g., 교차 엔트로피 손실(cross-entropy loss)).
- 위치 비용(localization costs): 예측된 바운딩 박스(bounding box)와 실제 정답 바운딩 박스 간의 공간적 차이를 측정합니다 (예: L1 손실(L1 loss), 일반화 IoU 손실(generalized IoU loss)).
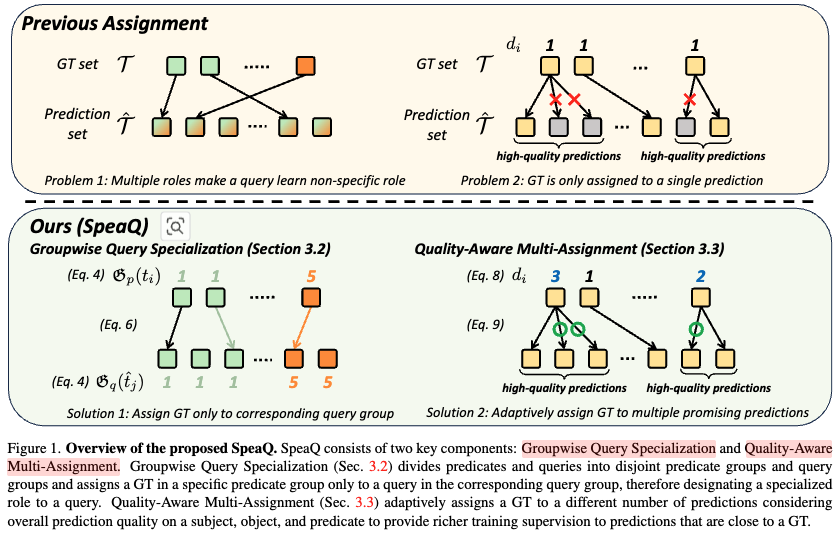
3.2. Groupwise Query Specialization
Frequency-based predicate and query grouping.
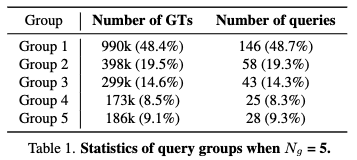
- Frequency-based Predicate and Query Grouping: 트랜스포머 기반의 VRD(Visual Relationship Detection) 모델 학습 시 쿼리의 전문성을 높이기 위해 술어(predicate)와 쿼리를 효율적으로 그룹화하는 방법
- 목표: 'unspecialized' 쿼리가 모든 관계를 감지하도록 훈련되는 기존 방식의 한계를 극복하고, 각 쿼리가 특정 관계에 특화(specialize)되도록 훈련하는 것이 목표입니다. 이를 통해 모델의 성능을 향상시키고 용량을 더 잘 활용할 수 있습니다.
- 술어(Predicate) 그룹화
- 먼저 전체 술어 클래스(predicate classes)를 \(N_g\) 개의 서로 다른 술어 그룹이 그룹화는 술어의 빈도(frequency) 를 기반으로 합니다. 즉, 빈도가 유사한 술어끼리 하나의 그룹으로 묶습니다.
- 목적: 이는 각 술어 그룹 내에서 빈도 분포의 균형을 맞춰 클래스 불균형으로 인한 최적화의 어려움을 피하는 데 도움이 됩니다.
- 쿼리(Query) 그룹화
- \(N_q\) 개의 쿼리(Q) 세트도 술어 그룹 수와 동일한 \(N_g\) 개의 쿼리 그룹으로 나눕니다.
- 이 논문에서는 비례적 쿼리 그룹화(proportional query grouping) 방식을 제안합니다.
- k번째 쿼리 그룹에 할당되는 쿼리의 수는 훈련 데이터셋에서 k번째 술어 그룹에 속하는 술어의 총 빈도에 비례하도록 설정됩니다.
- 예시: Table 1 은 \(N_g\) = 5일 때 각 쿼리 그룹의 통계를 보여주며, 각 그룹의 쿼리 수가 해당 술어 그룹의 빈도 비율에 비례함을 알 수 있습니다. 예를 들어, Group 1은 전체 GT의 48.4%를 차지하며, 쿼리도 전체의 48.7%가 할당되어 있습니다.
- 효과: 이러한 비례적 쿼리 그룹화는 모델의 출력 분포가 ground-truth(GT) 분포와 더 잘 일치하도록 돕습니다. 이는 그림 2(Fig. 2)에서 확인할 수 있습니다. 이러한 그룹화 과정을 통해 각 쿼리는 특정 술어 그룹에 집중하여 학습함으로써, 'unspecialized' 쿼리가 모든 관계를 동시에 학습하느라 겪는 어려움을 줄이고 모델의 전체적인 성능을 향상시킵니다.
Groupwise query specialization.
- 목표: 쿼리가 모든 관계를 탐지하려고 하기보다 특정 관계 그룹에만 집중하도록 강제하여, 쿼리의 역할을 전문화하고 훈련 신호의 모호성을 줄입니다.
- 작동 방식
- 그룹 정의: 먼저, 전체 술어(predicate) 클래스와 쿼리들을 미리 정의된 \(N_g\) 개의 서로 겹치지 않는 그룹으로 나눕니다. 술어 그룹은 주로 빈도에 기반하여 나뉘며, 쿼리 그룹은 해당 술어 그룹의 빈도에 비례하여 쿼리 수가 할당됩니다.
- 매핑 함수 (Mapping Functions): 특정 ground-truth (GT)가 어떤 술어 그룹에 속하는지, 그리고 특정 예측을 생성한 쿼리가 어떤 쿼리 그룹에 속하는지를 알려주는 두 가지 매핑 함수를 정의합니다.
- 그룹화 비용 (Grouping Cost): 이 매핑 함수를 사용하여, GT의 술어 그룹과 예측을 생성한 쿼리의 쿼리 그룹이 일치하지 않을 경우 높은 비용을 부과하는 새로운 비용 항을 정의합니다. 일치하거나, GT가 'no relation'이라는 특수 라벨일 경우 비용은 0이 됩니다.
- 최종 매칭 비용에 추가: 이 그룹화 비용을 기존의 헝가리안 매칭 알고리즘의 매칭 비용에 추가하여, 모델이 훈련될 때 해당 쿼리 그룹에 할당된 관계에 대해서만 예측하도록 유도합니다.
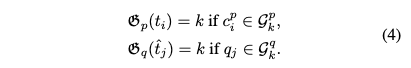
- Mapping Functions
- 두 가지 매핑 함수를 정의합니다.
- \(G_p\): GT t_itit_iti의 술어 레이블 c_{p_i}cpic_{p_i}cpi가 속하는 술어 그룹의 인덱스 \(k\) 를 반환하는 함수입니다.
- \(G_q\): 예측된 것을생성한 쿼리 \(q_j\) 가 속하는 쿼리 그룹의 인덱스 \(k\) 를 반환하는 함수입니다.
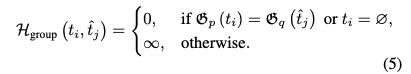
- 그룹화 비용 \(H_{group}\): 헝가리안 알고리즘에서 사용하는 Cost
- 이 수식은 GT 와 예측간의 그룹화 비용 \(H_{group}\) 을 정의합니다. 이 비용은 헝가리안 매칭 알고리즘이 GT와 예측을 매칭할 때 사용됩니다.
- 비용이 0 이 되는 경우
- GT의 술어 그룹 인덱스와 예측을 생성한 쿼리의 쿼리 그룹 인덱스가 같을 때 비용이 0입니다. 이는 해당 쿼리가 자신이 담당하도록 지정된 관계를 예측하려 할 때 페널티를 주지 않겠다는 의미입니다.
- GT가 'no relation' 라벨일 경우에도 비용이 0입니다. 이는 트랜스포머 모델의 라벨 할당에서 GT 수가 예측 수보다 적을 때 'no relation'으로 채워지는 더미 GT에 대해서는 그룹화 비용을 부과하지 않음을 의미합니다.
- 비용이 무한대가 되는 경우
- otherwise: 위 두 가지 조건에 해당하지 않는 모든 경우에 비용이 무한대입니다. 즉, GT의 술어 그룹과 예측 쿼리의 쿼리 그룹이 다를 때 비용이 무한대입니다.
- 이 매우 높은 비용은 헝가리안 매칭 알고리즘이 이런 매칭을 선택하지 않도록 강제하여, 쿼리가 자신이 속한 그룹의 관계만 탐지하도록 유도하는 역할을 합니다.
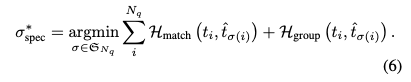
- Groupwise Query Specialization
- First term (Matching Cost): 기존의 Transformer 기반의 VRD 모델에서 사용하는 헝가리안 알고리즘 매칭비용. 여기에는 주체(subject), 술어(predicate), 객체(object)의 분류 비용과 위치 비용(L1, IoU 손실 등)을 포함합니다.
- Second term (Group Cost)
- 이 비용 함수를 최소화함으로써, 헝가리안 알고리즘은 가능한 한 \(H_{group}\) 이 0이 되는 매칭, 즉 GT의 술어 그룹과 쿼리 예측의 쿼리 그룹이 일치하는 매칭을 우선적으로 선택하게 됩니다. 이는 각 쿼리 그룹이 특정 술어 그룹에 대해 전문화되도록 강제하는 핵심 메커니즘입니다.
- 이러한 과정을 통해, 쿼리들은 자신이 담당하는 관계 그룹에 대한 학습 신호를 더 명확하게 받고, 다른 관계 그룹에 대한 모호한 신호로 인해 훈련이 방해받는 것을 줄일 수 있습니다. 결과적으로 각 쿼리는 특정 역할에 'specialize'되어 모델의 전반적인 성능 향상으로 이어집니다.
3.3. Quality-Aware Multi-Assignment
- Motivation: 기존의 VRD 를 위한 Transformer 기반 모델에서 사용하는 Label Assignment (라벨할당) 방식의 한계
- 기존의 라벨 할당 방식, 특히 Hungarian matching algorithm과 같은 방법은 하나의 Ground Truth (GT)를 오직 하나의 예측(prediction)에만 할당하도록 제약합니다.
- 이러한 제약 때문에 GT에 거의 정확하거나 심지어 정확한 예측임에도 불구하고 '관계 없음(?)'으로 할당되어 훈련 과정에서 억제되는(suppressed) 문제가 발생합니다. 이는 모델이 올바른 예측을 했음에도 불구하고 부정적인 신호를 받게 되어 적절한 훈련을 방해합니다.
- 다중 할당(Multi-Assignment)의 도입
- 이러한 문제를 해결하기 위해 저자들은 "다중 할당" 방식을 제안합니다.
- 다중 할당은 하나의 GT 를 단순히 하나의 예측에만 할당하는 대신, 여러 개의 "고품질 예측(high-quality predictions)"에 할당합니다. 여기서 '고품질'이란 주체(subject), 객체(object), 그리고 그들 사이의 관계(predicate) 측면에서 GT와 매우 유사한 예측을 의미합니다.
- 이를 통해 모델은 GT와 유사한 여러 예측에 대해 더욱 풍부한 긍정적인 훈련 신호(abundant training signals)를 받아 학습 효율을 높일 수 있습니다.
Triplet quality-aware determination of \(d_{i}\).
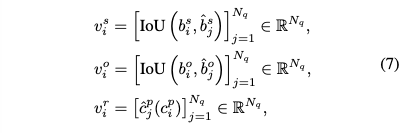
- Quality-Aware Multi-Assignment 에서 \(d_{i}\) 값, 즉 하나의 Ground Truth(GT)에 할당될 "높은 품질" 예측의 개수를 어떻게 결정하는지 설명하는 부분입니다.
- 이는 고정된 개수를 할당하는 대신, 예측의 품질을 고려하여 \(d_{i}\) 를 유동적으로 조절함으로써 모델 학습에 더 풍부하고 정확한 신호를 제공하는 것을 목표로 합니다.
- 주체, 객체, 술어 각각에 대한 품질을 측정하는 세 가지 벡터는 위의 식 (7) 과 같이 정의됩니다.
- 주체 품질 벡터 (Subject Quality Vector)
- IoU: Intersection over Union (겹침 영역 비율) 함수입니다. 두 바운딩 박스 간의 겹치는 정도를 0과 1 사이의 값으로 나타냅니다. 값이 1에 가까울수록 두 박스가 더 많이 겹칩니다.
- 객체 품질 벡터 (Object Quality Vector): Ground Truth \(t_i\) 의 객체 바운딩 박스와 각 예측의 객체 바운딩 박스 간의 IoU 값을 원소로 가집니다.
- 술어 품질 벡터 (Predicate Quality Vector): \(c_{p_{i}}\): 디코더 쿼리의 수로, 전체 예측의 개수를 의미합니다.
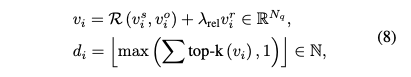
- 트리플렛 수준 품질 벡터 (Triplet-level Quality Vector): \(N_q\)
- \(N_q\): 요소별 함수(element-wise function)로, 주체 품질 벡터 \(R\) 와 객체 품질 벡터를 결합합니다. 논문에서는 \(min\) 또는 \(max\) 와 같은 함수가 될 수 있다고 언급합니다.
- 예를 들어, \(min\) 을 사용하면 주체와 객체 중 더 낮은 IoU 값을 사용하여 두 바운딩 박스 모두의 품질을 보수적으로 반영합니다. max를 사용하면 둘 중 더 높은 IoU를 반영합니다.
- 최종 \(d_{i}\) 계산: \(v_{i}\)
- \(top-k(v_{i})\): \(v_{i}\) 벡터에서 품질 점수가 가장 높은 상위 \(k\)개의 원소만 유지하고, 나머지 원소들은 0으로 설정하는 함수입니다.
- 이는 Ground Truth \(t_{i}\) 에 대해 가장 유망한 \(k\) 개의 예측에 집중하려는 목적입니다.
- 기여: \(d_{i}\)는 각 Ground Truth에 대해 예측들의 전체적인 품질을 고려하여 동적으로 결정되며, 이는 모델이 더 많은 양질의 학습 신호를 받을 수 있도록 돕습니다.
Quality-aware multi-assignment.
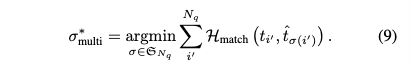
- \(d_{i}\) 의 의미 및 역할
- d_i는 특정 Ground Truth(GT) t_i에 할당될 "고품질 예측"의 수를 의미합니다.
- 이는 주체(subject), 객체(object), 그리고 그 사이의 관계(predicate)에 대한 예측의 전반적인 "트리플렛 수준 예측 품질"을 고려하여 동적으로 결정됩니다(식 8 참조).
- 이 값은 GT 가 여러 예측에 긍정적인 학습 신호를 줄 수 있도록 하여, 기존의 단일 할당 방식의 한계를 극복하는 데 기여합니다.
- 확장된 GT 세트 \(T_{i'}\)의 구성
- \(d_{i}\)가 계산되면, 이 \(d_{i}\)값만큼 GT 를 복제합니다.
- 이렇게 복제된 \(t_{i}\) 와 함께, 전체 쿼리 수 \(N_{q}\)에 도달할 때까지 'no relation' 라벨로 패딩하여 확장된 GT 세트 \(T_{i'}\)를 구성합니다.
- 식 (9): 품질 인식 다중 할당을 위한 최적의 예측 순열 \(N_{q}\) 을 찾는 과정을 정의합니다.
- 목표 및 효과
- 식 (9) 목표는 헝가리안 알고리즘을 사용하여 확장된 GT 세트 \(T_{i'}\)와 예측 세트간의 가장 낮은 매칭 비용을 갖는 최적의 일대일 순열을 찾는 것입니다.
- 기존의 단일 할당 방식(하나의 GT에 하나의 예측만 할당)에서는 정답에 매우 가깝거나 심지어 올바른 예측임에도 불구하고 'no relation' 으로 할당되어 억제되는 경우가 있었습니다.
- \(d_{i}\)를 통해 하나의 GT가 여러 "유망한 예측"에 할당될 수 있게 함으로써, 모델이 더 풍부하고 긍정적인 학습 신호를 받을 수 있도록 돕습니다. 이는 특히 'long-tailed property'로 인해 학습이 어려운 드문 관계(rare relations)의 성능 향상에 기여할 수 있습니다.
Final Training Objective.
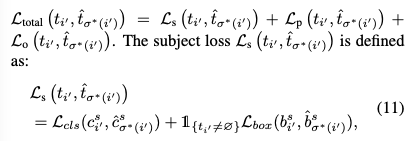
- Transformer-based VRD 모델 학습 프로시져: 헝가리안 알고리즘을 통해, 예측된 것 과 GT 간의 매칭 후 매칭 된 결과를 기반으로 최종 손실함수를 계산할 수 있습니다.
- \(L_{total}\)은 매칭된 각 [Ground Truth-예측 쌍] pair 에 대해 주체 \(L_{s}\), 술어 \(L_{p}\), 객체 \(L_{o}\)에 대한 손실을 합산한 것입니다.
- 술어 (predicate) 손실 \(L_{p}\) 및 객체 (object) 손실 \(L_{o}\): 주체 손실과 동일하게 정의됩니다. 술어는 주로 분류 손실만을 포함하고, 객체는 분류 손실 (Cross-entropy loss) 과 위치 손실 (IoU loss)을 모두 포함합니다.
- SpeaQ 기여: 모델은 Ground Truth에 대한 최적의 예측을 생성하고, 동시에 쿼리들이 특정 관계 감지에 특화되도록 (Specialized)학습됩니다.
4. Experiments
- Scene Graph Generation task
- Human-Object Interaction Detection task
4.1. Datasets
Visual Genome.
- 원래 데이터셋 규모: Visual Genome 데이터셋은 총 108,000장의 이미지와 75,000개의 객체(objects), 그리고 37,000개의 술어(predicates)로 구성되어 있습니다.
- 사용된 서브셋 (VG150): 이 연구에서는 이전 연구들 [4,5] 을 따라 Visual Genome의 서브셋인 'VG150'을 사용했습니다.
- VG150의 구성: VG150은 전체 객체와 술어 중에서 가장 빈번하게 등장하는 150개의 객체 카테고리와 50개의 술어 카테고리로 이루어져 있습니다.
- 이는 연구의 초점을 맞추고 데이터 처리의 복잡성을 줄이기 위한 일반적인 접근 방식입니다.
Evaluation Metrics.
- Recall@K (R@K)
- 모델이 상위 K개의 예측 내에서 실제(Ground Truth, GT) 관계를 얼마나 정확하게 찾아냈는지 측정하는 지표입니다. 예를 들어, R@50은 모델이 가장 자신 있는 50개의 예측 중 정답이 몇 개 포함되었는지를 의미합니다.
- 이 지표는 데이터셋에서 자주 등장하는(common) 관계에 대해 높은 점수를 주는 경향이 있습니다. 모델은 빈번하게 나타나는 관계를 더 쉽게 학습하고 예측하기 때문입니다.
- Mean Recall@K (mR@K)
- 각 관계 클래스(예: 'on', 'holding', 'eating' 등)별로 Recall@K 값을 계산한 후, 이 값들을 평균낸 지표입니다.
- mR@K는 드물게 등장하는(rare) 관계의 성능을 더 잘 반영합니다. R@K와 달리, 각 클래스의 중요도를 동일하게 취급하므로, 모델이 흔한 관계뿐만 아니라 희귀한 관계도 잘 감지하는지 평가하는 데 유용합니다.
- 지표 사용의 배경 - Long-tailed Property: VRD 데이터셋(예: Visual Genome)은 특정 관계는 매우 자주 나타나고, 다른 관계는 매우 드물게 나타나는 롱테일 분포(long-tailed property) 를 가집니다.
- 이러한 분포 때문에 R@K는 흔한 관계에 편향되고, mR@K는 희귀한 관계에 초점을 맞추게 됩니다. 즉, 두 지표가 서로 상반되는 경향이 있습니다.
- 산술 평균 (AvgR@K)
- R@K와 mR@K의 산술 평균입니다.
- 목적: R@K와 mR@K가 가지는 편향성을 보완하여, 모델이 흔한 관계와 희귀한 관계 모두에서 전반적으로 균형 잡힌 성능을 보이는지 측정하기 위해 사용됩니다.
- 조화 평균 (F@K)
- 정의: R@K와 mR@K의 조화 평균입니다.
- 목적: 산술 평균과 마찬가지로 균형 잡힌 성능을 측정하기 위함이지만, 조화 평균은 두 값 중 더 낮은 값에 더 민감하게 반응하는 특성이 있습니다. 따라서 어느 한 쪽 지표라도 크게 낮으면 F@K 값도 낮아지므로, 더 엄격하게 균형을 평가할 수 있습니다
HICO-DET.
- 데이터셋의 목적: HICO-DET은 이미지 내에서 사람과 객체 간의 상호 작용을 감지하는 Human-Object Interaction (HOI) Detection 태스크를 위해 만들어진 벤치마크 데이터셋입니다.
- 데이터셋 규모
- 총 47,000개의 이미지를 포함하며, 이 중 37,500장은 훈련(training)에, 9,500장은 테스트(test)에 사용됩니다.
- 15만 개 이상의 인간-객체 쌍(human-object pairs)에 대한 주석(annotation)이 포함되어 있습니다.
- 클래스 구성
- 이 데이터셋은 600개의 "삼중항 클래스(triplet classes)"를 가집니다.
- 이 클래스들은 80개의 객체 클래스와 117개의 동사 클래스(예: '사람'-'컵', '들고 있다')의 가능한 조합 중 일부로 구성됩니다.
- 성능 평가 방식
- 모델의 성능은 mAP(mean Average Precision) 지표를 사용하여 보고됩니다.
- 성능은 세 가지 다른 세트(subset)로 나누어 평가됩니다.
- Full: 600개의 모든 클래스를 포함한 전체 성능입니다.
- Rare: 훈련 인스턴스가 10개 미만인 138개의 희귀(rare) 클래스에 대한 성능입니다. 이는 데이터셋의 "롱테일 속성(long-tailed property)" 중 빈도가 낮은 클래스에 해당합니다.
- Non-Rare: 훈련 인스턴스가 10개 초과인 462개의 일반(non-rare) 클래스에 대한 성능입니다. 이는 빈도가 높은 클래스에 해당합니다.
4.2. Experimental Results
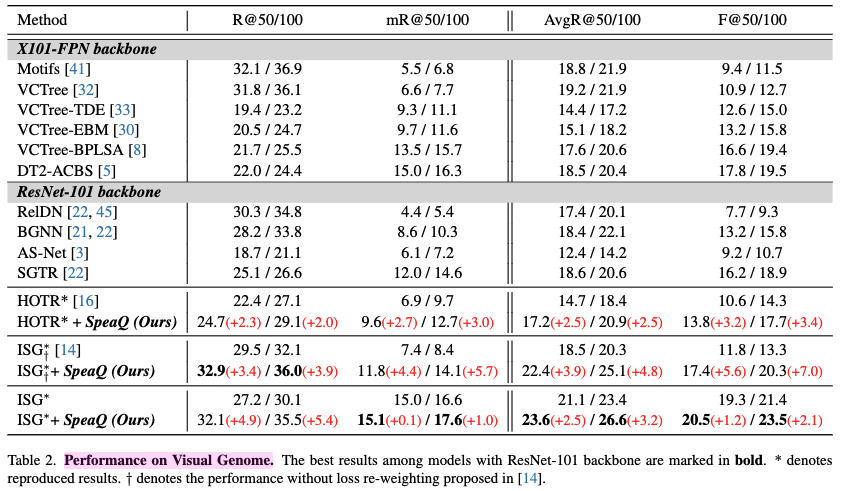
Results on Visual Genome.
- SpeaQ 적용 모델 및 성능 향상
- ISG 모델: ISG는 이 논문에서 언급된 경쟁력 있는 Transformer 기반 모델 중 하나입니다.
- SpeaQ를 ISG에 적용했을 때, R@100(Recall@100) 지표에서 5.4, mR@100(Mean Recall@100) 지표에서 1.0의 성능 향상을 보였습니다.
- 이는 AvgR@100 및 F@100과 같은 종합적인 균형 성능 지표에서도 최상의 결과를 가져왔습니다.
HOTR 모델: HOTR 역시 Transformer 기반 모델입니다. - SpeaQ를 HOTR에 적용했을 때, R@100에서 2.0, mR@100에서 3.0의 성능 향상을 보였습니다.
- 지표의 상반성 및 SpeaQ의 성과
- R@K (Recall@K): 이는 일반적으로 빈번하게 나타나는(common) 관계(predicate)에 대한 모델의 성능을 측정하는 데 유리합니다.
- 상위 K개의 예측 내에 정답이 얼마나 많이 포함되는지를 봅니다.
- mR@K (Mean Recall@K): 이는 각 관계(predicate) 클래스별 Recall@K를 평균낸 값으로, 데이터셋의 롱테일 속성(long-tailed property) 때문에 희귀한(rare) 관계에 대한 모델의 성능을 더 잘 반영합니다.
- 이 두 지표는 종종 상충하는 경향이 있습니다.
- 즉, 한 쪽 성능이 좋아지면 다른 쪽은 나빠지기 쉬운데, SpeaQ는 이 둘 모두에서 일관된 성능 향상을 달성했습니다. 이는 모델이 일반적인 관계와 희귀한 관계 모두를 효과적으로 탐지할 수 있게 되었음을 의미합니다.
- SpeaQ의 일반화 능력 및 효율성
- ISG와 HOTR 두 모델 모두에서 일관된 성능 향상을 보였다는 점은 제안하는 SpeaQ 기법이 다양한 Transformer 기반 VRD 모델에 일반화될 수 있음을 시사합니다.
- 가장 주목할 만한 점은 이러한 성능 향상이 추가적인 모델 파라미터나 추론 비용(inference cost) 없이 달성되었다는 것입니다. 이는 SpeaQ가 기존 모델의 잠재력을 더 잘 활용(leverage model capacity)하도록 훈련 방법을 개선했기 때문입니다.
5. Analysis
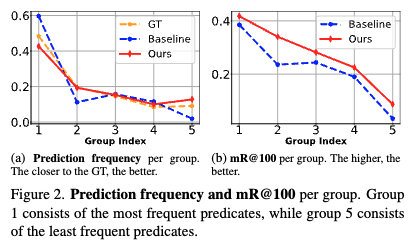
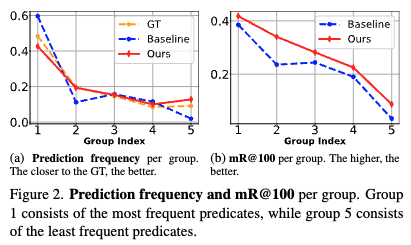
Analyses on output frequency and mR@100 per group.
- Figure 2 (a) (예측 빈도 분석)
- 이 그래프는 각 술어(predicate) 그룹별 예측 빈도를 보여줍니다. 그룹 1은 가장 자주 등장하는 술어를, 그룹 5는 가장 드물게 등장하는 술어를 포함합니다.
- 문제점 (Baseline, 파란색 선): 기존 모델(Baseline)은 자주 등장하는 술어(Group 1)에 대해 과도하게 예측하고, 드물게 등장하는 술어(Group 5)에 대해서는 과소 예측하는 경향을 보입니다. 이는 데이터의 GT(Ground Truth) 분포(주황색 선)와 큰 차이를 보입니다.
- SpeaQ의 효과 (SpeaQ, 빨간색 선): SpeaQ를 적용한 모델은 GT 분포(주황색 선)에 훨씬 더 가까운 예측 분포를 보여줍니다. 이는 자주 등장하는 클래스의 과대 예측과 드물게 등장하는 클래스의 과소 예측이 완화되었음을 의미합니다.
- Figure 2 (b) (mR@100 성능 분석)
- 이 그래프는 각 술어 그룹별 mR@100(Mean Recall@100) 성능을 보여줍니다. mR@100은 각 그룹 내 술어들의 평균 리콜(recall) 값을 나타냅니다.
- SpeaQ의 효과: SpeaQ를 적용한 모델은 모든 술어 그룹에서 일관된 성능 향상을 보입니다.
- 특히 가장 자주 등장하는 술어 그룹(Group 1)에서 예측 빈도가 감소했음에도 불구하고 성능이 향상됩니다. 이는 쿼리가 특정 관계에 특화(specialized)됨으로써, 더 적은 수의 예측으로도 해당 작업을 더 효율적이고 정확하게 수행할 수 있게 되었음을 시사합니다.
- 쿼리 특화(specialization)는 각 쿼리의 대상 작업 성능을 향상시키고, 특화된 쿼리들의 집합이 전체적인 GT 분포를 더 잘 반영하게 함으로써 전반적인 모델 성능을 개선합니다.
Applying SpeaQ to the model with a larger \(N_{q}\).
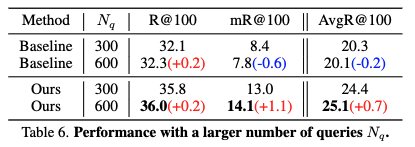
- \(N_{q}\) (쿼리 수) 증가가 Transformer 기반 시각 관계 탐지(VRD) 모델의 성능에 미치는 영향을 비교하며, 제안된 SpeaQ 방법의 효과를 설명합니다. 여기서 \(N_{q}\) 는 모델의 디코더 쿼리(decoder queries) 수를 의미하며, 이는 모델이 이미지 내의 관계를 탐지하기 위해 사용하는 '탐침'과 같은 역할을 합니다.
- Baseline 모델의 \(N_{q}\) 증가 시 문제점
- 기존 훈련 방식(Baseline)에서 \(N_{q}\) 를 300에서 600으로 늘렸을 때, R@100(자주 등장하는 관계에 대한 Recall)은 0.2 상승했지만, mR@100(모든 관계에 대한 평균 Recall, 희귀 관계에 민감)은 0.6 하락했습니다.
- 이는 R@100의 증가폭보다 mR@100의 하락폭이 세 배나 크다는 것을 의미합니다.
- Baseline 모델은 쿼리 수를 늘릴 경우 모델의 전체 용량(capacity)을 효과적으로 활용하지 못하며, 특히 데이터셋의 [long-tailed property] 때문에 희귀한 관계를 탐지하는 데 어려움을 겪는다는 것을 보여줍니다. 즉, 더 많은 쿼리가 생겼음에도 불구하고 이들을 효과적으로 '특화'시키지 못하고 혼란을 겪는다는 뜻입니다.
- SpeaQ 모델의 \(N_{q}\) 증가 시 효과
- SpeaQ 로 훈련된 모델의 경우 Nq를 늘렸을 때 R@100은 0.2, mR@100은 1.1만큼 모두 성능이 향상되었습니다.
- 이는 SpeaQ가 \(N_{q}\) 를 늘림으로써 모델의 용량을 더 잘 활용할 수 있도록 돕는다는 것을 의미합니다.
- SpeaQ는 [Groupwise Query Specialization] 을 통해 쿼리를 특정 관계에 특화시키고, [Quality-Aware Multi-Assignment] 를 통해 풍부한 학습 신호를 제공하므로, 더 많은 쿼리가 주어졌을 때 각 쿼리가 자신의 역할을 효과적으로 수행할 수 있게 됩니다.
- 결론: 종합적으로, 이 결과는 SpeaQ 가 모델의 용량 활용 능력을 향상시켜 쿼리 수를 늘리는 것이 성능 향상으로 이어진다는 점을 입증합니다. Baseline 모델이 쿼리 증가에 따른 용량 활용에 실패하는 것과 대조적입니다.
Analysis on \(N_{g}\).

- Groupwise Query Specialization은 쿼리와 관계를 여러 그룹으로 나누어 특정 쿼리 그룹의 쿼리가 해당 관계 그룹의 관계만을 감지하도록 특화시키는 방법입니다. 여기서 \(N_{g}\) 는 이러한 그룹의 수를 의미합니다.
- 실험 결과
- Table 5에 따르면, \(N_{g}\) 값을 1(즉, 그룹을 나누지 않은 baseline 모델)과 비교했을 때, \(N_{g}\) 가 증가할수록 AvgR@100 지표에서 일관된 성능 향상을 보였습니다. 이는 쿼리 특화(query specialization)가 효과적임을 시사합니다.
- AvgR@100은 \(N_{g}\) 가 4일 때 최고 성능(25.1)을 기록하며 정체(plateau)에 도달한 후, 그 이상으로 \(N_{g}\) 가 증가하면 성능이 약간 감소하는 경향을 보였습니다.
- Findings
- 저자들은 \(N_{g}\) 를 너무 크게 설정하여 쿼리 그룹을 과도하게 많이 나누는 것이 최적이 아닐 수 있다고 추측합니다.
- 그 이유는 각 그룹에 할당되는 Ground Truth (GT)의 양이 부족해지면서 충분한 학습 신호(training signals)를 제공하기 어려워지기 때문입니다. 즉, 너무 세분화된 그룹은 오히려 학습 데이터를 희석시켜 성능 저하를 초래할 수 있다는 의미입니다.
Analysis on \(k\).
- \(k\) 의 의미: Eq (8) 에서 \(d_{i}\) 는 특정 GT 에 할당될 수 있는 고품질 예측의 개수를 나타냅니다. \(v_{i}\)는 주체, 객체, 술어 품질을 종합한 벡터인데, \(d_{i}\)는 이 \(v_{i}\) 에서 상위 \(k\)개의 요소 합계에 따라 결정됩니다. 즉, \(k\) 가 커질수록 더 많은 고품질 예측에 GT를 할당하여 긍정적인 학습 신호를 제공하게 됩니다.
- 성능 변화 경향
- Baseline (\(k\)=1) 대비 향상: \(k\)=1은 기존의 단일 할당(Single Assignment)과 유사한 상황을 의미하며, \(k\) 값이 커질수록 Recall@100 (R@100), Mean Recall@100 (mR@100), Average Recall@100 (AvgR@100) 모두 일관되게 성능이 향상되는 것을 보여줍니다. 이는 고품질 예측에 더 많은 긍정적 학습 신호를 제공하는 것이 모델 학습에 효과적임을 시사합니다.
- 최적의 \(k\) 값: Table 5에 따르면, \(k\)=6일 때 R@100 36.0, mR@100 14.1, AvgR@100 25.1로 가장 좋은 성능을 달성합니다. 이는 모델이 가장 효과적으로 학습 신호를 활용할 수 있는 \(k\) 값이라는 것을 의미합니다.
- 과도한 \(k\) 값의 문제: 하지만 \(k\) 가 6보다 커지면(예: \(k\)=7) 성능이 미미하게 감소하는 경향을 보입니다. 이는 논문에서 설명하듯이 지나치게 큰 \(k\)는 유망하지 않은 예측에도 긍정적인 신호를 제공할 수 있다는 이유 때문입니다.
- 너무 많은 예측에 긍정적인 신호를 주게 되면, 모델이 실제로 정확하지 않은 예측까지 "정답"으로 간주하여 학습하게 되어 오히려 성능 저하를 초래할 수 있습니다.
- 결론: \(k\) 값은 Quality-Aware Multi-Assignment의 핵심적인 하이퍼파라미터로, 적절한 \(k\) 값 설정은 모델에 풍부하고 효과적인 학습 신호를 제공하여 전반적인 성능 향상에 기여합니다.
Ablation study on proportional query grouping.
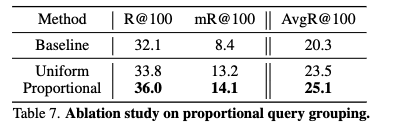
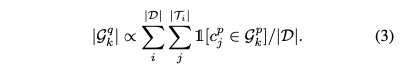
- 비율 기반 쿼리 그룹화 (Proportional Query Grouping)
- 논문에서 제안하는 방식으로, 각 쿼리 그룹에 할당되는 쿼리 수가 해당 그룹 내 술어(predicate)들의 전체 빈도에 비례하도록 설정합니다.
- 이는 식 (3)으로 표현됩니다
- 전체 데이터셋 D 내 모든 이미지의 모든 GT 삼중항 중에서, k 번째 술어 그룹에 속하는 술어의 총 빈도(개수)를 의미합니다.
- 이 식은 특정 술어 그룹에 속하는 술어들이 데이터셋에 많이 나타날수록, 해당 술어 그룹을 담당하는 쿼리 그룹에 더 많은 쿼리를 할당한다는 의미입니다.
- 균등 쿼리 그룹화 (Uniform Query Grouping): 모든 쿼리 그룹에 동일한 수의 쿼리를 할당하는 방식입니다.
- 기준선 (Baseline): Groupwise Query Specialization (그룹별 쿼리 특화) 또는 Quality-Aware Multi-Assignment (품질 인식 다중 할당)이 적용되지 않은 모델을 의미합니다.
- 실험 결과
- 균등 쿼리 그룹화는 기준선 모델에 비해 성능 향상을 보였습니다. 이는 쿼리를 특화하는 것이 일반적인 방식보다 유리함을 시사합니다.
- 비율 기반 쿼리 그룹화는 균등 그룹화보다 더 나은 성능을 달성하여, 가장 좋은 결과를 보였습니다.
- 성능 차이의 원인: VRD(Visual Relationship Detection) 데이터셋은 대개 롱테일 분포(long-tailed property) 를 가집니다. 즉, 특정 술어(예: 'on', 'has')는 매우 흔하게 나타나지만, 다른 술어(예: 'behind', 'in front of')는 매우 드물게 나타납니다.
- 균등 그룹화 (Uniform Query Grouping)의 한계
- 모든 쿼리 그룹에 동일한 수의 쿼리를 할당할 경우, 데이터의 불균형 문제가 발생할 수 있습니다.
- 자주 나타나는 술어 그룹을 담당하는 쿼리 그룹은 방대한 양의 GT 데이터에 비해 쿼리 수가 부족하여 충분히 학습되지 못하거나, 쿼리 하나당 처리해야 할 데이터가 너무 많아 학습 효율이 떨어질 수 있습니다.
- 드물게 나타나는 술어 그룹을 담당하는 쿼리 그룹은 쿼리 수는 충분하지만, 학습할 GT 데이터 자체가 매우 적어서 쿼리의 '특화'가 제대로 이루어지기 어려울 수 있습니다.
- 이는 모델 용량의 비효율적인 사용으로 이어질 수 있습니다.
- 비율 기반 그룹화의 장점: 각 쿼리 그룹에 할당되는 쿼리 수를 해당 술어 그룹의 GT 빈도에 비례하게 조정함으로써, 모든 쿼리 그룹이 GT 데이터의 양에 비례하는 적절한 수의 쿼리를 갖게 됩니다.
- 이는 쿼리가 특정 술어에 더 효과적으로 특화(specialize) 될 수 있도록 돕습니다. 즉, 각 쿼리 그룹이 담당하는 술어에 대한 학습 신호가 더 '균형 잡힌' 상태로 제공되어, 쿼리들이 해당 술어를 더 정확하게 감지하고 예측하도록 훈련됩니다. 결과적으로 모델 전체의 용량을 더 효율적으로 활용하게 됩니다.
Analysis on predicate grouping criterion.
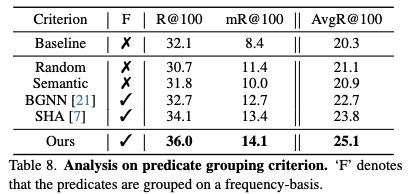
- 다양한 Predicate Grouping 기준
- 무작위(Random) 그룹화: Predicate 들을 임의로 5개의 동일한 크기 그룹으로 나눕니다. 이는 특별한 전략 없이 단순히 그룹의 존재 유무만을 확인하기 위한 기준이 될 수 있습니다.
- 의미 기반(Semantic) 그룹화: 프레디케이트들을 그들의 어휘적 의미(lexical semantics)에 따라 '기하학적(geometric)', '소유(possessive)', '의미적(semantic)'의 세 그룹으로 나눕니다. 이는 Neural Motifs 와 같은 이전 연구에서 시도된 방법입니다.
- 빈도 기반(Frequency-basis) 그룹화: 프레디케이트들의 등장 빈도(frequencies)에 따라 그룹을 나눕니다.
- [6] 에서는 장면 그래프 생성은 이미지의 객체와 그들 간의 관계를 그래프 형태로 표현하는 작업입니다. 이 그래프는 이미지의 내용을 이해하는 데 도움이 됩니다.
- 빈도 기반 그룹화의 우수성
- 실험 결과(Tab. 8)는 빈도 기반 그룹화가 무작위 또는 의미 기반 기준보다 일관되게 더 나은 성능을 보여준다는 것을 명확히 합니다.
- 이는 VRD 데이터셋이 가지는 long-tailed property (일부 관계는 매우 흔하고, 다른 관계는 매우 드물게 나타나는 불균형한 분포) 때문에 발생합니다.
- 빈도 기반 그룹화는 이러한 클래스 불균형으로 인한 훈련 어려움을 완화하는 데 도움이 되기 때문입니다.
- 제안하는 Groupwise Query Specialization은 특정 쿼리가 해당 그룹 내의 관계에만 집중하도록 훈련시키는데, 이때 빈도에 따라 그룹을 나누는 것이 각 쿼리에 더 균형 잡힌 훈련 신호를 제공하여 모델의 specialized query 훈련에 효과적임을 시사합니다.
Analysis on choice of \(R\).
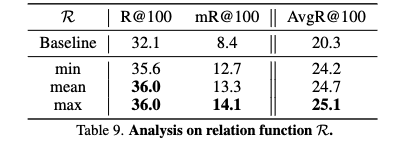
- 실험 결과: R 함수로 max를 사용했을 때 R@100과 mR@100 모두에서 가장 좋은 성능을 보였으며, mean과 min 순으로 성능이 나타났습니다.
- R 함수의 역할
- min: 주체와 객체 예측 중 낮은 IoU(Intersection over Union, 객체 위치 정확도) 값을 기준으로 품질을 평가합니다. 즉, 주체나 객체 중 하나라도 IoU가 낮으면 전체 품질 점수도 낮아지므로, 매우 보수적인 방식으로 "완벽하게" 감지된 경우에만 높은 점수를 부여하게 됩니다. 이는 학습에 제공되는 긍정적인 신호의 양을 제한할 수 있습니다.
- mean: 주체와 객체 예측의 IoU 값을 평균하여 품질을 평가합니다. min보다는 덜 보수적이지만, 여전히 두 요소가 모두 일정 수준 이상이어야 높은 점수를 얻습니다.
- max: 주체와 객체 예측 중 높은 IoU 값을 기준으로 품질을 평가합니다. 즉, 주체나 객체 중 하나라도 잘 감지되었다면 높은 품질 점수를 얻을 수 있습니다. 이는 모델이 아직 혼란스러워하는(즉, 한 부분만 정확히 감지한) 샘플에 대해서도 긍정적인 신호를 줄 수 있어, 학습 기회를 확장합니다.
- Findings
- max 함수를 사용했을 때의 성능 향상은 모델이 아직 완벽하게 학습하지 못하여 주체나 객체 중 한 가지 요소만 정확하게 감지한 경우에도 긍정적인 학습 신호를 제공함으로써, 모델이 혼란스러워하는 샘플들을 더 잘 학습하도록 돕기 때문이라고 제안합니다.
- min 함수는 지나치게 보수적이어서 이러한 학습 기회를 제한하게 됩니다.
Quantitative results of quality-aware multi-assignment.
- 배경 문제점
- 기존의 Transformer 기반 VRD(Visual Relationship Detection) 모델 학습을 위한 레이블 할당 방식은 여러 한계점을 가집니다.
- 특히, 하나의 Ground Truth(GT)를 오직 하나의 예측에만 할당하는 제약 때문에, 정답에 가까운 예측들마저도 'no relation'으로 할당되어 학습 신호가 억제되는 문제가 있었습니다.
- CNN 기반 검출기에서 흔히 사용되는 단순 IoU(Intersection over Union) 기반 할당 방식은 Transformer 기반 모델 학습에는 적합하지 않습니다.
- 비교된 레이블 할당 전략: 이 논문에서는 세 가지 주요 레이블 할당 전략을 비교합니다.
- Conventional Assignment (Single):
이것은 기존 방식이며, 하나의 GT를 오직 하나의 예측에만 할당합니다.
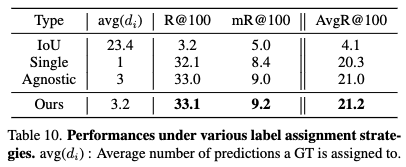
Table 10에서 'Single'로 표시되어 있으며, R@100 32.1, mR@100 8.4, AvgR@100 20.3의 성능을 보입니다. - Quality-Agnostic Multi-Assignment (Agnostic):
이는 GT를 여러 예측에 할당하는 '다중 할당' 방식이지만, 할당되는 예측의 수(d_idid_idi)가 모든 GT에 대해 동일하게 고정됩니다. 즉, 예측의 품질을 고려하지 않습니다. - Table 10에서 'Agnostic'으로 표시되며, Single 방식보다 향상된 R@100 33.0, mR@100 9.0, AvgR@100 21.0의 성능을 보입니다. 이는 다중 할당 자체가 학습에 긍정적인 영향을 미친다는 것을 시사합니다.
- Conventional Assignment (Single):
- Quality-Aware Multi-Assignment (Ours):
- 이 논문에서 제안하는 SpeaQ의 핵심 구성 요소 중 하나입니다.
- 주체, 객체, 관계(술어)에 대한 삼중항 수준의 예측 품질을 종합적으로 고려하여 GT가 할당될 예측의 수(d_idid_idi)를 적응적으로 결정합니다.
- \(d_i\) 는 Equation (8)에서 정의된 v_i (삼중항 품질 벡터)와 top-k 함수를 통해 계산됩니다. 즉, 예측 품질이 높은(GT에 가까운) 예측들에게 더 풍부한 학습 신호(더 많은 할당 기회)를 제공합니다.
- Table 10에서 'Ours'로 표시되며, R@100 33.1, mR@100 9.2, AvgR@100 21.2로 가장 좋은 성능을 달성합니다. 이는 다중 할당에 더해 예측 품질을 고려하는 적응적 할당이 성능 향상에 기여했음을 보여줍니다.
- IoU-based Assignment의 실패
CNN 기반 검출기에서 자주 사용되는 IoU 기반 할당(주체 및 객체의 IoU가 0.5를 초과하는 예측에 GT 할당)은 Transformer 기반 모델 훈련에 완전히 실패했습니다. (Table 10에서 'IoU'로 표시되며, R@100 3.2, mR@100 5.0, AvgR@100 4.1로 매우 낮은 성능을 보임) 이는 Transformer 기반 VRD 모델이 단순 IoU 매칭으로는 효과적으로 학습되기 어렵다는 것을 의미합니다. - 결론: 이러한 실험 결과는 다중 할당 전략, 특히 예측의 품질을 고려하여 할당 수를 조절하는 'Quality-Aware Multi-Assignment' 이 Transformer 기반 VRD 모델의 학습을 효과적으로 개선하고 성능 향상에 크게 기여함을 입증합니다.
Qualitative results.
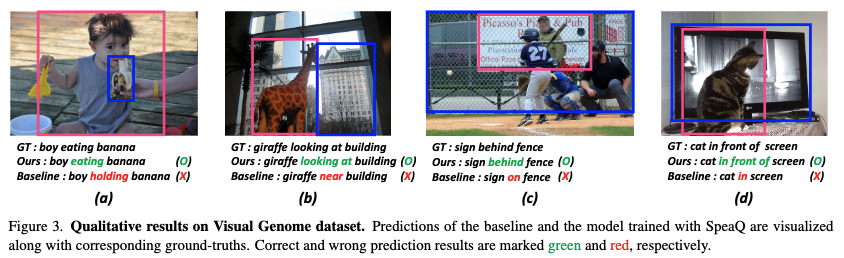
- 정성적 결과 개요: Fig. 3은 기준 모델과 SpeaQ를 통해 훈련된 모델의 예측 결과를 시각적으로 비교합니다. 이를 통해 SpeaQ가 시각적 관계 감지(Visual Relationship Detection, VRD) 작업에서 어떻게 더 나은 성능을 보이는지 정성적으로 입증합니다.
- 도전적인 샘플 감지 능력 향상
- 그림 3의 샘플 (a)와 (b)는 술어(predicate)의 의미론과 이미지에 대한 세부적인 이해가 필요한 어려운 사례를 보여줍니다.
- 예를 들어, (a)에서 기준 모델은 'boy holding banana'로 잘못 예측했지만, SpeaQ는 'boy eating banana'로 정확하게 감지했습니다.
- (b)에서도 기준 모델이 'sign on fence'로 예측한 것을 SpeaQ는 'sign behind fence'로 올바르게 예측했습니다.
이는 SpeaQ를 통해 훈련된 모델이 이러한 미묘한 차이를 더 잘 포착함을 나타냅니다.
- 희귀(Less Common) 술어 감지 능력 향상
- 샘플 (c)와 (d)는 SpeaQ가 데이터셋에서 덜 자주 나타나는(희귀한) 술어를 감지하는 데 효과적임을 보여줍니다.
- 구체적으로, 기준 모델이 각각 'on'과 'in'을 예측했을 때, SpeaQ는 'behind'(17배 덜 흔함)와 'in front of'(18배 덜 흔함)를 정확하게 분류했습니다.
이는 long-tailed property를 가진 VRD 데이터셋에서 희귀한 클래스에 대한 성능 개선이 이루어졌음을 의미합니다. - 개선 원인: 이러한 성능 향상은 SpeaQ에 의해 훈련된 쿼리가 Groupwise Query Specialization 덕분에 특정 술어에 '특화'되었기 때문입니다. 쿼리가 특정 관계에 집중함으로써, 희귀하거나 미묘한 관계도 더 효과적으로 감지할 수 있게 됩니다.
6. Conclusion
- Groupwise Query Specialization (그룹별 쿼리 특화)
- 목적: 기존 Transformer 기반 VRD 모델에서 쿼리가 모든 관계(relation)를 탐지하도록 훈련되어 '비전문적(unspecialized)'이라는 한계를 해결하기 위함입니다.
- 방법: 전체 쿼리(queries)와 관계(relations)를 여러 개의 독립적인 그룹으로 나눕니다. 특정 쿼리 그룹에 속한 쿼리는 해당 그룹에 지정된 관계들만을 탐지하도록 훈련됩니다.
- 효과: 이 방법을 통해 각 쿼리가 특정 관계 그룹에 전문화되어, 모호한 훈련 신호를 줄이고 효율적으로 모델의 잠재력을 활용할 수 있게 됩니다.
- Quality-Aware Multi-Assignment (품질 인식 다중 할당)
- 목적: 기존의 라벨 할당 방식이 하나의 정답(ground-truth, GT)을 오직 하나의 예측(prediction)에만 할당하여, 정답에 가까운 다른 예측들이 '관계 없음'으로 처리되어 훈련 신호가 부족했던 문제를 해결하기 위함입니다.
- 방법: 주체(subject), 객체(object), 그리고 그 사이의 관계(predicate)의 '삼중항 수준(triplet-level)' 예측 품질을 고려하여, 하나의 GT를 여러 개의 '충분히 가까운' 예측에 할당합니다.
- 효과: 이를 통해 모델은 더 풍부하고 긍정적인 훈련 신호를 받아, 특히 좋은 품질의 예측에 대해 효과적인 학습을 할 수 있게 됩니다.
- 연구 결과 요약
- 이러한 SpeaQ의 두 구성 요소를 결합함으로써, 여러 VRD(Visual Relationship Detection) 모델과 벤치마크에서 일관된 성능 향상을 달성했습니다.
- 가장 중요한 점은 이러한 성능 향상이 모델의 매개변수를 추가하거나, 추론(inference) 과정에 추가적인 비용을 발생시키지 않고 이루어졌다는 것입니다. 이는 실제 적용 가능성이 높다는 것을 의미합니다.
Reference
[1] Reformulating HOI Detection as Adaptive Set Prediction
[2] Visual relationship detection using part-and-sum transformers with composite queries
[3] Iterative Scene Graph Generation
[4] Scene Graph Generation by Iterative Message Passing
[5] Neural Motifs: Scene Graph Parsing with Global Context
[6] Stacked Hybrid-Attention and Group Collaborative Learning for Unbiased Scene Graph Generation
[7] Bipartite Graph Network with Adaptive Message Passing for Unbiased Scene Graph Generation