[Paper Review] Privacy-Preserving Text Classification on BERT Embeddings with Homomorphic Encryption (NAACL 2022)

Privacy-Preserving Text Classification on BERT Embeddings with Homomorphic Encryption
Garam Lee, Minsoo Kim, Jai Hyun Park, Seung-won Hwang, Jung Hee Cheon
Abstract
- 텍스트 임베딩의 활용성 및 잠재적 문제점
- 임베딩은 원본 텍스트의 정보를 의미를 보존하는 낮은 차원의 벡터로 압축하여 텍스트 분류 등의 작업에서 효율적으로 활용됩니다.
- 하지만 최근 연구에 따르면, 이러한 임베딩이 텍스트의 민감한 속성에 대한 사적 정보를 잠재적으로 유출할 수 있으며, 심지어 원본 텍스트를 복구하는 데 사용될 수도 있음이 밝혀졌습니다.
- 제안하는 해결책: 동형 암호화 (HE) 기반 개인정보 보호 메커니즘
- 이 논문은 이러한 증가하는 개인정보 보호 문제를 해결하기 위해 동형 암호화(Homomorphic Encryption, HE)에 기반한 임베딩 개인정보 보호 메커니즘을 제안합니다.
- 핵심 방법: 최신 BERT와 같은 모델에서 생성된 임베딩을 암호화한 상태에서 텍스트 분류를 수행합니다. 즉, 데이터가 암호화된 상태로 유지되므로 분류 과정에서 어떤 정보도 외부로 유출되지 않도록 합니다.
- 기술적 구현: CKKS 암호화 방식의 효율적인 GPU 구현을 통해 이를 지원합니다. CKKS는 실수(real numbers) 연산에 적합한 동형 암호화 방식입니다.
- 제안 방법의 이점
- BERT 임베딩에 대한 암호화된 보호를 제공하여 개인정보 유출을 방지합니다.
- 다운스트림 텍스트 분류 작업(예: 감성 분석, 스팸 감지 등)에서 임베딩의 유틸리티(성능)를 크게 보존합니다.
1 Introduction
- 임베딩의 개인 정보 유출 문제
- 텍스트의 임베딩 표현에서 저자의 성별이나 연령과 같은 민감한 정보가 부분적으로 복구될 수 있음이 밝혀졌습니다.
- BERT 기반 문장 임베딩의 경우, 원본 입력 단어의 50%~70%까지 복구될 수 있다는 연구 결과도 있습니다.
- 기존 해결책의 한계 (차등 프라이버시, DP): 이전에는 섭동/노이즈 기반의 차등 프라이버시(Differential Privacy) 방식이 제안되었습니다 [1]. 이 방식은 임베딩에 주입되는 노이즈를 수동으로 제어하여 프라이버시-유틸리티(Privacy-Utility) 간의 균형을 맞춰야 하는 단점이 있습니다.
- Approach: 근사 동형 암호화 (Approximate Homomorphic Encryption, HE)
- 본 연구에서는 임베딩에 대한 개인 정보 보호를 위해 동형 암호화를 기반으로 한 솔루션을 제안합니다.
- 동형 암호화: 암호화된 데이터에 대해 복호화 과정 없이 연산을 수행할 수 있는 암호학적 기법입니다.
- 텍스트 분류 작업에서 BERT 임베딩의 정확도 손실을 거의 없애거나 최소화할 수 있습니다.
- 128비트 보안 수준과 같은 원하는 수준의 암호화 보호를 보장합니다.
- 동형 암호화의 기존 연구 및 본 논문의 차별점
- 이전 연구들은 주로 숫자 데이터에 대한 동형 연산에 초점을 맞췄으며, 텍스트와 같은 비정형 데이터에는 거의 적용되지 않았습니다.
- 텍스트 데이터에 동형 암호화를 적용한 최근 연구로는 [2] 가 RNN을 사용하여 암호화된 단어 임베딩에 대한 감성 분류를 수행했지만, 간단한 임베딩 레이어를 사용하고 모델 학습은 평문에서만 지원했습니다.
- PrivFT [3] 와의 비교: PrivFT는 fastText 기반의 동형 암호화 기반 텍스트 분류 방법으로, 모든 신경망 연산을 암호화된 상태에서 수행합니다. 하지만 본 논문의 방법과는 몇 가지 차이점이 있습니다.
- BERT 임베딩 기반 방법: PrivFT는 사전 훈련을 활용하지 않고 fastText를 사용하여 Bag-of-Words 벡터를 입력으로 받습니다. 이로 인해 임베딩 행렬과 분류기를 처음부터 학습해야 하여 단일 데이터셋 훈련에 며칠이 소요될 수 있습니다. 반면, 본 논문의 방법은 BERT와 같은 최신 모델의 사전 훈련된 임베딩을 활용하여 암호화된 데이터에서 강력한 분류기 (e.g., logistic regression) 를 몇 시간 내에 훈련할 수 있어 훨씬 더 실용적입니다.
BERT Embedding-based Method
- PrivFT의 접근 방식
- 목표: 모든 신경망 연산을 암호화된 상태에서 수행합니다.
- 기반 기술: fastText 를 채택하며, 이는 Bag-of-Words 벡터를 입력으로 받아 2-layer 네트워크와 임베딩 레이어를 거칩니다.
- Limitations
- 사전 학습(pre-training)을 활용하지 않습니다.
- 결과적으로 임베딩 행렬(embedding matrix)과 분류기(classifier)를 처음부터 업데이트해야 하므로, 단일 데이터셋 훈련에 며칠이 소요될 수 있습니다.
- 본 논문의 Approach
- 의미적으로 풍부한 벡터 표현(즉, Pre-trained BERT 임베딩)의 암호화된 상태에서 간단한 다운스트림 분류기 (HE-based logistic regression) 를 작동합니다.
- 성능 향상: BERT와 같은 최첨단 모델에서 사전 학습된 임베딩을 활용하여 PrivFT보다 훨씬 뛰어난 성능을 보입니다.
- 실용성: 암호화된 데이터에 간단한 다운스트림 분류기를 사용함으로써 방법이 훨씬 더 실용적입니다.
- 훈련 효율성: 사전 학습된 임베딩을 활용하여 강력한 분류기를 암호화된 상태에서 몇 시간 내에 훈련할 수 있습니다. 점점 더 커지는 사전 학습된 언어 모델의 언어 이해 능력에 의존하는 최근 NLP 트렌드를 최대한 활용할 수 있도록 잘 구축되어 있습니다.
Better GPU Implementation
- CKKS 스킴: BERT 임베딩은 실수(real-valued vectors)로 구성되어 있습니다. 다른 HE 방식들은 주로 유한 필드(finite fields)에서의 연산에 최적화되어 있는 반면, CKKS 방식은 실수 연산을 효율적으로 지원하기 때문에 BERT 임베딩과 같은 실제 데이터에 적용하기에 더 적합합니다.
- 부트스트랩핑(Bootstrapping) 기능 포함
- PrivFT의 한계: PrivFT의 CKKS 구현은 부트스트랩핑 연산이 없습니다. 부트스트랩핑은 암호문(ciphertext)에 적용할 수 있는 연산의 '레벨(level)'을 초기화하여 곱셈 연산의 횟수 제한(multiplicative depth)을 없애는 기술입니다. 이 기능이 없으면 곱셈 연산 횟수가 제한되어 방법론의 확장성(scalability)이 떨어집니다. 또한, PrivFT는 80-bit 수준의 낮은 보안 매개변수(CKKS parameters)를 사용해야 했습니다.
- 본 논문의 강점: 이 논문의 GPU 구현은 부트스트랩핑 연산을 포함합니다. 이를 통해 무제한적인 곱셈 연산이 가능해지며, 이는 더 높은 차수의 다항식 근사(higher degree polynomial approximation)를 사용하여 텍스트 분류 정확도를 높이는 데 기여합니다. 또한 128-bit의 더 높은 보안 수준을 달성할 수 있습니다.
- Communication Cost 효율화: 이 논문은 실용성을 고려하여 CKKS 구현의 통신 비용을 개선했습니다. 특히, 암호문의 크기를 기존 구현 대비 7.4배 이상 줄여 통신 부하를 크게 감소시켰습니다. 이는 대규모 데이터 처리 시 효율성을 높이는 중요한 개선점입니다.
2 Method
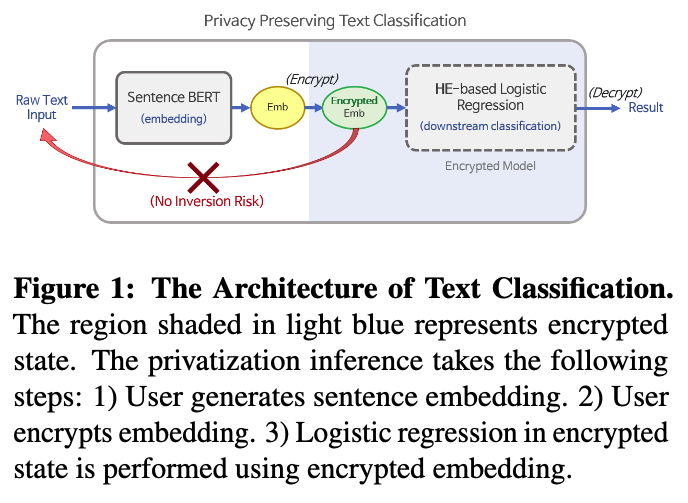
- 로컬 프라이버시 설정(local privacy setting)
- 이 시나리오에서는 사용자가 **신경 텍스트 인코더(neural text encoder)**에서 생성된 임베딩 출력에 직접 개인 정보 보호 메커니즘을 적용합니다.
- 이렇게 개인 정보가 보호된 임베딩을 다운스트림 태스크(downstream task)를 위해 서비스 제공자에게 전달합니다.
- 이는 사용자의 원본 데이터가 서비스 제공자에게 직접 노출되지 않고, 사용자 측에서 미리 개인 정보 보호 처리가 완료된 데이터를 전달함으로써 프라이버시를 강화하는 방식입니다. [1] 에서 이러한 개념이 언급됩니다.
- 개인 정보 보호 절차 M_{priv}(x) = P(F_{emb}(x))
- 이 공식은 원본 텍스트 x 가 개인 정보 보호 처리된 임베딩(privatized embedding) 즉, M_{priv}(x) 으로 변환되는 과정을 나타냅니다.
- x: 원본 텍스트 입력(raw text input)을 의미합니다. 예를 들어, 사용자가 입력한 문장이나 문서 등이 될 수 있습니다.
- F_{emb}: 문장 임베딩(sentence embedding) 을 얻기 위한 사전 학습된 모델(pre-trained model) 인 Sentence-BERT를 지칭합니다. (즉, 텍스트 인코더)
- Sentence-BERT 는 텍스트의 정보를 의미를 보존하는 저차원 벡터(low-dimensional vectors)로 압축하는 역할을 합니다. 이 과정에서 원본 텍스트의 민감한 정보가 임베딩에 포함될 수 있습니다.
- P: 개인 정보 보호 메커니즘(privacy mechanism) 을 의미합니다.
- 동형암호화: 본 연구에서는 주로 동형 암호화(Homomorphic Encryption, HE) 를 사용하여 임베딩을 암호화하는 방식을 제안합니다. 동형 암호화는 데이터를 복호화하지 않고도 암호화된 상태에서 계산을 수행할 수 있게 하는 암호 기술입니다. [4] 에서 CKKS 동형 암호화 스킴의 자세한 내용을 확인할 수 있습니다.
- 전체적인 추론 절차 (Overall Process)
- 사용자
- 원본 텍스트 x 를 Pre-trained Sentence-BERT 를 이용하여 문장 임베딩(sentence embedding) 을 생성합니다.
- 생성된 임베딩에 개인 정보 보호 메커니즘 P (여기서는 동형 암호화)를 적용하여 임베딩을 암호화합니다. 이 결과가 M_{priv}(x) 입니다.
- 서비스 제공자: 암호화된 임베딩 M_{priv}(x) 을 받아 암호화된 상태에서 로지스틱 회귀 모델(logistic regression model) 과 같은 다운스트림 분류 모델(downstream classification model) 을 사용하여 텍스트 분류를 수행합니다. 이 과정에서 데이터가 복호화될 필요가 없으므로 프라이버시가 보호됩니다.
- 결과: 최종적으로 암호화된 분류 결과가 나옵니다. 이 논문에서는 훈련 과정 또한 암호화된 상태에서 수행될 수 있다고 언급합니다.
- 사용자
2.1 Baseline: Local Differential Privacy (LDP)
개인정보 보호를 위한 Machine Learning 기법으로 (Privacy-Preserving ML, PPML) 크게 두가지 방법이 존재합니다.
1. Differential Privacy (DP)
2. Homomorphic Encryption (HE)
본 논문은 텍스트 분류를 위한 HE 기반의 새로운 method 를 제안하는데, 이를 특히 Local DP (LDP) 와 비교하여 실험하였습니다.
- 노이즈 추가 방식 (LDP)
- LDP는 임베딩 벡터 y에 무작위로 샘플링된 노이즈 N을 추가하여 프라이버시를 보장합니다.
- 이는 수식으로 P(y) = y + N 와 같이 표현됩니다.
- 노이즈 N의 구성 요소: N ∈ Rn는 두 가지 구성 요소, r (원점으로부터의 거리)과 p (단위 초구면 Bn의 한 점)로 이루어집니다.
- r은 Gamma 분포에서 샘플링됩니다. 여기서 n은 임베딩 벡터의 차원, eta 는 노이즈의 강도를 조절하는 매개변수입니다. eta 값이 작을수록 더 큰 노이즈가 추가되어 프라이버시 보호 수준이 높아지지만, 유용성은 감소할 수 있습니다.
- p는 n차원 단위 초구면 Bn 위에서 균일하게 샘플링됩니다.
- 최종 노이즈 N은 N = rp와 같이 계산됩니다.
- LDP 적용 범위: [1] 의 연구에서 단일 토큰 임베딩(single-token embeddings)에 노이즈 기반 LDP를 적용했던 것과 동일한 메커니즘이 본 연구에서는 문장 임베딩(sentence embeddings)에 적용됩니다.
HE Based Logistic Regression
- 개인화 메커니즘의 정의
- 사용자의 원본 텍스트 입력 x 에 대해 Pre-trained Sentence-BERT 를 사용하여 문장 임베딩 y 을 생성합니다. 이 임베딩 y 에 개인화 메커니즘 P 를 적용하는데, 이 논문에서는 동형 암호화 H 를 사용하여 P(y) = H(y) 로 정의합니다. 즉, 문장 임베딩 자체를 암호화합니다.
- 이렇게 암호화된 임베딩 Mpriv(x)는 이후 다운스트림 텍스트 분류 작업(예: 로지스틱 회귀)에 암호화된 상태로 전달됩니다.
- CKKS(Cheon-Kim-Kim-Song) 동형암호 스킴 활용
- 대부분의 HE 스킴이 유한체(finite fields) 연산에 최적화되어 있는 반면, CKKS 스킴은 실수를 효율적으로 처리할 수 있어 실제 데이터 적용에 유리하기 때문에 채택되었습니다.
- CKKS는 '레벨드 동형 암호화(levelled homomorphic encryption)' 스킴으로, 각 암호문(ciphertext)은 남은 연산 횟수를 나타내는 '레벨(level)'을 가집니다.
- 두 암호문을 곱하면 레벨이 1 감소하며, 레벨이 너무 낮아지면 더 이상 연산을 수행할 수 없게 됩니다.
- 부트스트래핑(Bootstrapping) 기술: 암호문의 레벨이 낮아졌을 때, 부트스트래핑 기술을 사용하여 레벨을 "새로고침"하여 연산 가능 횟수를 늘릴 수 있습니다. 이는 사실상 무제한적인 곱셈 연산을 가능하게 하여, 복잡한 계산을 수행할 수 있도록 합니다. 이 논문의 GPU 구현에는 부트스트래핑이 포함되어 PrivFT와의 차별점 중 하나로 언급됩니다.
- CKKS 연산 요약
- 암호문 ct1, ct2가 복소수 벡터 메시지 m1, m2를 암호화한 것이라면?
- Add(ct1, ct2): m1 + m2의 암호문을 출력합니다.
- Mult(ct1, ct2): m1 ⊙ m2 (원소별 곱셈)의 암호문을 출력합니다.
- Bootstrap(ct1): 새로고침된 레벨에서 m1의 암호문을 출력합니다.
- 암호문 ct1, ct2가 복소수 벡터 메시지 m1, m2를 암호화한 것이라면?
- 초기 암호화 레벨 조정
- 일반적으로 데이터를 가장 높은 레벨(L)로 암호화하지만, 이 연구에서는 초기 암호문 크기를 줄이기 위해 레벨 3으로 암호화합니다.
- 이를 통해 Twitter 학습 데이터셋에서 10.8GB에서 1.4GB로, SNIPS 학습 데이터셋에서 85.3GB에서 11.4GB로 암호문 초기 크기를 7.4배 이상 줄여 통신 비용을 크게 절감합니다.
- 로지스틱 함수 다항식 근사
- CKKS는 덧셈과 곱셈만 지원합니다. 로지스틱 함수는 다항 함수가 아니므로, 암호화된 상태에서 계산하기 위해서는 다항식으로 근사해야 합니다.
- 이 연구에서는 구간 [-12, 12] 에서 0.00614의 오차 내에서 로지스틱 함수를 근사하는 15차 미니맥스 근사 다항식(minimax approximate polynomial)을 사용합니다.
- 이러한 접근 방식을 통해 이 논문은 BERT 임베딩의 유용성을 유지하면서도 강력한 암호화 보호 기능을 제공하며, 기존 연구인 PrivFT [3] 보다 훨씬 효율적인 학습 성능을 보여줍니다.
2.3 Datasets
- Tweets Hate Speech Detection: Is a crowd-sourced dataset of Tweets for binary classification
- SNIPS: Is a dataset of crowd-sourced queries collected from the Snips Voice Platform, distributed among 7
user intents. - Youtube Spam Collection: Is a public data set collected for spam research from UCI Machine Learning
Repository, where five datasets are composed by 1,956 real messages extracted from five videos.
3 Experiments
3.1 Encrypted Sentence Classification
- 임베딩 추출 및 모델 선택
- 먼저 Pre-trained Sentence-BERT 를 사용하여 입력 텍스트로부터 문장 임베딩(sentence embeddings)을 추출합니다.
- 이 임베딩 벡터는 768개의 32비트 부동 소수점(floating point) 값으로 구성되며, 값의 범위는 -1에서 1 사이입니다. 추출된 임베딩은 후속(downstream) 분류 모델의 입력으로 사용됩니다. 본 연구에서는 로지스틱 회귀(Logistic Regression) 모델을 사용합니다.
- Twitter 데이터셋에는 이진 분류(binary classification)를, SNIPS 데이터셋에는 다중 클래스 분 (multiclass classification)를 수행합니다.
- 다중 클래스 분류는 One-vs-Rest (OvR) 방식을 사용하여 각 클래스에 대해 여러 개의 이진 로지스틱 회귀 모델을 학습시킨 후, 그 결과들을 결합하여 argmax를 취하는 방식으로 진행됩니다.
- 동일한 Setting 에서 비교를 위한 구현: 평문(plaintext) 모델과 암호문(ciphertext) 모델 간의 공정한 비교를 위해 두 모델 모두 동일한 로지스틱 회귀 구현을 사용합니다. 노이즈 기반의 지역 차분 프라이버시(Local Differential Privacy, LDP) 실험도 동일한 프라이버시 메커니즘을 사용하여 평문 상태에서 진행됩니다.
- 모델 학습 및 하이퍼파라미터
- 모든 모델의 로지스틱 회귀 파라미터는 Nesterov momentum을 사용한 SGD(Stochastic Gradient Descent)로 최적화됩니다.
- 최적의 성능을 위한 모델과 F1 점수에 대한 최적 임계값은 검증(validation) 세트 성능을 기반으로 결정됩니다.
- 평문 실험 하이퍼파라미터
- Twitter 데이터셋: 학습률(Learning rate) 3.0, 감마(gamma) 0.9, 배치 크기(batch size) 256.
- SNIPS 데이터셋: 학습률 3.0, 감마 0.1, 배치 크기 128.
- 두 모델 모두 10 에포크(epochs) 동안 학습되었습니다.
- CKKS 암호화 파라미터
- 동형 암호화(Homomorphic Encryption, HE) 기법 중 CKKS 스킴을 사용합니다.
- 차원(dimension) N = 2^{17} 을 선택하고, 최대 계수(modulus) q_L 의 크기를 1540 비트로 설정했습니다.
- CKKS 파라미터는 128비트 보안 수준을 만족합니다 [5].
- 암호문 실험 하이퍼파라미터
- Twitter 데이터셋: 학습률 3.0, 감마 0.9, 배치 크기 512.
- SNIPS 데이터셋: 학습률 2.0, 감마 0.1, 배치 크기 512.
- 두 모델 모두 10 에포크 동안 학습되었습니다.
- GPU 가속화 및 하드웨어
- 암호화된 로지스틱 회귀 모델을 위해 CKKS의 부트스트래핑(bootstrapping) 연산을 위한 효율적인 병렬 GPU 구현을 개발했습니다.
- 실험에는 24GiB 메모리의 듀얼-NVLink Nvidia Quadro RTX6000 GPU와 Intel Xeon Gold 6242R CPU(80코어) 및 125GiB RAM을 갖춘 서버가 사용되었습니다.
- 관련 연구와의 연결
- 본 논문은 임베딩의 잠재적인 정보 유출 문제에서 BERT 기반 문장 임베딩이 최대 50%~70%의 입력 단어를 복구할 수 있는 위험 [6] 에 대한 해결책을 제시합니다.
- 기존의 차분 프라이버시(differential privacy) 방식이 프라이버시-유틸리티 간의 수동적인 균형 조절을 요구하는 반면, 본 연구는 동형 암호화를 통해 BERT 임베딩의 정확도 손실을 최소화하면서 128비트 보안 수준을 제공합니다.
- PrivFT 와 비교하여, 본 연구는 BERT 임베딩을 활용하여 학습 효율성을 크게 개선하고 더 높은 정확도를 달성하며, GPU 구현에서 부트스트래핑 연산을 포함하여 더 높은 보안 수준과 확장성을 제공합니다.
3.2 Embedding Inversion
- 임베딩 역변환(Embedding Inversion) [6]
- 이는 텍스트의 임베딩(embedding)으로부터 원래 텍스트(토큰)를 복구하는 것을 목표로 하는 적대적 공격(adversarial attack)의 한 형태입니다.
- 압축된 정보 형태인 임베딩에서 원본 데이터를 역추적하여 추출하려는 시도입니다.
- 블랙박스 역변환(Black-box inversion)
- 이 논문에서 중점적으로 다루는 임베딩 역변환의 한 종류입니다.
- 공격자는 모델에 쿼리를 전송하여 임베딩을 얻는 방식으로만 상호작용할 수 있습니다. 즉, 모델의 내부 구조나 가중치에 직접 접근할 수 없는 상황을 가정합니다.
- 이는 실제 환경에서의 개인 정보 보호 문제를 고려할 때 더욱 적절한(pertinent) 시나리오로 간주됩니다.
4 Results
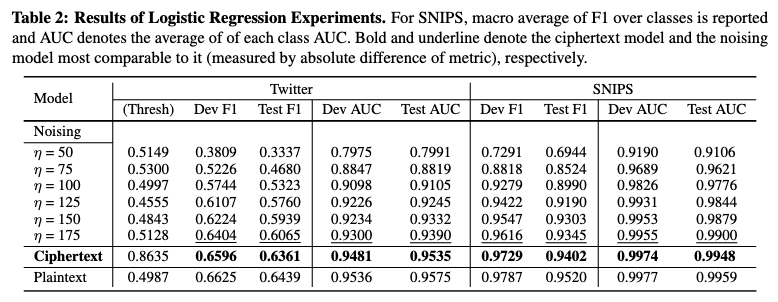
- Ciphertext 방식의 우수성
- 이 논문에서 제안하는 동형 암호화 기반의 'Ciphertext' 분류기는 Twitter 및 SNIPS 데이터셋에서 Plaintext 기준선 분류기의 성능에 각각 F1/AUC 기준으로 약 98.79%/99.58% 및 98.76%/99.89%에 달하는 높은 유용성(utility)을 유지했습니다.
- 이는 암호화된 상태에서도 BERT 임베딩의 유용성을 크게 보존함을 의미합니다.
- 특히 [1] 에서 고려된 모든 노이즈 수준(η=175까지)에서 LDP 방식보다 더 나은 성능을 보여주며, Plaintext 모델에 거의 근접합니다.
- LDP 방식의 한계
- 노이즈 기반 LDP 방식은 프라이버시 보호를 강화(η 값을 작게 조절)할수록 분류 성능이 저하되는 명확한 상충 관계(trade-off)를 보입니다. 즉, η 값이 50, 75와 같이 작아질수록 성능 감소 폭이 커지는 것을 확인할 수 있습니다.
- 또한, LDP는 임의의 합리적인 η 수준에서도 정보 역추적(inversion risk)을 완전히 제거할 수 있다고 보장하지는 못합니다.
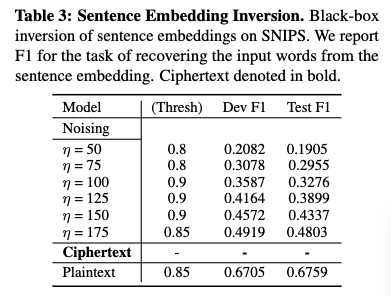
- 문장 임베딩 역변환(Sentence Embedding Inversion)
- 이것은 적대적 공격의 한 형태로, 임베딩 벡터로부터 원본 텍스트(단어 토큰)를 복구하는 것을 목표로 합니다.
- 이 연구에서는 공격자가 임베딩을 얻기 위해 모델에 쿼리만 할 수 있는 '블랙박스 역변환(black-box inversion)'에 초점을 맞춥니다. 이는 실제 환경의 개인 정보 보호 문제와 더 관련이 깊습니다.
- [6] 의 연구에서 BERT 기반 문장 임베딩이 최대 59.76의 F1 점수로 역변환될 수 있음이 보고되었는데, 이는 임베딩에 높은 역변환 가능성(invertibility)이 있음을 시사합니다.
- 노이즈 기반 LDP (Local Differential Privacy)와의 비교
- LDP의 특성: [1] 에서 제안된 노이즈 기반 LDP는 임베딩에 임의의 노이즈를 추가하여 개인 정보 보호를 달성합니다.
- 개인 정보 보호-유틸리티 트레이드오프: η 값에 따라 개인 정보 보호 수준이 달라집니다. η 값이 작을수록 더 많은 노이즈가 추가되어 개인 정보 보호 수준은 높아지지만, 텍스트 분류 성능(유틸리티)은 저하되는 명확한 트레이드오프가 존재합니다.
- 역변환 위험: LDP는 η를 낮게 설정해야 역변환 위험을 크게 줄일 수 있지만, 이는 분류 성능 희생으로 이어집니다. 또한, 어떤 합리적인 η 수준에서도 역변환 위험을 완전히 제거한다고 보장할 수 없습니다.
- 동형 암호화(Homomorphic Encryption, HE) 기반 방법
- 블랙박스 역변환 방지: 이 논문에서 제안하는 HE 기반 방법은 모든 HE 추론 결과가 암호화된 상태로 유지되기 때문에, 사용자의 비밀 키 없이는 복호화될 수 없습니다. 따라서 공격자는 원본 임베딩에 접근할 수 없으므로 블랙박스 역변환 공격이 사실상 불가능합니다.
- 높은 보안 수준과 유틸리티 유지: 128비트 보안 수준의 동형 암호화를 통해 역변환으로부터 사실상 완전한 보호를 보장하면서도, BERT 임베딩의 유용성(텍스트 분류 성능)을 크게 유지합니다. 실제 실험 결과, HE 분류기는 Plaintext 기준 분류기 성능의 약 98.79% (Twitter) 및 98.76% (SNIPS)의 F1 점수를 달성하여 거의 동일한 성능을 보입니다.
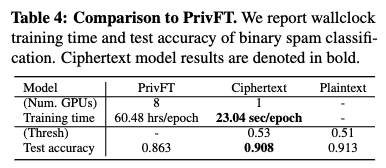
- 제안된 모델(Ciphertext) 결과
- 정확도: 단일 GPU를 사용하여 90.8%의 테스트 정확도를 달성했습니다.
- 훈련 시간: 이 정확도를 달성하는 데 총 460.81초가 소요되었습니다. 테이블 4에 따르면, 제안된 모델의 에포크(epoch)당 훈련 시간은 23.04초입니다.
- PrivFT 결과
- 정확도: 8개의 GPU를 사용하여 86.3%의 테스트 정확도를 얻었습니다.
- 훈련 시간: 이 정확도를 얻는 데 총 5.04일이 필요했습니다. 테이블 4에 따르면, PrivFT의 에포크당 훈련 시간은 60.48시간입니다.
- 성능 비교 요약
- 훈련 속도: 제안된 모델은 에포크당 약 9,450배 더 빠른 훈련 속도를 보여주었습니다. (60.48시간은 초로 환산 시 약 217,728초이므로, 217,728초 / 23.04초 ≈ 9450입니다.)
- 정확도: 제안된 모델이 PrivFT보다 더 높은 테스트 정확도(90.8% vs 86.3%)를 달성했습니다.
- GPU 효율성: 제안된 모델은 PrivFT가 사용한 GPU 수의 1/8 (단일 GPU)만을 사용했습니다.
- Performance 차이가 나는 이유 ?
- PrivFT 는 사전학습 모델의 임베딩을 활용하지 않기에, 문서를 임베딩하기 위해 암호화된 상태로 2-layer NN 을 학습합니다
- 반면에, 본 연구에서는 문서의 압축된 임베딩은 사전학습된 SBERT 를 통해 얻고 오직 간단한 분류기인 logistic regression 모델만을 학습합니다.
5 Conclusion
- 주요 성과: 제안하는 방법은 BERT 임베딩에 동형 암호화를 적용하여 개인 정보 보호 텍스트 분류를 수행합니다. 이를 통해 다운스트림(downstream) 작업에서 유틸리티(utility) 손실을 거의 또는 전혀 발생시키지 않으면서 효율적인 훈련을 가능하게 합니다.
- 기존 방법과의 비교
- 노이즈 기반 LDP(Local Differential Privacy): 노이즈 기반 LDP 방식과 비교했을 때, 제안하는 방식이 훨씬 더 나은 성능을 보여줍니다.
- LDP는 개인 정보 보호 수준을 높일수록 성능 저하가 커지는 트레이드오프(trade-off)가 발생하지만, 본 연구의 HE 기반 방식은 높은 보안 수준(128-bit security)을 유지하면서도 성능 손실이 미미합니다.
- PrivFT: 기존의 PrivFT(PrivFT)와 비교하여, 사전 학습된 BERT 임베딩을 활용함으로써 훈련 효율성과 정확도 면에서 큰 개선을 이루었습니다. PrivFT는 텍스트 분류를 위해 모델을 처음부터 학습해야 하는 반면, 이 논문의 방법은 사전 학습된 임베딩을 사용하므로 훨씬 빠르게 강력한 분류기를 훈련할 수 있습니다.
- Limitations: HE 기반 모델은 평문(plaintext) 모델에 비해 여전히 높은 계산 비용을 요구합니다. 이로 인해 신경망(neural networks)과 같은 더 복잡한 모델을 다운스트림 분류기로 채택하는 데는 어려움이 있습니다.
- 적용 가능성: 이러한 계산 비용의 한계에도 불구하고, 제안된 방법은 개인 정보 보호의 이점과 효율성 덕분에 실제 개인 정보 보호 문제가 중요한 시나리오에 적합한 솔루션임을 시사합니다.
- Future Work
- 본 논문은 동형 암호화를 실제 자연어 처리(NLP) 태스크에 적용하려는 시도 중 하나로, 특히 PrivFT와 같은 이전 연구들이 해결하지 못했던 사전 학습 모델의 활용 및 효율성 문제를 개선했습니다. [7] 는 암호화된 단어 임베딩에 RNN을 사용하여 감성 분류를 시도했지만, 단순한 임베딩 레이어를 사용하고 훈련이 평문에서만 지원되는 한계가 있었습니다.
- 본 논문은 이러한 한계를 극복하고 BERT와 같은 최첨단 모델의 임베딩에 HE를 적용하여 암호화된 상태에서 텍스트 분류를 수행함으로써, 민감한 정보 유출 위험을 줄이면서도 높은 유용성을 유지할 수 있음을 보여줍니다. 이는 [8] 에서 제시된 개인 AI의 실현 가능성을 높이는 중요한 진전으로 볼 수 있습니다.
- 더 복잡한 딥러닝 모델, 예를 들어 더 깊은 신경망 구조나 트랜스포머 기반 모델을 암호화된 상태에서 효율적으로 훈련하고 추론하는 방법에 대한 추가 연구가 필요할 것입니다.
Reference
[1] Natural Language Understanding with Privacy-Preserving BERT
[2] Classification of Encrypted Word Embeddings using Recurrent Neural Networks
[3] PrivFT: Private and Fast Text Classification With Homomorphic Encryption
[4] Homomorphic Encryption for Arithmetic of Approximate Numbers
[5] A Sage Module for estimating the concrete security of Learning with Errors instances
[6] Information leakage in embedding models
[7] Classification of Encrypted Word Embeddings using Recurrent Neural Networks
[8] Private AI: Machine Learning on Encrypted Data