[Paper Review] Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation (AAAI 2024)

Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation
(AAAI 2024)
YoungJoon Yoo, Jongwon Choi
Abstract
- 핵심 아이디어: TVQ-VAE는 VQ-VAE(Vector-Quantized Variational Auto-Encoder)에서 얻은 latent codebook (latent codebooks = 이산적인 feature representation)을 활용하여 토픽 모델링을 수행합니다.
- latent codebook 의 역할: VQ-VAE의 latent codebook 은 미리 학습된 임베딩 (PLM 의 임베딩)과 같은 정보들을 이산적인 (discrete) 형태로 압축하고 캡슐화하는 역할을 합니다.
- 새로운 해석: 이 논문은 이러한 잠재 코드북과 임베딩을 '개념적인 Bag-of-Words(conceptual bag-of-words)'로 새롭게 해석합니다. 기존 Bag-of-Words가 단어의 빈도로 문서를 표현했다면, TVQ-VAE에서는 latent codebook 이 특정 개념이나 의미를 대표하는 단위 역할을 합니다.
- 제안하는 TVQ-VAE 모델 (Topic-VQ-VAE)
- 개념적 Bag-of-Words 표현을 바탕으로, 특정 latent codebook (또는 토픽)과 관련된 원래 문서를 역으로 생성하는 생성 모델입니다.
- 유연한 생성 및 시각화: TVQ-VAE의 장점은 다양한 생성 분포를 통해 토픽을 시각화하고 문서를 생성할 수 있다는 점입니다. 전통적인 Bag-of-Words 분포 형태의 문서 생성은 물론, 자기회귀 모델을 이용한 이미지 생성까지 가능합니다.
- 성능 입증: 문서 분석 및 이미지 생성 태스크에 대한 실험 결과는 TVQ-VAE가 데이터셋의 숨겨진 구조를 잘 나타내는 토픽 컨텍스트를 효과적으로 파악하며, 유연한 형태의 문서 생성을 지원함을 보여줍니다.
cf. Latent Codebook 이란?
- 정의: 잠재 코드북은 학습 가능한(trainable) 벡터들의 유한한 집합입니다. 이 집합의 각 벡터를 코드 벡터(code vector) 또는 코드북 엔트리(codebook entry) 라고 부릅니다. VQ-VAE는 입력 데이터를 인코더를 통해 연속적인 잠재 공간 표현으로 변환한 후, 이 연속적인 표현과 코드북에 있는 벡터들 중 가장 가까운 벡터를 찾습니다.
- 작동 방식: VQ-VAE의 인코더가 입력 데이터를 연속적인 잠재 표현으로 변환하면, 벡터 양자화기(Vector Quantizer) 는 코드북내에서 x 에 가장 가까운 코드 벡터 f = Enc(x) 를 찾습니다. 그리고 이에 해당하는 원-핫 벡터를 생성합니다. 이 과정은 다음과 같이 표현될 수 있습니다.
- 역할: 잠재 코드북을 사용함으로써 VQ-VAE는 연속적인 잠재 공간을 이산적인 코드 시퀀스로 표현할 수 있습니다. 이는 이미지나 텍스트와 같은 복잡한 데이터를 예측하기 쉬운 이산적인 토큰의 시퀀스로 변환하여 자기회귀 모델 등으로 효율적으로 모델링할 수 있게 해줍니다.
Introduction
- 대규모 데이터셋 활용의 필요성: 최근에는 GloVe, BERT, CLIP와 같은 사전 학습된 임베딩(pre-trained embeddings)이 등장했습니다. 이러한 임베딩은 대규모 데이터셋의 풍부한 정보를 담고 있지만, 기존 토픽 모델링 방식에 이 정보를 효과적으로 통합하는 것이 주요 과제입니다.
- 기존 방식의 한계: 전통적인 토픽 모델링 (Latent Dirichlet Allocation 등)은 문서 내 단어들의 공동 출현 빈도를 기반으로 하는 BoW(Bag-of-Words) 방식을 주로 사용했습니다. 이는 특정 단어의 의미나 문맥적 정보를 충분히 반영하지 못하는 한계가 있습니다.
- 임베딩 활용 연구: 이러한 한계를 극복하기 위해 많은 후속 연구들이 사전 학습된 임베딩을 토픽 모델링에 활용하는 방법을 탐구했습니다.
- Generative approach: ETM 와 같이 생성적(generative) 모델링 프레임워크 내에서 임베딩을 사용했습니다.
- Clustering approach: 다른 일부는 BERTopic처럼 비생성적(non-generative) 방식으로 임베딩을 활용하여 토픽을 추출했습니다.
- Generative model 의 발전: 최근 자동 회귀(autoregressive) 모델이나 Diffusion 모델과 같은 심층 생성 모델(deep generative studies)의 발전으로 인해, 토픽 기반 문서 생성 방식도 BoW 형태를 넘어 더욱 유연하고 다양한 형태로 발전해야 할 필요성이 커지고 있습니다.
- 문제 인식: 기존 토픽 모델링 방법은 BoW(Bag-of-Words) 형태의 문서 생성에 국한되어 있으며, 대규모 사전 학습 임베딩 정보를 효과적으로 활용하는 데 어려움이 있었습니다. 또한, 최근의 발전된 생성 모델(예: 오토회귀, 확산 모델)에 맞춰 토픽 기반 생성이 보다 유연해질 필요가 있었습니다.
- 새로운 접근 방식
- 저자들은 이러한 문제를 해결하기 위해 VQ-VAE(Vector-Quantized Variational Auto-Encoder)에서 얻은 VQ 임베딩(Vector-Quantized embeddings)을 활용하는 TVQ-VAE를 제안합니다.
- VQ 임베딩의 새로운 해석: 기존의 VQ 임베딩을 토픽으로 간주했던 이전 연구(Vector-Quantization-based topic modeling, Neural Topic Modeling via Discrete Variational Inference)와 달리, TVQ-VAE에서는 각 VQ 임베딩을 개념적으로 정의된 단어('conceptual words')의 임베딩으로 해석합니다.
- Latent Codebook: 이러한 관점에서, VQ 임베딩들로 구성된 코드북(codebook)은 해당 개념 단어들의 BoW 표현 역할을 합니다. 즉, 코드북 자체가 문서의 토픽 정보를 나타내는 유연한 기반이 됩니다.
- 내재적 토픽 학습: 코드북은 그 자체로 내재적인(implicit) 토픽 학습자 역할을 하며, 이를 조정함으로써 정확한 토픽 문맥을 포착할 수 있음을 보여줍니다.
- 향상된 유연성: 이러한 새로운 해석 덕분에 TVQ-VAE는 기존 BoW 형태를 넘어 다양한 형식의 샘플 생성(flexible format of sample generation)을 지원하는 유연성을 확보하게 됩니다.
- TVQ-VAE: TVQ-VAE는 VQ-VAE [1] 를 기반으로 하며, 특히 이미지-텍스트 생성 모델 [2] 에서 중요하게 사용되는 VQ 임베딩의 잠재력을 토픽 모델링에 접목했다는 점에서 기존 연구와 차별화됩니다. 이전 VQ 기반 토픽 모델들이 VQ 임베딩을 '토픽 그 자체'로 보았던 한계를 극복하고, 'conceptual words'로 해석하여 토픽 모델링 및 생성의 유연성을 높였다는 점이 이 논문의 핵심 기여 중 하나입니다.
- TVQ-VAE 의 강점
- 유연한 문서 생성(Flexible Document Generation): TVQ-VAE는 기존의 일반적인 VAE 처럼 BoW 스타일 문서 생성뿐만 아니라, 더 일반적인 형태의 문서 생성도 동시에 지원합니다. 이는 모델이 추출된 토픽 정보를 바탕으로 다양한 종류의 데이터를 생성할 수 있음을 의미합니다.
- 두 가지 주요 적용 분야
- 문서 클러스터링 및 단어 집합(Set-of-words) 스타일 토픽 추출: 토픽 모델링 분야의 기본적인 문제로, Sentence-BERT 와 같은 PLM 임베딩에서 파생된 코드북을 활용합니다.
- 자기회귀 이미지 생성(Autoregressive Image Generation): VQ-VAE 프레임워크와 잠재 코드북 시퀀스 생성을 결합하여 이미지를 생성합니다. 이는 토픽 정보를 활용하여 이미지의 특성을 제어하며 생성할 수 있음을 보여줍니다.
Main Contributions
- VQ-VAE: A novel generative topic modeling framework
- 이 논문은 VQ-VAE(Vector-Quantized Variational Auto-Encoder)의 잠재 코드북(latent codebooks)을 활용하는 TVQ-VAE라는 새로운 생성 토픽 모델링 프레임워크를 제안합니다.
- VQ-VAE는 연속적인 임베딩 공간을 이산적인 코드북으로 양자화하는 모델입니다. TVQ-VAE는 이 코드북과 임베딩을 "개념적 단어(conceptual word)"로 새롭게 해석합니다. 'conceptual words' 에서 토픽 정보를 추출하며, 이를 통해 유연한 샘플링(sampling)을 가능하게 합니다. 이는 기존 토픽 모델이 단어를 BoW(Bag-of-Words) 형태로 다루는 것과 대비되는 접근 방식입니다.
- 토픽 기반 샘플링을 위한 일반적인 확률론적 방법론 제공
- TVQ-VAE는 토픽에 따라 데이터를 생성하는 "토픽 기반 샘플링"을 위한 일반적인 확률론적 방법론을 제공합니다.
- 이 모델은 전통적인 BoW 스타일의 단어 분포 샘플부터 이미지와 같은 다양한 형태의 데이터를 생성하는 자기회귀(autoregressive) 샘플러까지 유연하게 적용 가능함을 보여줍니다. 이는 토픽 모델링의 응용 범위를 확장합니다.
- 두 가지 데이터 도메인에서의 광범위한 분석 및 모델 강점 입증
- TVQ-VAE의 강점을 입증하기 위해 두 가지 다른 데이터 도메인에서 광범위한 실험을 수행했습니다.
- 기존 토픽 모델의 고전적인 문제인 문서 클러스터링과 단어 집합(set-of-words) 스타일 토픽 추출
- 토픽 추출과 결합된 자기회귀 이미지 생성
- 두 도메인에서의 실험 결과: TVQ-VAE가 데이터의 기저 구조를 효과적으로 포착하고 유연한 형태의 문서 생성을 지원함을 보여줍니다.
Preliminary
Key Components of Topic Model
- 토픽 모델의 두 가지 핵심 목표
- 문서 전체에 대한 의미론적 토픽 마이닝
- 발견된 주제에 기반한 문서 클러스터링 (document clustering)
- 토픽 할당 과정
- 토픽 모델은 기본적으로 각 문서를 K개의 토픽 중 하나에 할당합니다. 이는 토픽이 주어졌을 때 문서들을 그룹화하는 클러스터링 과정입니다.
- 이 할당은 결정론적일 수도 있고, 각 문서의 토픽 분포를 정의함으로써 생성적으로 이루어질 수도 있습니다.
- 고전적 확률론적 생성 토픽 모델
- LDA (Latent Dirichlet Allocation), ProdLDA 등은 각 문서 d를 BoW 로 해석하고, 위 공식들 (1)과 (2)를 통해 결합 분포를 근사 베이지안 추론(Approximate Bayesian Inference) 방법을 사용하여 분석합니다.
- 이러한 확률론적 프레임워크는 각 문서 내에서 단어들이 함께 나타나는 경향(co-occurrence tendency)을 반영합니다.
- 임베딩이 적용된 토픽 모델
- 단어 임베딩(e.g., Word2Vec, PLM)을 토픽 모델링에 적용하려는 시도도 이루어졌습니다.
- 일부 임베딩 기반 토픽 모델(e.g., ETM)은 단어 생성 능력을 유지하며 확률론적 프레임워크에 단어 임베딩을 포함합니다.
- 비생성적인 임베딩 토픽 모델(e.g., 최근 PLM 기반 모델)은 복잡한 베이지안 추론 근사를 우회하고 거리 기반 클러스터링 방법을 통해 토픽 임베딩을 직접 추출하며, 후처리 단계를 활용하기도 합니다.
Vector Quantized Embedding
- 일반적인 VAE 와의 차이점
- 기존 오토인코더는 입력을 연속적인 잠재 공간(continuous latent embedding space)의 임베딩으로 매핑합니다.
- 반면, VQ-VAE는 잠재 공간을 이산적(discrete) (Neural discrete representation learning) 으로 구성합니다.
- VQ 임베딩 (ϱ)
- VQ-VAE는 '코드북(codebook)'이라고 불리는 사전에 정의된 이산적인 임베딩 벡터 집합 ϱ를 사용합니다. 각 벡터 ρn은 Dρ 차원을 가집니다.
- 이산 잠재 공간의 크기는 원래 단어의 총 개수보다 훨씬 작습니다. Dρ는 각 잠재 임베딩 벡터의 차원입니다.
- 벡터 양자화기 (Q, Vector Quantizer): VQ-VAE의 인코더(Enc)는 입력(x)을 연속적인 잠재 변수 f로 변환합니다. 벡터 양자화기 Q는 이 연속적인 f를 가장 가까운 VQ 임베딩 ρx로 대체합니다. 이 ρx는 코드북 ϱ에 있는 임베딩들 중 f와 가장 가까운 벡터입니다.
- Codebook: 양자화 과정에서 선택된 VQ 임베딩 ρx는 대응하는 원-핫(one-hot) 인코딩된 코드북으로 표현됩니다. 코드북은 Nρ 크기의 벡터로, 선택된 임베딩의 인덱스 위치만 1이고 나머지는 0입니다.
- 이미지 적용 (수식 4): 이미지(x)가 VQ-VAE의 입력으로 주어지면, 인코더는 이미지의 공간적 특징을 나타내는 특징 맵 f를 출력합니다. 벡터 양자화기는 이 특징 맵의 각 공간적 위치(i, j)에 해당하는 특징 fij를 처리하여, 가장 가까운 VQ 임베딩 ρij와 이에 대응하는 코드북 cij를 찾습니다. 결과적으로 이미지 전체에 대한 양자화된 벡터 시퀀스 ρ와 코드북 시퀀스 c를 얻게 됩니다.
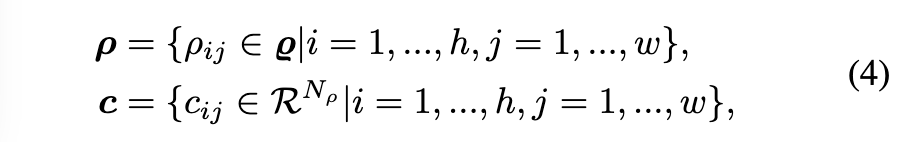
- 디코더의 역할: VQ-VAE의 디코더(Dec)는 이 양자화된 코드북 시퀀스 c와 임베딩 ρ를 사용하여 원래 이미지(x)를 재구성(reconstruct)합니다.
Methodology
Vector Quantized Embedding as Conceptual Word
- "Conceptual word" 의 정의
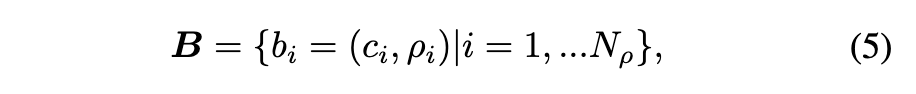
- B: 이산 잠재 공간의 크기, 즉 VQ 임베딩 또는 코드북 엔트리의 총 개수입니다.
- 이 정의에 따르면, 각 개념어 b_i 는 특정 VQ 임베딩 i 와 그에 대응하는 코드북 c_i 의 쌍으로 구성됩니다. 개념어의 수는 VQ 임베딩의 총 개수 i 와 동일합니다.
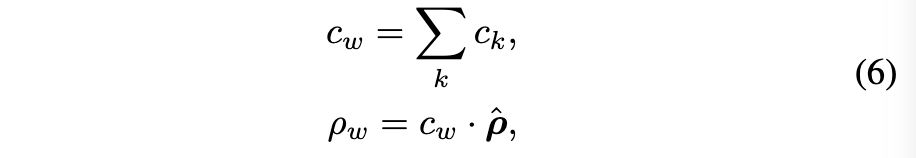
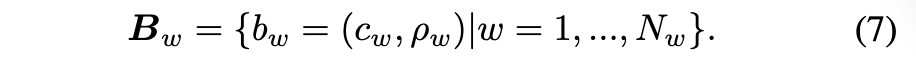
- 멀티-핫(Multi-hot) 표현으로의 확장 (Equation 6 & 7)
- 일반적으로 VQ 임베딩의 개수는 원래 어휘집의 크기 i 에 비해 훨씬 작습니다. 이는 모든 단어를 단일 VQ 임베딩으로 표현하기 어렵게 만듭니다. 이를 해결하고 코드북이 더 큰 어휘집을 다룰 수 있도록 하기 위해, 논문에서는 코드북 표현을 원-핫에서 멀티-핫 벡터로 확장합니다.
- 주어진 단어와 VQ-VAE 인코더를 통과한 그 임베딩 b_i 에 대해, 가장 가까운 K개 (K-nearest neighbor) 의 VQ 임베딩를 사용하여 N 의 양자화된 임베딩 N 를 표현합니다. 이는 다음과 식 (6) 과 같이 계산됩니다.
- Conceptual Word 로의 해석: TVQ-VAE는 VQ 임베딩과 코드북을 '개념어'로 재해석하고, 이를 멀티-핫 표현으로 확장하여 원래 어휘집의 단어를 유연하게 표현합니다. 이 개념어 집합 N_w 가 이후 TVQ-VAE의 토픽 모델링 과정에 사용됩니다.
Generative Formulation for TVQ-VAE
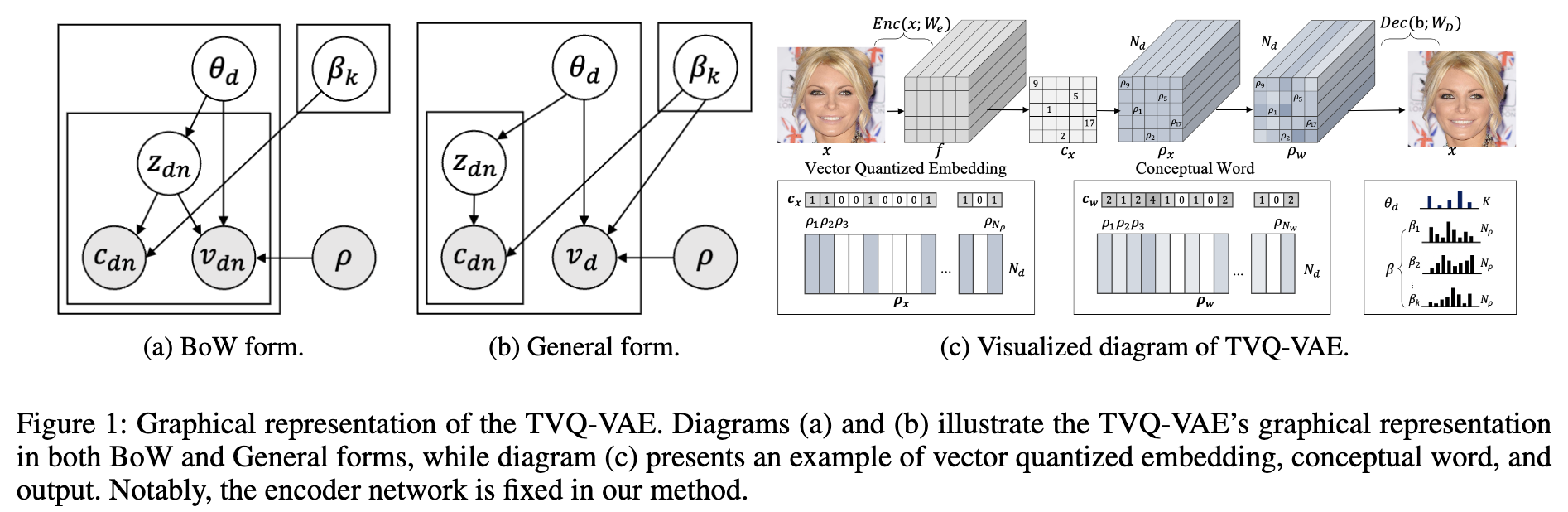
- 다양한 출력 형태 (vd)
- Set-of-word 스타일 (그림 1a)
- 가장 일반적인 텍스트 기반 출력 형태입니다.
- vd는 문서 d에 해당하는 단어 집합으로 정의됩니다.
- 각 단어 vdn은 원래 단어의 원-핫 인코딩을 나타내며, 이는 벡터 양자화(Vector-Quantized, VQ) 임베딩의 코드북에 해당합니다.
- 이미지 형태 (그림 1b, General form)
- vd는 문서 d에 해당하는 이미지로 정의될 수 있습니다.
- 이는 TVQ-VAE가 텍스트뿐만 아니라 이미지를 포함하는 다양한 형태의 문서를 생성할 수 있음을 보여줍니다.
- Set-of-word 스타일 (그림 1a)
- Random variable 들의 결합 분포 (Equation 8):
- 모델의 모든 랜덤 변수의 관계를 확률적으로 설명합니다. 결합 분포는 식 (8) 과 같이 공식화됩니다.
- 식 (8) 은 LDA 또는ETM 와 같은 기존 생성 토픽 모델의 일반적인 정식화와 유사합니다. TVQ-VAE의 특징은 BoW 형태를 넘어선 다양한 출력을 지원한다는 점입니다. 이는 보다 자연스러운 문서생성을 뜻합니다.
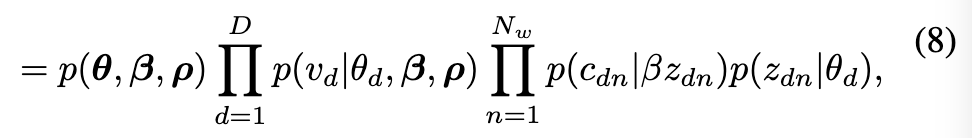
- Set-of-word 생성을 위한 확률 분포 (Equation 9)
- 문서 d의 각 출력 단어 v_dn이 해당 단어의 토픽 할당 z_dn에 따라 생성될 확률을 나타냅니다.
- 식 (9) 은 각 단어가 문서의 토픽 분포 theta_d 에 의해 가중된 각 토픽 beta 으로부터 생성될 확률을 고려하여 생성됨을 의미합니다.
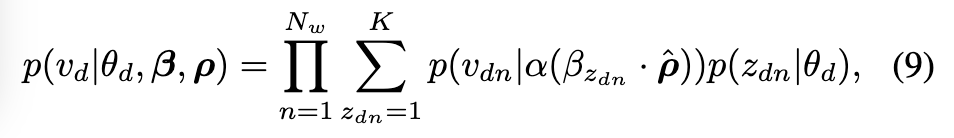
- 일반적인 경우의 Generative process
- 전통적인 BoW 형태 문서 생성을 넘어서, 이미지와 같이 순서나 구조가 중요한 데이터의 생성 방식을 다룹니다 (Figure 1b 참고).
- VQ-VAE 코드북 시퀀스: 결과물 vd는 VQ-VAE를 통해 얻어진 코드북들의 시퀀스와 VQ-VAE 디코더를 사용하여 생성된다고 가정합니다.
- Autoregressive Prior(AR prior) 사용: 코드북 시퀀스를 생성하기 위해 AR prior 을 사용합니다.

- NLL 기반 수렴: VQ-VAE 디코딩과 결합된 자동 회귀 사전은 Negative Log-Likelihood(NLL)를 최소화하는 방향으로 학습되어 일반적인 데이터 분포에 수렴하도록 합니다. 이는 생성된 데이터가 실제 데이터와 유사해지도록 만듭니다.
- Generative 알고리즘: 이러한 일반적인 생성 과정은 위의 Algorithm 1에 자세히 설명되어 있습니다.
Training TVQ-VAE
- ELBO (eq.(11))
- First term: KL-divergence
- Variational distribution (theta)와 Prior distribution (c) 사이의 KL divergence를 나타냅니다.
- KL divergence는 두 확률 분포의 차이를 측정하며 항상 0보다 크거나 같습니다. 이는 모델의 사후 분포가 사전 분포에서 크게 벗어나지 않도록 하는 정규화(regularization) 역할을 합니다.
- Second term: Reconstruction error
- Variational distribution 에서 데이터 p(theta) 와 q(theta|gamma))의 Log-likelihood 에 대한 기댓값입니다.
- 이 항은 모델이 주어진 잠재 변수가 실제 데이터를 얼마나 잘 설명하는지를 나타냅니다. 이 항을 최대화하는 것은 모델이 데이터를 잘 재구성하도록 학습시키는 효과가 있습니다.
- First term: KL-divergence
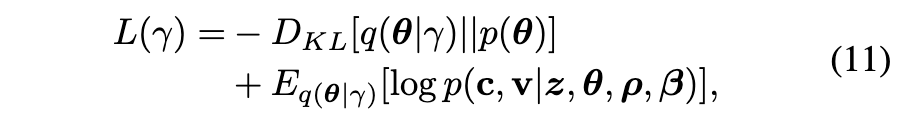
- Overall loss function (eq.(13))
- ELBO를 최대화하는 것은 그값의 음수를 최소화하는 것으로 등가이며, 이 식은 각 항에 대응하는 손실을 더한 형태입니다.
- First term: KL divergence 항에 해당하는 손실입니다. 식 (11)의 첫 번째 항에 대응하며, theta 가 됩니다. 이 값을 최소화하여 변분 분포와 사전 분포의 차이를 줄입니다.
- Second term: 코드북 c 의 재구성 손실입니다. 식 (12)에서 first term 에 해당하는 부분의 손실입니다.
- Third term: 출력 샘플 v 의 재구성 손실입니다. 식 (12)에서 second term 에 해당하는 부분의 손실입니다.

Training Implementation

- TVQ-VAE Training
- TVQ-VAE 모델의 전체 손실함수는 세 가지 구성 요소의 합 (KL-divergence (regularization), 코드북 재구성 loss, 출력샘플의 재구성 loss) 으로 정의됩니다.
- 코드북 재구성 loss: 이는 입력 데이터로부터 추출된 코드북 정보를 잘 보존하도록 학습하는 역할을 합니다. 이 항 또한 고전적인 토픽 모델의 ELBO 와 유사하며, ProdLDA 설정을 따릅니다.
- 출력샘플의 재구성 loss: 이 항은 TVQ-VAE의 핵심적인 특징 중 하나로, 문서 분석 시의 단어 집합(set-of-word) 스타일 출력 또는 이미지 생성 시의 자기회귀(autoregressive) 방식 출력 등 다양한 형태의 출력을 지원합니다.
- 단어 집합 스타일 출력의 경우, 손실은 Equation (9)에서 정의된 생성 분포를 사용하여 계산되며, 이는 c 와 유사한 형태입니다.
자기회귀 생성의 경우, 손실은 Equation (10)에서 정의된 분포를 따르며, PixelCNN 또는 Transformer와 같은 autoregressive 모델의 Negative Log-Likelihood (NLL) 최소화와 동일합니다.
Related Works
Topic models with Embedding.
- PCAE [3]: 이 연구 FET-LM 또한 VAE(Variational Autoencoder)를 사용하여 결과물의 유연한 생성을 제안했습니다. 이는 본 논문에서 VQ 임베딩을 활용하는 아이디어와 유사한 맥락을 가집니다.
- 워드 임베딩(Word Embeddings) 활용: GloVe 와 같은 워드 임베딩을 활용한 토픽 모델링 연구들이 있었습니다. 이러한 연구들은 생성(generative) 방식과 비생성(non-generative) 방식 모두에서 토픽 모델링 성능 향상을 보여주었습니다.
- 사전 학습 언어 모델(PLMs) 활용: BERT 와 같은 PLM을 활용하는 것이 토픽 마이닝의 새로운 트렌드가 되었습니다. 많은 연구들이 K-means 클러스터와 토픽 임베딩 간의 관계를 활용하여 모델 성능을 개선했습니다. 보통 clustering approach 는 주제를 추출하기 위해 TF-IDF 와 같은 기법을 이용한 후처리 방법을 이용합니다.
- TVQ-VAE의 차별점: 본 논문의 TVQ-VAE는 이러한 기존 연구들과 달리, VQ-VAE를 통해 이산화된(discretized) PLM 정보를 후처리 과정 없이 생성적인 방식 (generative approach) 으로 처리하는 가능성을 보여줍니다.
Vector Quantized Latent Embedding.
- VQ-VAE의 이산화 기법
- VQ-VAE는 기존의 VAE(Variational Auto-Encoder)가 입력을 연속적인(continuous) 잠재 공간(latent space)에 매핑하는 것과 달리, 잠재 공간을 이산적인(discrete) 공간으로 구성합니다.
- 이는 "코드북(codebook)"이라는 미리 정의된 유한한 개수의 벡터 집합을 사용함으로써 가능합니다. 입력 이미지를 인코더를 통해 얻은 잠재 벡터를 코드북 내에서 가장 가까운 벡터(VQ 임베딩)로 "양자화(quantization)"하는 방식입니다.
- 이 기법은 [1] 논문에서 제안되었습니다.
- Generative model, 특히 image 생성에 미치는 영향
- 연속적인 고차원 데이터를 직접 모델링하는 것은 어렵습니다. VQ-VAE의 이산화는 이미지를 코드북에 있는 이산적인 "코드(code)" 또는 "토큰(token)"의 시퀀스로 표현할 수 있게 합니다.
- 이렇게 이산화된 표현은 마치 텍스트처럼 다룰 수 있게 되며, autoregressive 모델을 사용하여 시퀀스를 생성하고, 이를 다시 디코더를 통해 이미지로 복원하는 방식의 고품질 생성 모델 개발에 중요한 역할을 했습니다 [4].
- 이는 시각 데이터의 복잡성을 효과적으로 다루면서도 디테일한 생성을 가능하게 했습니다.
- 본 논문 (TVQ-VAE 프레임워크) 의 기여
- TVQ-VAE는 이러한 VQ-VAE의 이산화 기법을 토픽 모델링에 접목합니다.
- 특히, 시각 정보를 담고 있는 VQ 임베딩 자체에서 토픽의 맥락(topic context)을 추출해낼 수 있음을 보여줍니다.
- 더 나아가, 추출된 토픽 정보를 바탕으로 이미지를 비롯한 다양한 형태의 샘플을 동시에 생성할 수 있음을 실험적으로 입증합니다. 이는 기존의 토픽 모델링이 주로 텍스트 데이터에 집중하고 BoW(Bag-of-Words) 형태의 결과물에 제한되었던 것에서 확장된 부분입니다.
Empirical Analysis
Document Analysis
Topic Quality Evaluation.
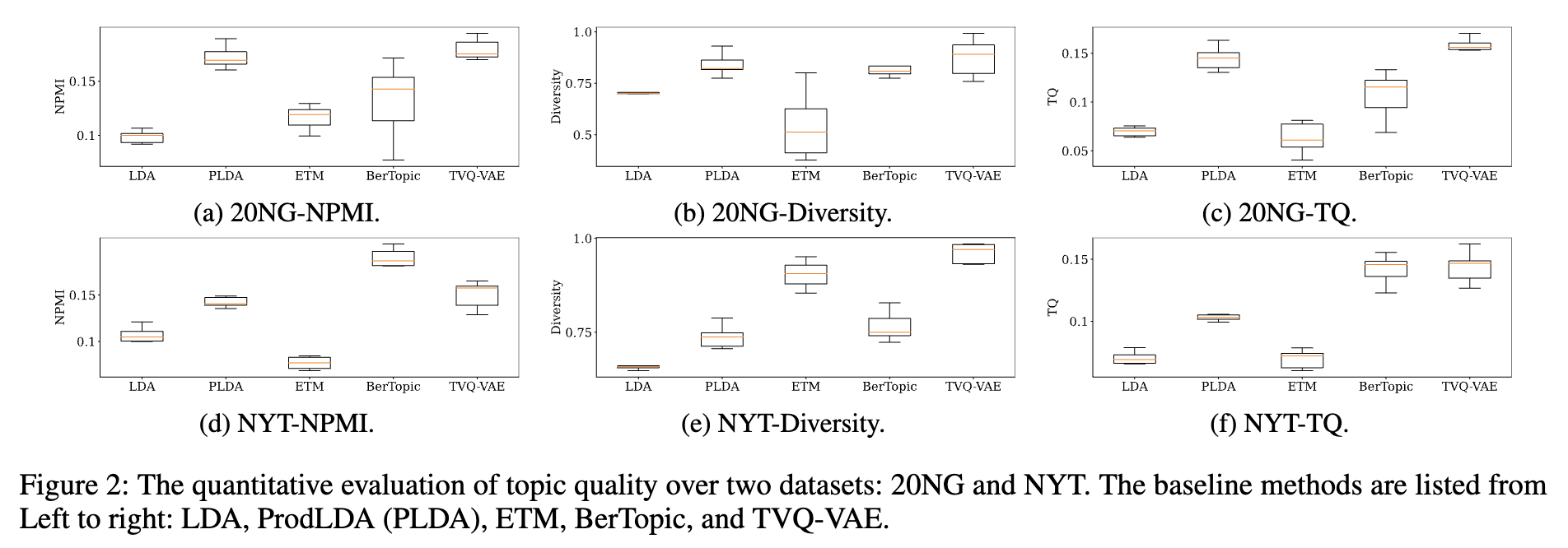
- 20NG 데이터셋에서의 성능
- TVQ-VAE는 다른 기준 모델들과 비교했을 때 유사하거나 더 우수한 TQ 성능을 보였습니다.
- 20NG 데이터셋은 어휘 크기(vocabulary size)가 1.6K로 상대적으로 작습니다.
- TVQ-VAE는 제한된 규모의 문서에서도 효과적으로 토픽 정보를 추출할 수 있음을 보여줍니다.
- 이 데이터셋에서는 ProdLDA와 같은 BoW(Bag-of-Words) 기반 모델들도 좋은 성능을 보였습니다.
- NYT 데이터셋에서의 성능
- NYT 데이터셋은 20NG보다 어휘 크기가 훨씬 크며, TVQ-VAE는 원본 어휘 크기의 1% 미만인 300개의 가상 코드북만 사용했음에도 불구하고 경쟁력 있는 토픽 품질을 달성했습니다.
- 기준 모델 중 BerTopic은 특히 NPMI 측면에서 뛰어난 성능을 보이며 눈에 띄었습니다. 이는 BerTopic이 대규모 어휘에 대해 확장성이 우수하다는 주장을 뒷받침합니다.
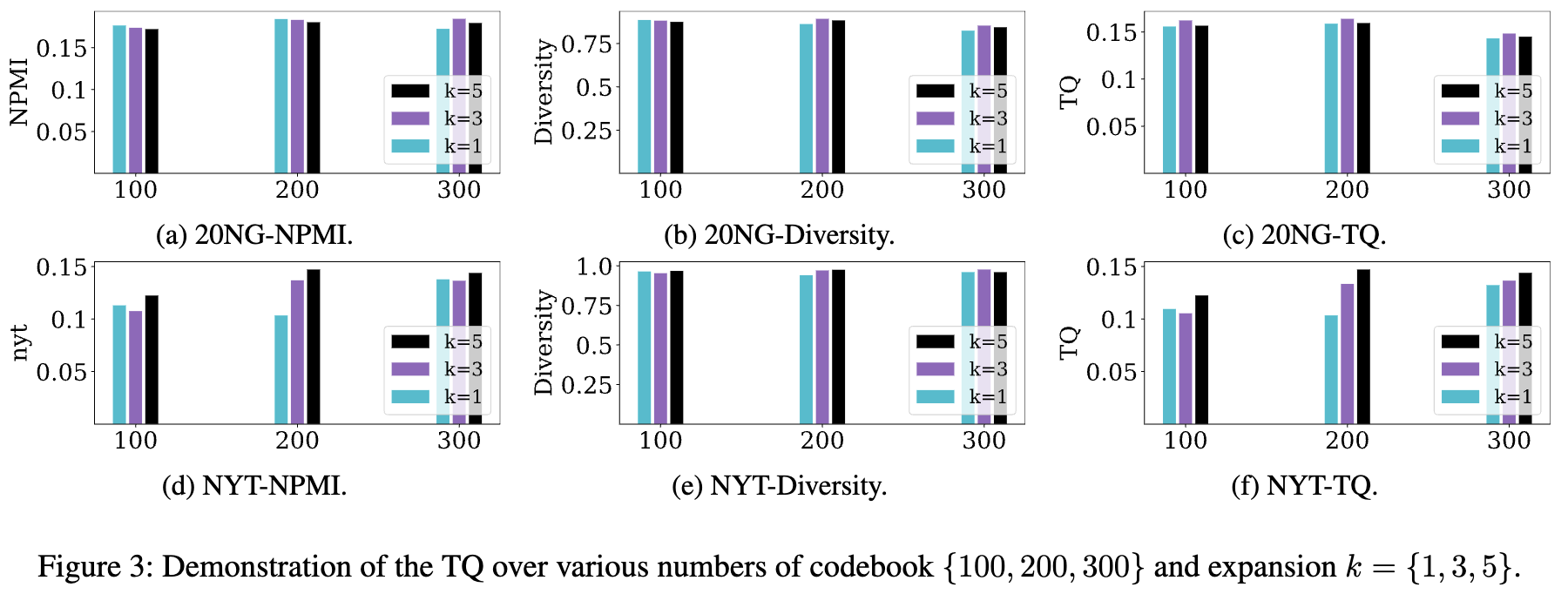
- Ablation Study 결과 (Figure 3)
- 코드북 수(100, 200, 300)와 확장 값 k(1, 3, 5)를 변화시키며 성능을 분석했습니다.
- 20NG 데이터셋에서는 코드북 수나 확장 값의 변화에 따른 성능 차이가 미미했습니다. 이는 작은 어휘 크기 때문에 임베딩 및 확장 수의 선택이 성능 향상을 반드시 보장하지 않으며, 특정 임계값을 넘어서면 추가 정보 캡처가 제한될 수 있음을 시사합니다.
- NYT 데이터셋에서는 어휘 크기가 훨씬 크기 때문에 더 많은 코드북 수와 확장 값에서 성능이 향상되는 결과를 보였습니다. 이는 데이터셋의 규모에 따라 모델 구성 요소의 영향이 달라짐을 보여줍니다.
Document Representation Evaluation.

- Km-NMI, Km-Purity: 이 두 지표는 문서 표현의 품질을 측정합니다. 논문에서 제안하는 토픽 모델이 각 문서를 얼마나 잘 표현하는지를 평가하기 위해, 모델이 추출한 문서별 토픽 분포 (theta) 를 K-means 클러스터링으로 묶은 후, 이 클러스터가 실제 문서의 레이블(클래스)과 얼마나 잘 일치하는지를 측정합니다.
- 20NG 데이터셋 결과
- 어휘 집합 크기가 비교적 작은 20NG 데이터셋에서는 기존의 BoW 기반 모델(LDA, ProdLDA)과 임베딩 기반 모델인 ETM, 그리고 Word2Vec 임베딩을 사용한 TVQ-VAE(W)가 더 높은 NMI 점수를 보였습니다.
- 이는 작은 어휘 집합에서는 전통적인 BoW 방식이나 Word2Vec과 같은 단어 임베딩이 효과적인 문서 표현을 학습할 수 있음을 시사합니다. 특히 Word2Vec 기반 TVQ-VAE는 PLM 기반 TVQ-VAE보다 우수한 성능을 보였습니다.
- NYT 데이터셋 결과
- 어휘 집합 크기가 훨씬 큰 NYT 데이터셋에서는 PLM(Pre-trained Language Model) 기반 모델들인 BerTopic, TopClus, 그리고 TVQ-VAE가 더 높은 성능을 기록했습니다.
- 이는 대규모 어휘 집합 환경에서 PLM이 제공하는 풍부한 사전 학습 정보가 문서 표현 학습에 더 유리함을 보여줍니다. 본 논문의 TVQ-VAE 모델은 어휘 집합 크기가 커질수록 문서 표현 능력이 강건해짐을 확인했습니다.
- PLM versus Word2Vec: TVQ-VAE 모델에 Word2Vec과 PLM 임베딩을 각각 적용했을 때의 결과는 데이터셋의 크기와 어휘 집합 규모에 따라 달라졌습니다. 20NG처럼 작은 데이터셋에서는 Word2Vec 기반 TVQ-VAE가 더 잘 작동했지만, NYT처럼 큰 데이터셋에서는 PLM 기반 TVQ-VAE가 더 좋은 성능을 보였습니다.
- 저자들은 이러한 결과가 20NG 데이터셋의 상대적으로 적은 단어 수와 어휘 집합 크기 때문일 수 있다고 설명합니다. PLM은 광범위한 어휘 범위를 커버하지만, 작은 데이터셋에서는 이러한 폭넓은 커버리지가 깊이 있는 정보 추출로 이어지지 않을 수 있습니다.
- 단어집합 크기에 따른 토픽모델들의 성능분석
- PLM 기반 모델 -> 큰 규모의 데이터셋에서 유리, W2V 기반 모델 -> 작은 규모의 데이터셋에서 유리
- PLM이 넓은 어휘 범위(breadth)를 가지고 있지만, 제약된 데이터셋에서는 깊이(depth)가 부족할 수 있습니다. 즉, 작은 데이터셋에서는 모델의 넓은 어휘 범위가 문서 클러스터를 구성할 때 높은 순도(purity)는 유지하지만, 다루는 토픽이나 단어의 범위(breadth)가 제한될 수 있습니다.
- 결과적으로 이는 Km-NMI(K-means Normalized Mutual Information) 점수를 낮추게 됩니다. TopClus 모델 (PLM 기반 모델)의 결과 또한 이러한 데이터셋 크기가 모델 성능에 미치는 영향을 뒷받침합니다.
Image Generation
Quantitative Evaluation.
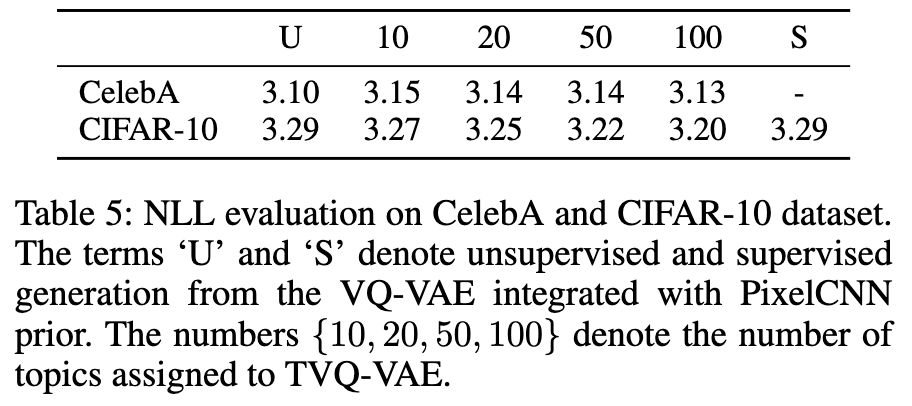
- 본 연구에서 저자들의 가설: 토픽모델로부터 theta와 beta를 추출하는 과정이 데이터셋의 숨겨진 구조를 포착하는 데 도움을 주어, 샘플 생성 과정을 용이하게 하고 결과적으로 더 낮은 NLL 값을 얻을 수 있다는 가설을 제시합니다. 이는 생성 모듈의 본래 역할과 유사합니다.
- CelebA 데이터셋: 이 데이터셋은 전처리(center-cropping 등)를 통해 얼굴 영역이 정렬되어 있어 상대적으로 복잡성이 낮습니다. CelebA에서는 토픽 정보를 사용하지 않은 비지도(Unsupervised, U) 베이스라인 모델(NLL 3.10)이 토픽 개수를 변화시킨 TVQ-VAE 모델(NLL 3.13 ~ 3.15)보다 더 낮은 NLL을 보였습니다. 즉, 이 데이터셋에서는 토픽 변수 추출이 NLL 개선에 큰 영향을 미치지 않았습니다.
- CIFAR-10 데이터셋: 이 데이터셋은 정렬되지 않은 10가지 객체 이미지로 구성되어 있어 CelebA보다 복잡성이 높습니다. CIFAR-10에서는 비지도(U) 베이스라인(NLL 3.29) 및 클래스 레이블을 사용한 지도(Supervised, S) 베이스라인(NLL 3.29)보다 TVQ-VAE 모델이 더 나은 성능을 보였습니다. 특히, 토픽 개수가 증가할수록 NLL 값이 선형적으로 감소하는 경향(10개 토픽: 3.27, 20개: 3.25, 50개: 3.22, 100개: 3.20)을 보였으며, 토픽 개수가 50개 또는 100개일 때 베이스라인보다 낮은 NLL을 달성했습니다.
- 데이터셋 복잡성과 결과 분석: 연구진은 이러한 상반된 결과가 두 데이터셋의 복잡성 차이에서 비롯된다고 분석합니다. CIFAR-10처럼 복잡한 데이터셋에서는 토픽 변수 추출이 데이터의 구조를 효과적으로 포착하여 생성 능력을 향상시키는 데 기여하지만, CelebA처럼 이미 구조가 단순화된 데이터셋에서는 그 효과가 두드러지지 않을 수 있습니다.
Qualitative Evaluation.

- 토픽 시각화 (Topic Visualization)
- 방법: Figure 4a (CelebA)와 4b (CIFAR-10)에 제시된 8x8 격자 이미지는 각 토픽에 해당하는 생성된 이미지 샘플을 보여줍니다.
- 과정: 토픽 시각화는 theta 값을 특정 토픽 인덱스에 해당하는 원-핫 벡터(one-hot vector)로 고정하여 수행됩니다. 그런 다음, PixelCNN 사전(prior) 를 사용하여 해당 토픽 벡터에 맞춰 코드북 시퀀스를 자동 회귀 방식(auto-regressive scheme)으로 생성합니다.
- 실험결과: 각 토픽이 색상, 모양, 대비 등과 같은 뚜렷한 특징을 나타내는 이미지를 생성함을 보여줍니다. 이는 모델이 토픽 정보를 효과적으로 학습하고 있음을 시사합니다.
- 참조 기반 생성 (Reference-based Generation)
- 방법: Figure 4c (CelebA)와 4d (CIFAR-10)는 좌측 상단의 참조 이미지(reference image)와 해당 이미지의 토픽 분포(theta) 를 활용하여 생성된 이미지들을 보여줍니다.
- 과정: 먼저 입력 이미지로부터 토픽 분포를 추출합니다. 이 추출된 theta_d 를 사용하여 새로운 이미지를 생성합니다.
- 목표: 새로 생성된 이미지가 원본 참조 이미지와 유사한 의미론적 특징을 공유하는지를 확인합니다. 이는 모델이 이미지의 특징을 토픽으로 잘 포착하고, 이를 바탕으로 유사한 이미지를 생성할 수 있음을 입증합니다.
- 실험결과: CIFAR-10 및 CelebA 데이터셋 모두에서 TVQ-VAE (P)가 참조 이미지의 특징을 효과적으로 포착하여 의미론적으로 유사한 샘플을 생성함을 보여줍니다.
- Qualitative analysis: TVQ-VAE (P) 모델이 VQ 임베딩을 활용하여 문서(이미지)에서 토픽을 성공적으로 추출하고, 추출된 토픽 정보를 사용하여 해당 토픽이나 참조 이미지와 의미론적으로 유사한 이미지를 유연하게 생성할 수 있음을 시각적으로 보여줍니다.

- Figure 5의 qaulitative analysis: Figure 5는 TVQ-VAE 모델 중 Transformer를 사용한 버전(TVQ-VAE (T))으로 생성된 이미지 샘플을 보여줍니다. 이 이미지들은 FacesHQ 데이터셋을 기반으로 학습되었으며, Figure 4에서 보여준 예시처럼 'reference-based generation' 형식으로 제시됩니다.
- 고해상도 생성: Figure 5의 이미지들은 256의 더 높은 해상도로 생성되었음을 명시합니다. 이는 모델이 고품질의 이미지를 생성할 수 있음을 시사합니다.
- Reference-based generation
- 'reference-based generation'이란 특정 원본 이미지(참조 이미지)의 특징을 기반으로 새로운 이미지를 생성하는 방식을 의미합니다.
- Figure 4와 Figure 5 모두 참조 이미지에서 추출된 'topic embedding'이 원본 이미지와 의미론적으로 유사한 이미지를 생성하는 데 핵심적인 역할을 함을 보여줍니다.
- 다양한 AR 모델 적용 가능성: 이 논문에서 제안하는 TVQ-VAE 방법론은 PixelCNN (P)과 Transformer (T)라는 두 가지 다른 자기회귀(AR) 모델에 효과적으로 적용될 수 있음을 강조합니다. 이는 TVQ-VAE 프레임워크의 유연성과 일반화 가능성을 보여줍니다.
Visualization of Embedding Space.
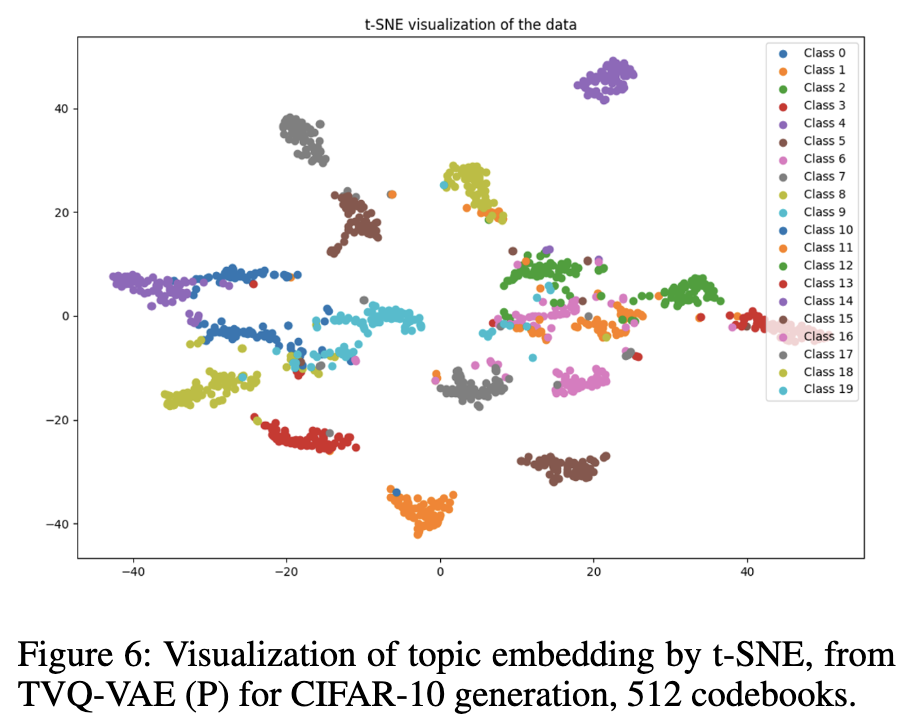
- Topic embedding space: 이 논문에서는 TVQ-VAE 모델이 추출한 이미지의 '토픽 임베딩'(θ)을 의미합니다. 이 임베딩은 이미지의 주요 의미적 내용을 함축하고 있습니다.
- 시각화된 데이터 포인트: t-SNE 플롯 상의 각 점은 동일한 참조 이미지에서 생성된 이미지의 토픽 임베딩을 나타냅니다. 즉, 원본 이미지를 기반으로 추출된 토픽 정보를 사용하여 생성된 여러 이미지들의 토픽 임베딩을 한 곳에 모아 시각화한 것입니다.
- 임베딩 시각화 결과: Figure 6를 보면, 동일한 참조 이미지에서 생성된 이미지들의 토픽 임베딩이 별개의 군집(distinct clusters) 을 형성하고 있음을 알 수 있습니다. 이는 TVQ-VAE가 참조 이미지의 의미적 특징을 효과적으로 포착하여, 그 특징을 기반으로 의미적으로 유사한 이미지를 생성할 수 있음을 시각적으로 보여줍니다. 토픽 임베딩이 생성된 이미지들의 의미적 유사성을 잘 반영하고 있기 때문에 같은 참조 이미지에서 나온 이미지들은 임베딩 공간에서도 가깝게 모여 군집을 이루게 됩니다.
Conclusion and Future Remark
- TVQ-VAE는 VQ-VAE의 이산적인 임베딩과 코드북을 활용하고, PLM(사전 학습 언어 모델)과 같은 사전 학습 정보를 통합합니다.
- 제한된 수의 이산적 임베딩을 통해 토픽 정보를 효과적으로 추출할 수 있음을 실험적으로 입증했습니다.
- BoW(Bag-of-Words) 스타일부터 AR 방식으로 생성된 이미지에 이르기까지 다양한 형태의 확률론적 문서 생성이 가능합니다.
- 기존의 최신 토픽 모델들과 비교했을 때 유사하거나 더 나은 성능을 달성했으며, 일반화된 토픽 기반 생성의 잠재력을 보여주었습니다.
- Future work: 이 접근 방식을 최근의 멀티모달 생성 분야로 확장하는 것을 제안합니다.
Reference
[1] Neural Discrete Representation Learning (Neurips 2017)
[2] Zero-Shot Text-to-Image Generation. 2021
[3] FET-LM: Flow-Enhanced Variational Autoencoder for Topic-Guided Language Modeling. 2023
[4] Generating Diverse High-Fidelity Images with VQ-VAE-2. 2019