[Paper Review] vONTSS: vMF based semi-supervised neural topic modelingwith optimal transport (ACL 2023)

vONTSS: vMF based semi-supervised neural topic modeling with optimal transport
(Findings of ACL 2023)
Weijie Xu, Xiaoyu Jiang, Srinivasan H. Sengamedu, Francis Iannacci, Jinjin Zhao
Abstract
- 기존 NTMs 의 한계: 최근 VAE에서 영감을 받은 다양한 NTM 들이 많은 연구 관심을 받고 있지만, 사람의 지식(human knowledge)을 통합하기 어렵다는 문제 때문에 실제 세계에서의 응용에 제약이 있습니다.
- vONTSS 소개: 이러한 한계를 극복하기 위해 vONTSS라는 반지도 학습 신경망 토픽 모델링 방법론을 제안합니다. vONTSS는 vMF 분포 기반 VAE 와 최적 수송 기법 (Optimal transport) 을 사용합니다.
- Semi-supervised learning 설정에서의 작동 방식: 토픽당 몇 개의 키워드가 주어졌을 때, vONTSS는 잠재적인 토픽을 생성하고 토픽-키워드 품질 및 토픽 분류(topic classification) 를 최적화합니다.
- vONTSS의 주요 성과
- 반지도 학습 설정: 기존의 반지도 학습 토픽 모델링 방법론보다 분류 정확도(classification accuracy) 와 다양성(diversity) 측면에서 우수한 성능을 보였습니다.
- 비지도 학습 설정 지원 (vONT): vONTSS는 비지도 학습 방식의 토픽 모델링도 지원합니다.
- 비지도 학습 설정에서: 정량적/정성적 실험 결과에 따르면, 벤치마크 데이터셋에서 기존 최신 NTM들보다 높게 클러스터링되고 일관성 있는(highly clustered and coherent) 토픽을 발견했습니다.
- 효율성: 최신 약지도 학습(weakly supervised) 텍스트 분류 방법론과 유사한 분류 성능을 달성하면서도 훨씬 빠릅니다.
- 이론적 기여: 최적 수송 손실(optimal transport loss)과 교차 엔트로피 손실(cross-entropy loss)이 전역 최소값(global minimum)에서 동일하다는 것을 추가로 증명했습니다. (Lemma 3.1, Theorem 3.2 in Appendix B)
1 Introduction
- Semi-Supervised Topic Modeling: 준지도 토픽 모델링은 사용자가 각 토픽에 포함시키고 싶은 소수의 키워드를 입력으로 받아 토픽을 생성하는 방법입니다. 이를 통해 사용자는 자신의 도메인 지식이나 특정 요구사항을 토픽 모델링 결과에 반영할 수 있습니다.
- 기존 준지도 토픽 모델링 방법의 한계: 전통적인 방법들은 텍스트 데이터의 의미론적 정보를 효과적으로 활용하지 못하는 경향이 있습니다. 이로 인해 토픽 분류 정확도가 낮고 결과의 분산(variance)이 높은 문제가 있었습니다.
- 제안하는 vONTSS 프레임워크: 이 논문에서는 von Mises-Fisher (vMF) 분포와 최적 수송(optimal transport)을 활용한 준지도 신경망 토픽 모델링 방법인 vONTSS를 제안합니다.
- vONTSS는 인코더-디코더 프레임워크를 기반으로 합니다.
- 인코더(Encoder): 잠재 분포(latent distributions)를 모델링하기 위해 수정된 vMF (von Mises-Fisher) 사전 분포 (Prior distribution) 를 사용합니다.
- 디코더(Decoder): 구형 임베딩(spherical embeddings) 기반의 단어-토픽 유사성 행렬을 사용하여 토픽을 생성합니다.
- 최적 수송(Optimal Transport): 이 메커니즘을 사용하여 모델을 준지도 설정으로 확장하고, 제공된 키워드와 생성된 토픽 간의 매칭을 개선합니다. 본 논문에서는 unsupervised / semi-supervised setting 에서 각각 vONT, vONTSS 를 제안하는데 optimal transport 는 vONTSS (즉, semi-supervised) 에서만 사용합니다.
- Main Contributions
- vMF 분포의 temperature 및 학습 가능한 (Learnable) κ 도입: 이 논문에서는 vMF 분포에 'temperature'라는 개념을 도입하고, vMF 분포의 밀집도(concentration)를 나타내는 매개변수 κ 를 고정값이 아닌 학습 가능한 값으로 만들었습니다. 이는 vMF 분포의 표현력을 향상시키고, latent space 상에서 데이터 포인트들이 더 응집되고(clustered) 응집성(coherence)을 가지도록 유도합니다.
- vONT (unsupervised 버전)의 우수성: vONTSS의 unsupervised 버전인 vONT는 벤치마크 데이터셋에서 최신 NTM 방법들과 비교했을 때 가장 우수한 응집성(coherence)과 클러스터 가능성(clusterability)을 보입니다. 이는 unsupervised 환경에서도 vONT가 문서 내 잠재된 주제 구조를 효과적으로 포착함을 의미합니다.
- Human evaluation: intrusion 및 rating task 에 대한 인간 평가를 수행한 결과, vONT는 다른 기법들에 비해 더 나은 성능을 보였습니다. 이는 vONT가 생성한 토픽이 인간이 이해하기에 더 자연스럽고 의미론적으로 일관성이 있음을 시사합니다.
- semi-supervised 설정에 OT 활용: optimal transport (OT) 기법을 사용하여 모델을 semi-supervised 설정으로 확장했습니다. 이를 통해 모델의 안정성을 높이고, 키워드 세트와 학습된 토픽 간의 좋은 정렬을 달성했습니다. 또한, 이 과정에서 이론적인 속성들도 증명했습니다.
- vONTSS의 분류 성능 및 안정성: semi-supervised 시나리오에서 vONTSS는 다른 semi-supervised 토픽 모델링 방법들과 비교했을 때 가장 우수한 분류 정확도(classification accuracy)와 낮은 분산(variance)을 보입니다. 이는 vONTSS가 더 안정적으로 예측을 수행하며, 실제 응용에서 유용함을 나타냅니다.
- Weakly supervised text classification 방법과의 효율성 비교: vONTSS는 최신 약 지도 텍스트 분류 방법과 비슷한 분류 성능을 달성하면서도 훨씬 더 효율적입니다. 이는 vONTSS가 레이블링된 데이터가 적은 상황에서도 빠르고 효과적으로 작동할 수 있음을 의미합니다.
2 Related Methods and Challenges
NTM
- NTM은 VAE(Variational Autoencoder)에서 영감을 받은 neural network 기반의 토픽 모델링 방법입니다.
- 목표: 문서 집합(list of documents)을 입력으로 받아 잠재적인 구조를 발견하고, 정의된 개수의 토픽을 생성하며, 각 토픽에 대한 키워드 및 관련 문서를 산출합니다.
- VAE 에서 사전 분포 (prior distribution) p(Z) 선택: NTM은 일반적으로 Gaussian [1], Gamma [2], Dirichlet [3] 분포를 사용하여 p(Z)를 근사합니다.
- 실제 적용의 문제점
- 단어 간의 의미론적 관계(semantic relationship)를 잘 포착하지 못합니다. 생성된 토픽이 인간의 해석과 잘 일치하지 않습니다.
- 특히 Gaussian 사전 분포를 사용할 경우, 잠재 공간이 중앙으로 쏠리거나 문서 클래스 간에 표현이 얽히는 문제(tangled representations)가 발생할 수 있습니다. 이는 저차원에서는 Gaussian 밀도가 원점 주변에 집중되는 경향이 있기 때문입니다.
- 기존 NTM 의 semi-supervised 버전으로 확장의 어려움
- 손실 함수의 목표 충돌: VAE 기반의 NTM 의 objective function 은 다음과 같이 구성됩니다.
- 재구성 손실 (Reconstruction Loss) 이 부분은 모델이 원본 문서(X)를 잘 재구성하도록 학습시킵니다. 이는 잠재 공간(latent space)이 문서의 정보를 최대한 잘 표현(representative)하도록 만듭니다.
- KL 발산 (KL Divergence): 이 부분은 학습된 잠재 분포가 사전 분포(prior distribution) p(Z)와 유사해지도록 합니다.
- 준지도학습 버전으로의 확장: Semi-supervised 설정에서 사용되는 Cross-entropy 손실은 주어진 키워드 세트와 할당된 토픽이 잘 정렬되도록 모델을 유도합니다. 하지만 NTM의 재구성 손실은 잠재 공간을 문서 정보를 잘 담도록 만드는 데 집중하므로, 이는 키워드와 토픽을 정렬하려는 Cross-entropy 손실의 목표와 상충될 수 있습니다.
- 모델의 불안정성 또는 추가적인 조정 필요: 이러한 손실 함수 간의 목표 불일치 때문에 기존의 semi-supervised NTM 방법들은 학습이 불안정해지거나, 특정 데이터셋이나 설정에 맞춰 추가적인 조정(adaptions)이 필요하게 됩니다.
- 손실 함수의 목표 충돌: VAE 기반의 NTM 의 objective function 은 다음과 같이 구성됩니다.
Embedding Topic Model (ETM)
- ETM(Embedding Topic Model): 사전 학습된 단어 임베딩 (e.g., GloVe) 을 활용하여 coherent 한 토픽을 생성하는 방법입니다. 기존의 BoW(Bag-of-Word) 표현 방식에서는 단어 간의 의미론적 관계를 파악하기 어렵다는 문제를 해결하기 위해 제안되었습니다. VAE(Variational Autoencoder) 구조를 따르며, VAE 에서 Decoder 는 어휘 임베딩 행렬 e_V과 토픽 임베딩 행렬 e_T 을 사용하여 토픽-단어 분포 (Topic-word distribution) 를 계산합니다.
- 기존의 ETM의 한계
- 토픽 다양성 부족 (Low-diversity): 여러 단어와 관련된 흔한 단어들의 임베딩이 소수의 토픽 임베딩과 높은 상관관계를 가질 수 있습니다. 이로 인해 생성되는 토픽들이 서로 비슷해지고 다양성이 떨어집니다.
- 도메인 특화 토픽 식별의 어려움: 사전 학습된 임베딩은 특정 도메인(예: COVID-19)과 관련된 신조어나 특정 용어를 포함하지 않을 수 있습니다. 따라서 이러한 용어가 포함된 도메인 특화 토픽을 제대로 식별하는 데 한계가 있습니다.
von Mises-Fisher
Research question: VAE 기반의 신경망 토픽 모델(Neural Topic Model, NTM)에서 문서의 latent distribution 를 모델링하는데 사용되는 분포 -> 즉, prior distribution 의 영향이 topic quality 에 어떤 영향을 끼칠까요? 과연 Gaussian distribution 이 best choice 일까요?
- Gaussian 분포의 문제점: 낮은 차원에서 Gaussian 분포의 밀도는 원점 주변에 집중되는 경향이 있습니다. 데이터가 여러 클러스터로 나뉘어 있을 때, 이는 문제가 될 수 있습니다. 이상적인 사전 분포(prior)는 매개변수 공간 전체에 걸쳐 비정보적이고 균일해야 합니다.
- vMF 분포의 도입: 이러한 Gaussian 분포의 문제점을 해결하기 위해 VAE에서 vMF 분포를 사용합니다. vMF 분포는 M-1 차원 구(sphere) 상에 정의되는 분포입니다.
- vMF 분포의 매개변수
- mu: 방향 매개변수 (direction parameter)로, ||mu|| = 1 조건을 만족합니다. 분포의 평균 방향을 나타냅니다.
- κ: 집중 매개변수 (concentration parameter)로, 분포가 평균 방향 mu 주위에 얼마나 집중되어 있는지를 나타냅니다. κ=0 일 때는 구 상에서 균일 분포가 됩니다.
- vMF 분포의 장점
- VAEs에서 vMF 분포를 사용하면 특히 낮은 차원에서 데이터 포인트의 클러스터링 성능이 더 좋습니다 [4]
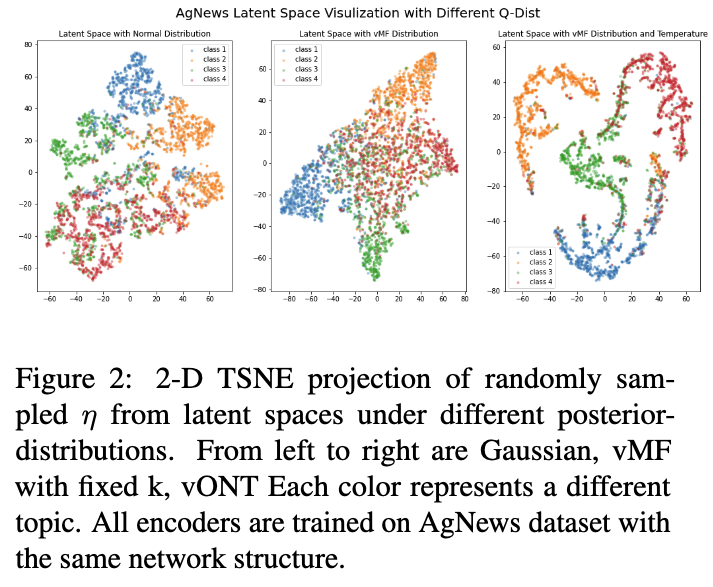
- 논문에서는 AgNews 데이터셋을 기반으로 시각화 결과 (Figure 2) 를 통해 Gaussian 분포에 비해 vMF 분포가 문서를 더 잘 분리된 클러스터로 밀어내는 경향이 있음을 보여줍니다.
- vMF 분포의 단점: vMF 분포는 샘플이 확률 벡터로 변환될 때 표현력이 제한적입니다. 단위 구 상의 제약 때문에, vMF 샘플에 softmax를 적용해도 특정 토픽에 대한 높은 확률 값을 얻기 어렵습니다. 예를 들어, 토픽 차원 M=10 일 때, 특정 토픽의 가장 높은 확률은 0.23에 불과할 수 있습니다.
- 이 논문 (vONTSS)은 이러한 vMF 분포의 단점, 특히 제한된 표현력을 개선하기 위해 'temperature' 개념을 도입하고 κ 값을 학습 가능하게 (Learnable) 만듭니다. 또한, 대부분의 기존 vMF 기반 토픽 모델이 VAE 기반이 아니어서 학습이 느린 문제를 해결하고 VAE 프레임워크를 사용합니다.
- 본 연구의 목표: [4] 는 VAE에서 vMF 분포를 사용하여 잠재 공간 클러스터링 개선을 제안했고 (토픽모델 연구는 아님, Only VAE), 이 논문(vONTSS)은 이를 NTM에 적용하고 semi-supervised 설정으로 확장하면서 vMF의 표현력 한계를 극복하기 위한 방법을 제시하고 있습니다.
3 Proposed Methods
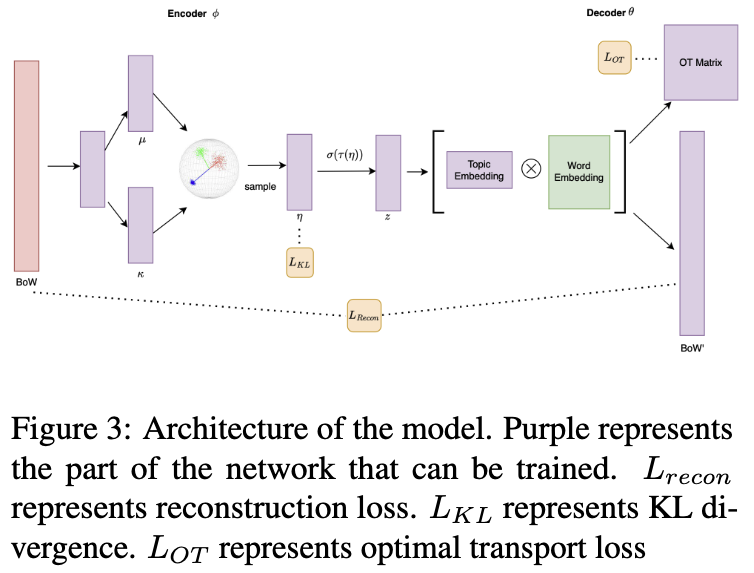
Proposed Framework
- 전체 개요: vONTSS는 문서를 입력받아 숨겨진 토픽 구조를 발견하고, 특히 소수의 키워드가 제공되는 반지도 학습 설정에서 효과적으로 작동합니다.
- 인코더 네트워크 (phi)
- 문서의 Bag-of-Words (BoW) 표현 X_d 을 입력으로 받습니다.
- vMF (von Mises-Fisher) 분포를 기반으로 하여 문서를 나타내는 잠재 벡터를 생성합니다.
- 이 잠재 벡터로부터 샘플을 생성합니다.
- 온도 함수 tau 및 Softmax
- 인코더에서 생성된 잠재 샘플에 온도 함수 tau 를 적용합니다.
- 그 결과에 Softmax를 적용하여 각 문서에 대한 확률적인 토픽 분포 z_d 를 얻습니다. 이는 해당 문서가 어떤 토픽에 속할 확률을 나타냅니다.
- 디코더 네트워크 (θ)
- 수정된 토픽-단어 행렬 \(E\)를 사용합니다. 이 행렬은 토픽과 단어 간의 연관성을 나타냅니다.
- 문서의 토픽 분포 z_d 와 토픽-단어 행렬 (topic-word matrix) E 를 사용하여 원래 문서의 BoW 표현 X_d 을 재구성 (reconstruction) 합니다.
- 반지도 학습 세팅으로 확장
- 반지도 학습 설정을 위해 Optimal Transport (키워드와 주제간 매칭) 를 활용합니다.
- 이는 제공된 키워드 세트와 모델이 생성한 토픽을 효과적으로 일치시키는 데 사용됩니다.
- 주요 개선점: 이 모델은 Gaussian 분포 사용 시 발생할 수 있는 잠재 공간의 얽힘 문제와 기존 vMF 분포의 표현력 한계를 극복하기 위해 두 가지 개선을 도입했습니다.
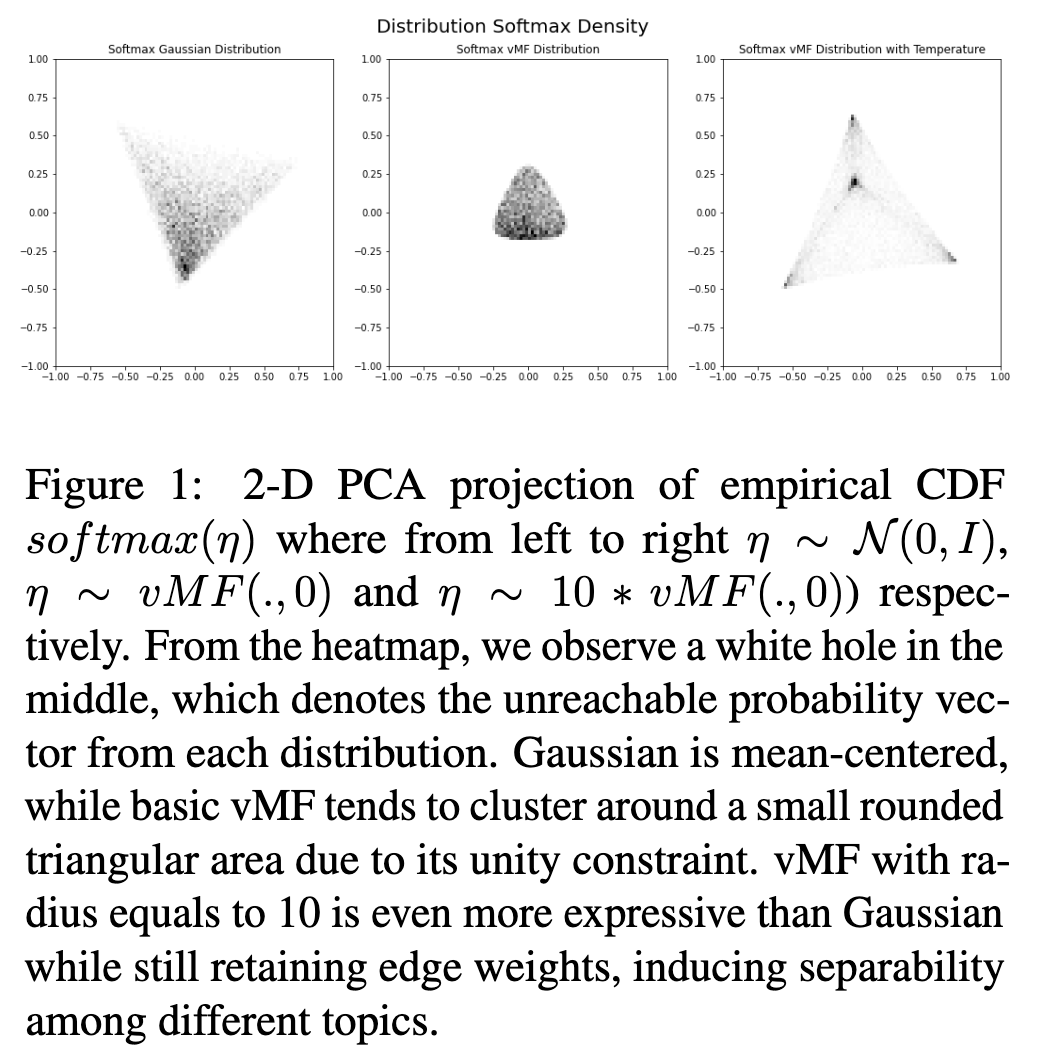
- 온도 함수 tau 도입: Softmax 이전에 온도 함수 tau 를 적용하여 vMF 분포의 '반지름'을 수정합니다. 이를 통해 토픽 간 분리성을 유도하면서 표현력을 향상시킵니다. (Figure 1)
- Learnable κ 설정: vMF 분포의 집중도 파라미터인 κ 를 학습 가능한 파라미터로 설정합니다. 이를 통해 훈련 중 특정 토픽에 대한 모델의 확신도를 유연하게 조절할 수 있으며, 더 잘 군집화된 결과를 얻는 데 기여합니다 (Figure 2 참조).
Encoder Network Temperature Function
- 기존 vMF 분포의 한계
- 표준 vMF 분포는 단위 구(unit sphere) 위에 정의되기 때문에, 생성되는 토픽 확률 분포(예: softmax를 거친 결과)가 특정 토픽에 대한 높은 확률 값을 갖기 어렵습니다.
- 예를 들어, [0.98, 0.01, 0.005, 0.0003, 0.0002]와 같이 특정 토픽에 확률이 집중된 벡터는 vMF 분포만으로는 표현하기 어렵습니다.
- 이는 분포가 단위 구 위에 "압축"되어 있기 때문에 발생하는 '단위 제약(unity constraint)' 때문입니다. 반면, 가우시안 분포(Gaussian posteriors)는 이러한 편향된 분포를 더 잘 표현할 수 있습니다.
- 제안된 해결책
- 이러한 vMF 분포의 표현성 문제를 완화하기 위해, 저자들은 softmax를 적용하기 이전에 vMF 분포에서 샘플링된 벡터의 '반지름(radius)'을 수정하는 '온도 함수(temperature function)'를 도입했습니다.
- 반지름 수정의 효과: Figure 1에서 볼 수 있듯이, 수정되지 않은 vMF 분포(중앙 그림)는 특정 영역에 집중되어 표현성이 제한적입니다. 반지름을 키우면(예: 10으로 설정, 오른쪽 그림), 네트워크가 토픽 확률이 특정 방향으로 더 '편향된(polarized)' 분포를 학습할 수 있게 됩니다. 이는 토픽 간 분리성을 높이는 데 기여합니다.
- Appendix N에 분석된 것처럼, 다양한 반지름 값을 통해 모델은 더 풍부하고 미묘한(nuanced) 잠재 표현 구조를 학습하게 되며, 이는 가우시안 분포보다 더 나은 결과를 가져옵니다 (Appendix I).
Learnable κ (학습가능한 파라미터)
- κ(kappa)를 학습 가능하게 변경
- 이 논문에서는 vMF 분포의 집중도 매개변수인 κ를 고정된 값이 아닌, 학습 과정에서 모델이 스스로 배우도록 변경했습니다.
- 이렇게 하면 모델이 특정 토픽에 대한 확신도(confidence)를 유연하게 학습할 수 있습니다.
- Clusterability(클러스터 가능성) 향상: κ를 학습 가능하게 함으로써 토픽의 Clusterability, 즉 문서들이 각 토픽별로 잘 분리되어 모이게 되는 능력을 더욱 향상시킬 수 있습니다.
- KL Divergence(KL 발산)의 영향 비교
- vMF vs. Gaussian: vMF 분포의 KL Divergence 항은 분포를 더 집중되게 만드는 경향이 있지만, 잠재 공간의 방향(direction) 자체에는 영향을 미치지 않습니다. 이는 결과적으로 데이터 포인트들이 더 클러스터링되도록 만듭니다.
- 반면, Gaussian 분포의 KL Divergence 항은 잠재 분포의 '편극화(polarization)'에 페널티를 부여합니다 (자세한 내용은 Appendix K 참조). 이는 Gaussian 분포가 덜 클러스터링되도록 합니다.
- 실험적 결과 (Figure 2)
- Figure 2는 AgNews Dataset 에서 인코딩된 문서의 잠재 분포를 시각화한 결과입니다.
- Gaussian 분포를 사용했을 때는 다른 토픽에 속하는 문서들이 중심 근처에서 뒤섞여 있어 토픽 분리가 어렵게 나타납니다.
- 반면, vMF 분포는 네 개의 문서 클래스를 서로 다른 사분면으로 밀어내어 Gaussian 분포에 비해 더 구조화되고 분리 가능한 클러스터를 형성함을 보여줍니다.
Decoder Network
- 디코더 구성: vONTSS의 디코더는 기존 ETM 의 구조를 따릅니다. ETM과 마찬가지로, 디코더는 단어 임베딩 행렬 e_V 과 토픽 임베딩 행렬 e_T 을 사용하여 토픽-단어 행렬 E 을 생성합니다. 이 행렬은 특정 토픽에서 단어가 나타날 확률을 나타냅니다.
- Spherical Embedding 사용
- vONTSS 디코더의 한 가지 주요 차이점은 단어 임베딩 e_V 을 데이터셋에서 직접 학습한 Spherical Embedding [5] 을 사용한다는 점입니다.
- Spherical Embedding [5] 은 구(sphere) 상에 단어를 표현하는 방식으로, 단어 유사도 평가와 문서 클러스터링에서 좋은 성능을 보입니다. Spherical Embedding 을 사용함으로써 토픽 모델링 방법의 클러스터능력 (clusterability)을 더욱 향상시킵니다.
- 단어 임베딩 고정
- 저자들은 토픽 모델링 학습 과정 동안 단어 임베딩을 고정했습니다. 여기에는 두 가지 이유가 있습니다.
- 희소성 문제 완화: 단어 임베딩을 고정하면 데이터 희소성 문제(sparsity issues)를 완화하는 데 도움이 될 수 있습니다.
- vMF 기반 VAE의 표현력 한계 보완: vMF 기반 VAE [4] 는 고차원에서 분산 자유도가 제한되어 표현력이 떨어지는 경향이 있습니다. 단어 임베딩을 고정함으로써 고차원 설정에서 토픽이 더 잘 분리되도록 하고 토픽 다양성(topic diversity)을 개선하는 데 기여할 수 있습니다.
Loss Function for vONTSS
- 손실 함수의 구성: vONTSS는 준지도 학습을 위해 M1 + M2 모델 프레임워크를 차용합니다. 전체 손실 함수 L(X, T)는 다음과 같이 근사됩니다.
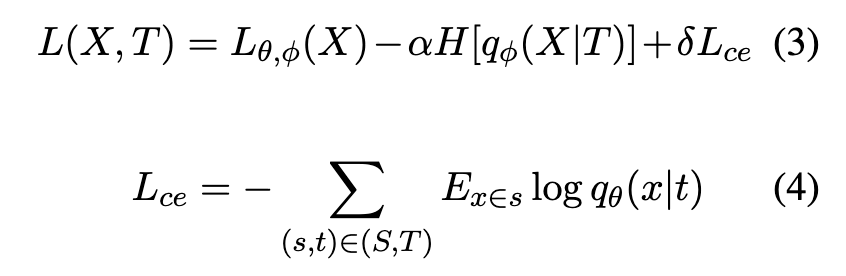
- Eq.(3): 이는 표준적인 신경망 토픽 모델(NTM)의 비지도 학습 손실 함수입니다. 문서를 복원하는 재구성 손실(reconstruction loss)과 잠재 공간 분포를 사전 분포(prior distribution)에 가깝게 만드는 KL 발산(KL divergence) 항으로 구성됩니다.
- H[qϕ(X|T)]: qϕ(X|T)의 엔트로피 항입니다. 본문에서는 이것을 정규화 항(regularization term)으로 간주할 수 있다고 설명합니다.
- Eq.(4): 준지도 학습을 위한 교차 엔트로피(cross-entropy) 손실 항으로, Semi-supervised setting 에서 필요한 손실함수 입니다.여기서 S는 키워드 집합들의 모음이고, T는 토픽들의 모음입니다. (s, t)는 토픽 t와 관련된 키워드 집합 s 쌍을 나타냅니다.
- Ex∈s log qθ(x|t)는 키워드 집합 s에 속한 각 키워드 x에 대해, 해당 키워드가 토픽 t에 속할 확률 qθ(x|t)의 로그 값의 기댓값(평균)을 계산한 것입니다. 이 항은 주어진 키워드 집합 s의 키워드들이 해당 레이블된 토픽 t와 높은 연관성을 가지도록 모델을 학습시킵니다. qθ(xj |ti) = Ei,j는 토픽 i와 단어 j 사이의 연관성을 나타내는 토픽-단어 행렬 E의 한 원소입니다.
α와 δ: 손실 함수의 각 항들의 중요도를 조절하는 매개변수(parameter)입니다. - 최적화의 어려움
- 위에서 정의된 손실 함수는 세 가지 목표(교차 엔트로피 최소화, KL 발산 최소화, 재구성 손실 최소화)를 동시에 최소화해야 하는데, 이 목표들이 서로 잘 정렬되지 않는다는 문제가 있습니다. 예를 들어, 특정 매개변수(반경 매개변수 등)를 학습 가능하게 만들면 재구성 손실은 감소하지만 분류 성능은 오히려 저하될 수 있습니다(Appendix D에서 설명).
- 학습 초기에 cross-entropy 손실을 바로 적용하면 토픽 임베딩(topic embeddings)이 주어진 키워드 임베딩(keyword embeddings)의 중심에 갇혀 모델이 과적합(overfitting)될 수 있습니다.
- 먼저 비지도 학습(unsupervised training)으로 vONT 모델을 학습시킨 후, 학습된 토픽과 키워드 집합을 매칭하는 방법을 찾아야 하는데, 단순히 코사인 유사도(cosine similarity) 등으로 매칭하면 다른 키워드들이 동일한 토픽에 매칭되는 등 성능이 불안정해질 수 있습니다.
- 최적화를 위한 해결책 -> 2단계 학습 과정: 이러한 어려움을 해결하기 위해 본 논문에서는 2단계 학습 과정을 제안합니다.
- 1단계: 먼저 비지도 학습 부분에 해당하는 손실함수 (즉, eq.(3) 에서 cross-entropy loss 부분 제외한 손실함수) 만을 최적화하여 모델을 수렴시킵니다. 이 단계에서는 키워드와 토픽 간의 명시적인 레이블링 정보를 사용하지 않습니다.
- 2단계: 1단계 학습이 끝난 후, 전체 손실 함수 L(X, T)를 사용하여 몇 epoch 동안 추가 학습(fine-tuning)을 진행합니다. 이 과정에서 토픽과 키워드 집합 간의 연관성을 학습하게 됩니다. 이 2단계 접근 방식은 모델을 더 쉽게 최적화하고, 학습 시간을 단축하며, Interactive topic modeling과 같은 시나리오에 적합하다고 설명합니다.
- 이후 섹션에서는 위의 최적화 과정의 2단계 중 토픽과 키워드 집합을 '매칭'하는 문제를 해결하기 위해 Optimal Transport를 도입합니다.
Optimal Transport for vONTSS
- Optimal Transport (OT): Optimal Transport는 확률 분포를 비교하는 데 널리 사용되는 방법입니다. 한 분포의 질량을 다른 분포로 이동시키는 데 필요한 최소 비용을 계산하는 것으로 이해할 수 있습니다. 이 논문에서는 토픽 분포와 키워드 세트 분포를 매칭하는 데 사용됩니다.
- 수송 계획 행렬 (P): 이 논문에서 Optimal Transport는 \(m \times n\) 행렬 P 를 사용합니다. 여기서 m 은 토픽의 개수이고 n 은 키워드 그룹의 개수입니다. P 의 각 항목 Pt,s는 토픽 t 와 키워드 그룹 s 사이의 '수송량' 또는 매칭 강도를 나타냅니다. P 는 행 합계와 열 합계가 특정 값(r, c)이 되도록 제약됩니다. 논문에서는 각 토픽과 각 키워드 그룹의 합이 1이 되도록 제약하여 일대일 매칭을 유도합니다.
- 비용 행렬 (C): OT의 핵심 요소는 비용 행렬 C 입니다. C 는 토픽 t 의 질량을 키워드 그룹 s 로 이동시키는 비용을 나타냅니다. 이 논문에서는 비용을 다음 eq.(7) 과 같이 정의합니다.
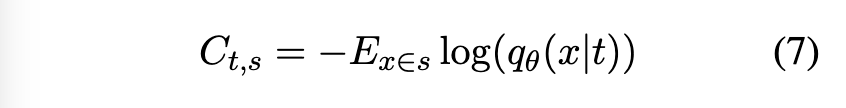
- 여기서 q(x|t) 는 토픽 t 에서 단어 x 가 나올 확률을 나타내며, 디코더 네트워크 theta 에 의해 결정됩니다.
- E 는 키워드 그룹 s 에 속하는 단어들에 대한 평균을 의미합니다. 즉, 토픽 t 가 키워드 그룹 s 에 속한 단어들을 잘 설명할수록 (로그 확률이 높아질수록) 비용은 낮아집니다.
- Optimal Transport 목적 함수: 논문에서 최소화하려는 Optimal Transport 손실함수는 다음 eq.(8) 와 같습니다.
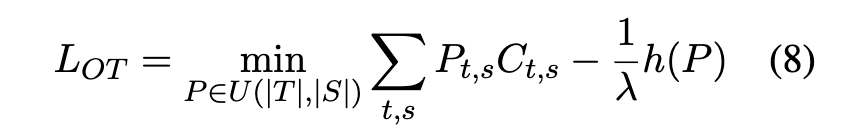
- 이는 토픽과 키워드 그룹 간의 총 매칭 비용을 나타냅니다. P 행렬에 따라 각 매칭 Pt,s 에 해당하는 비용 Ct,s 를 곱한 총합을 최소화하는 것을 목표로 합니다.
- h(P):이것은 수송 계획 행렬 P 의 엔트로피입니다. 엔트로피는 불확실성을 측정하며, P 가 고르거나 분산될수록 높아집니다.
- lambda 는 엔트로피 페널티의 강도를 조절하는 매개변수입니다. 이 항을 목적 함수에서 빼면, P 가 낮은 엔트로피를 가지도록 유도하여 토픽과 키워드 그룹 간의 명확한 일대일 매칭을 장려합니다. 이는 각 토픽이 하나의 키워드 그룹과 강하게 연관되도록 하여 토픽 다양성을 높이는 효과도 가져옵니다. 논문에서는 Sinkhorn 알고리즘을 사용하여 이 문제를 해결합니다.
- Cross-Entropy Loss (Lce) 와의 관계: 본 논문에서는 Optimal Transport 손실함수가 모델 학습이 최적점에 도달했을 때 Cross-Entropy 손실값과 같아짐을 증명합니다.

4 Experiment
Dataset
- 사용된 데이터셋
- AgNews, 20News, DBLP, R8 데이터셋이 사용되었습니다.
- 이 데이터셋들은 토픽 모델링 및 준지도(semi-supervised) 텍스트 분류를 위한 벤치마크 데이터셋입니다.
- 모든 데이터셋에는 실제 레이블(ground truth labels)이 있습니다.
- 문서 평균 길이는 5.4단어부터 155단어까지 다양합니다.
- 준지도학습 설정: Classification performance and Topic Diversity 평가
- DBLP 및 AgNews 데이터셋에서는 동일한 레이블을 사용했습니다.
- 20News 데이터셋에서는 유사한 4개의 클래스를 샘플링하여 사용했습니다.
- 평가에 사용한 데이터셋: AgNews, DBLP, 20News
- 토픽 수는 클래스 수와 동일하게 설정했습니다.
- 각 클래스에 대해 3개의 키워드를 제공했습니다.
- 이 키워드는 데이터의 20%를 훈련 세트로 사용하여 각 클래스의 상위 tfidf 점수를 가진 단어를 선택했습니다.
- 나머지 80%의 데이터는 테스트 세트로 사용했습니다.
- 비지도학습 설정: Clusterability and Topic coherence 평가
- 평가에 사용한 데이터셋: AgNews, 20News, DBLP, R8
- 토픽 수는 클래스 수에 1을 더한 값으로 설정했습니다.
- 외부 정보 미사용: 이 연구에서는 데이터셋 자체를 제외한 외부 정보나 전이 학습(transfer learning) 또는 대규모 언어 모델(language model) 기반의 방법은 사용하지 않았습니다. 이러한 방법들을 제외한 이유는 논문의 Appendix Q 에 자세히 설명되어 있습니다.
- 모델 아키텍처 및 하이퍼파라미터
- 인코더 네트워크는 두 개의 은닉 레이어를 가진 완전 연결 신경망(fully-connected neural network)을 사용했습니다.
- 레이어 크기: [256, 64] 유닛
- 활성화 함수: ReLU
- 드롭아웃(dropout) 레이어: 비율 0.5
- 임베딩 사용: 단어 임베딩(word embedding)으로는 데이터셋 자체에서 학습된 Spherical text embedding 을 사용했습니다.
- vONT 및 vONTSS 특정 설정
- vONT (비지도 학습 버전): vMF 분포의 반경(radius)을 10으로 설정했습니다.
- vONTSS (준지도 학습 버전): alpha = 1, delta = 1 로 고정하고 lambda = 0.01 을 사용함
4.1 Unsupervised vONT experiments
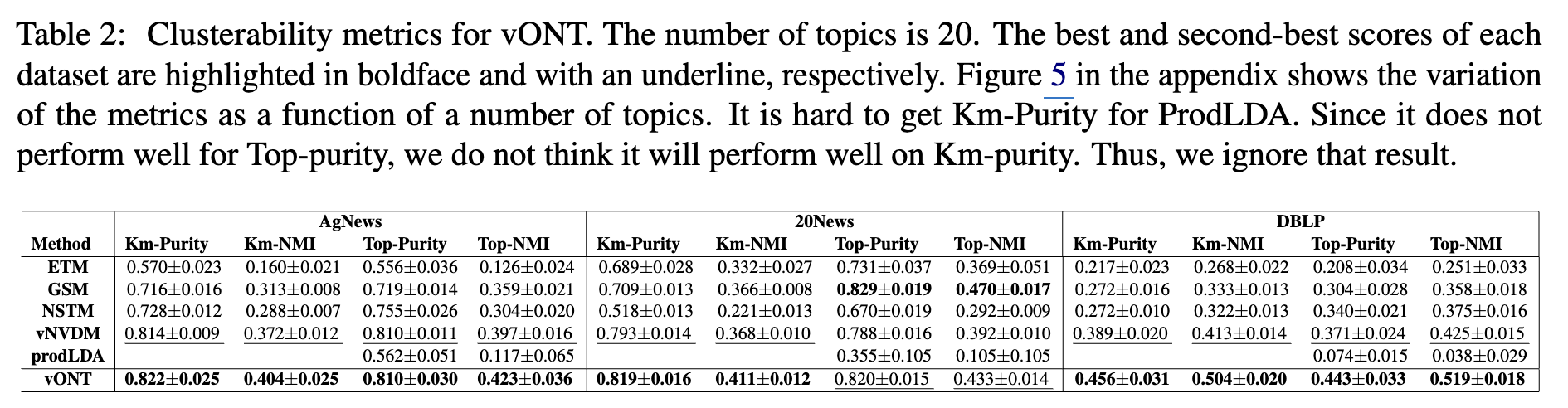
- 클러스터 품질 (Clusterability)
- Table 2에 제시된 클러스터 품질 지표에서 vONT가 모든 데이터셋에 걸쳐 다른 방법론들보다 훨씬 우수한 성능을 보였습니다.
- 이는 vMF 분포가 문서들을 명확하게 구분되는 그룹(클러스터)으로 잘 묶어주는 특성(good clusterability)을 유도함을 의미합니다.
- vONT는 또한 클러스터 관련 지표에서 가장 낮은 분산을 보여, 성능이 안정적임을 알 수 있습니다.
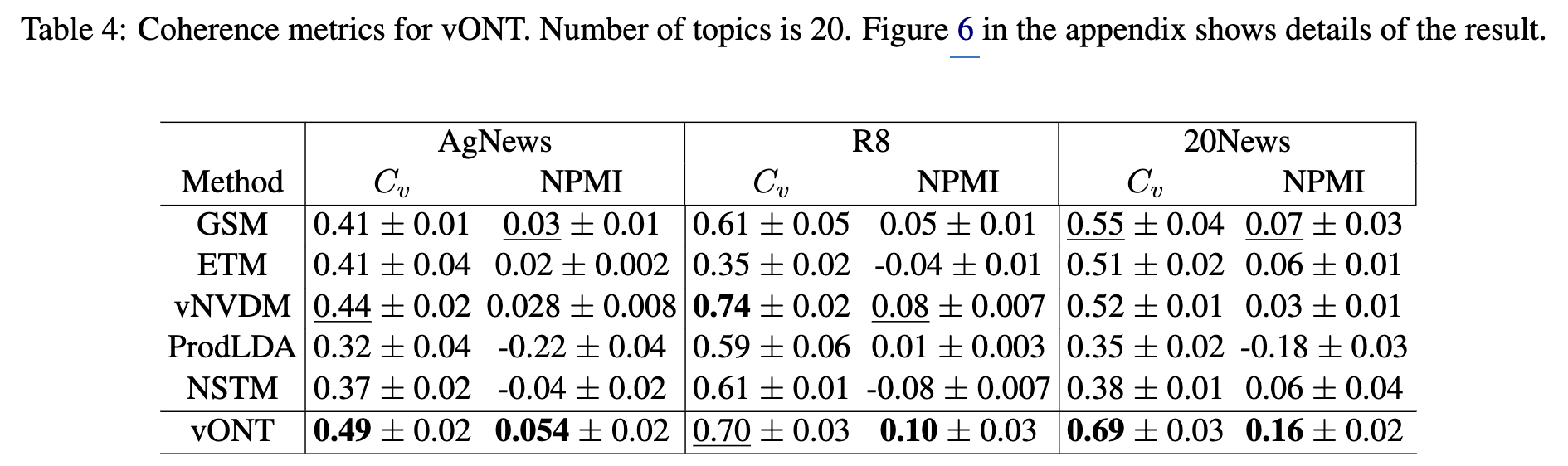
- Topic Coherence
- Appendix F에 따르면, vONT는 Cv와 NPMI라는 토픽 코히어런스 지표에서 다른 모델들보다 뛰어난 성능을 보였습니다.
- 토픽 코히어런스는 토픽을 구성하는 단어들이 의미적으로 얼마나 관련성이 높은지를 나타냅니다. vONT의 높은 코히어런스 점수는 생성된 토픽이 인간이 이해하기에 더 자연스럽고 의미 있는 단어들로 구성되어 있음을 시사합니다.
- 연구진은 온도의 개념(temperature function) 도입이 vONT의 코히어런스 성능 향상에 기여했다고 보고 있습니다.
- 토픽 다양성 (Topic Diversity)
- Appendix P에 따르면, vONT는 토픽 다양성 측면에서도 좋은 성능을 보였으며, 다른 방법론들에 비해 가장 낮은 분산을 나타냈습니다.
- 토픽 다양성은 생성된 토픽들이 서로 얼마나 다른 단어들로 구성되어 있는지를 나타냅니다. 다양성이 높을수록 모델이 문서 집합 내의 다양한 주제를 잘 포착해낸다고 볼 수 있습니다.
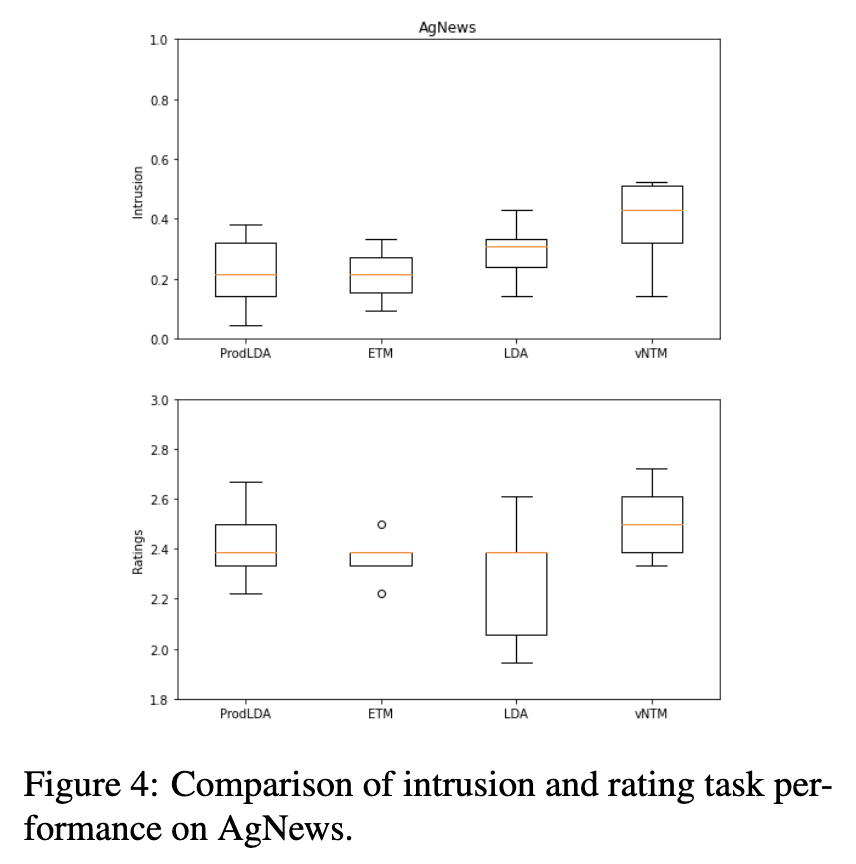
- Human Evaluation
- 토픽의 해석 가능성(human interpretability)을 평가하기 위해 단어 침입 테스트(intrusion test)와 평점 테스트(rating test)를 수행했습니다
- AgNews 데이터셋으로 실험한 결과, vONT는 정성적인 측면에서 ProdLDA, ETM, LDA보다 현저히 우수한 성능을 보였습니다.
- word intrusion task 에서는 vONT가 0.4점으로 가장 높은 점수를 기록했으며, rating test 에서도 vONT가 2.51점으로 가장 높았습니다.
- 이러한 human evaluation 결과는 vONT가 생성한 토픽이 인간이 더 쉽게 이해하고 해석할 수 있음을 의미합니다.
4.2 Semi-Supervised vONTSS experiments
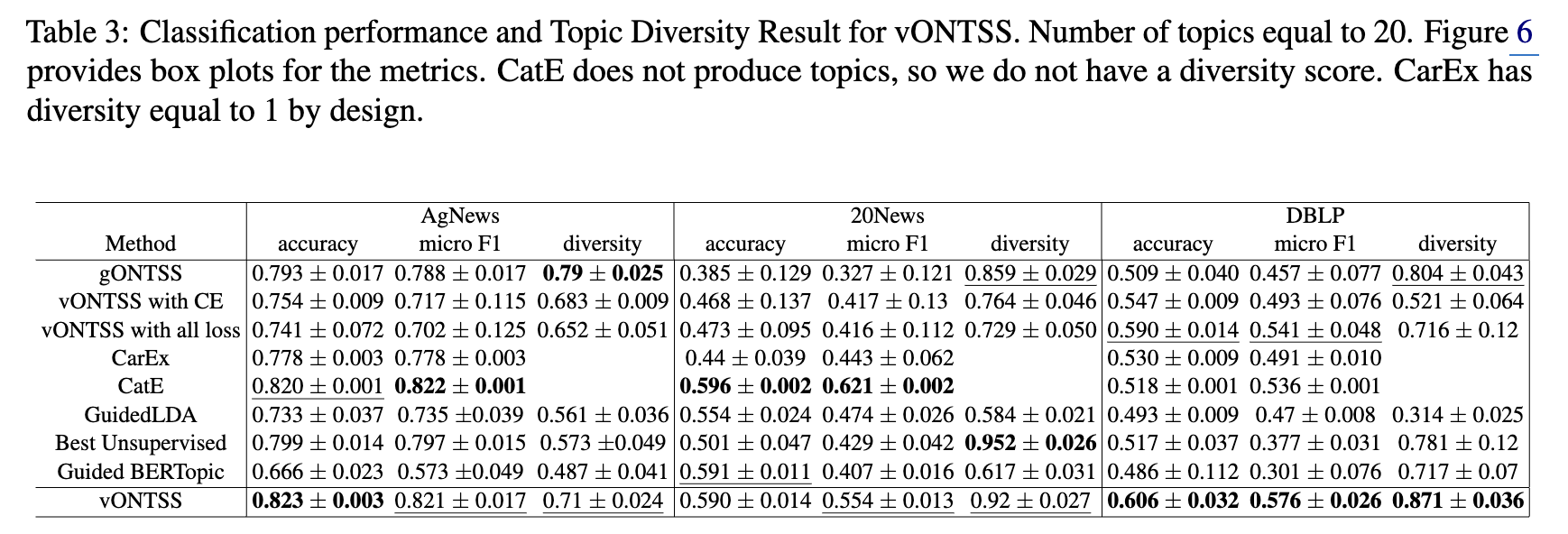
- 뛰어난 분류 정확도 및 F1 점수
- vONTSS는 다른 모든 준지도 학습 토픽 모델링 방법들보다 분류 정확도(accuracy)와 micro F1 점수에서 우수한 성능을 보였습니다.
- 특히 AgNews와 같이 텍스트 길이가 길고 데이터셋 규모가 큰 경우에 이러한 강점이 두드러졌습니다.
- 높은 안정성
- vONTSS는 다른 모델들에 비해 표준 편차(standard deviation)가 낮습니다.
- 이는 모델이 여러 번 실험했을 때 결과의 변동성이 적다는 것을 의미하며, 실제 응용 환경에서 모델을 사용할 때 예측 가능하고 일관된 성능을 기대할 수 있게 합니다.
- Optimal Transport(최적 수송)의 효과
- Optimal Transport를 사용한 vONTSS는 Optimal Transport를 사용하지 않은 vONTSS 변형 모델들 (vONTSS with CE, vONTSS with all loss)과 비교했을 때, 분류 정확도, 토픽 다양성(diversity), 그리고 낮은 분산(variance) 측면에서 훨씬 좋은 결과를 보였습니다.
- Optimal Transport 기법이 생성된 토픽의 정확도와 안정성, 그리고 서로 다른 토픽 간의 구별을 향상시키는 데 중요한 역할을 한다는 것을 시사합니다.
- CatE와의 비교
- vONTSS는 CatE라는 최신 weakly supervised(약지도 학습) 텍스트 분류 방법과 품질 측정치(quality metrics)에서 유사한 성능을 보였습니다.
- 하지만 Appendix Table 5에 따르면, vONTSS는 CatE보다 15배 더 빠릅니다. 이는 vONTSS가 효율성 측면에서 큰 장점을 가지고 있음을 보여줍니다.
- 준지도 학습 방법의 필요성 입증
- 최적의 seed 단어 매칭을 사용하더라도 비지도 학습(unsupervised) 방법들은 준지도 학습 방법들만큼 비교할 만한 결과를 내지 못했습니다.
- 이는 사용자의 특정 지식(예: 몇 개의 키워드)을 모델에 반영하는 준지도 학습 접근 방식이 특정 목표(예: 분류) 달성에 필수적임을 보여줍니다.
- Guided Bertopic과의 비교
- Guided Bertopic 방법은 좋은 결과를 내지 못했고 안정성도 떨어졌습니다.
- Guided Bertopic에서는 할당된 multiplier가 모든 토픽에 걸쳐 증가하여 토픽 확률이 덜 대표적으로 되는 문제가 있을 수 있음을 언급합니다. 이는 vONTSS가 더 효과적인 접근 방식을 사용하고 있음을 시사합니다.
5 Conclusions
- vONTSS 모델 제안: 이 논문은 vMF(von Mises-Fisher) 분포, 온도 함수(temperature function), Optimal Transport, 그리고 VAE(Variational Autoencoders)를 활용한 새로운 준지도 신경망 주제 모델링 방법인 vONTSS를 제안.
- vMF 분포: 구(sphere) 상의 분포로, 잠재 공간에서 데이터의 클러스터링을 개선하는 데 사용되었습니다.
- 온도 함수: vMF 분포의 샘플에 Softmax를 적용하기 전에 사용되어 분포의 "반경"을 조절하고 표현력과 분리성을 높입니다.
- Optimal Transport: 최적 운송 이론을 활용하여 준지도 학습 설정에서 키워드 세트와 주제를 효과적으로 매칭하는 데 사용됩니다. 또한 Cross-Entropy 손실과의 이론적 등가성을 이론적으로 증명합니다.
- 비지도 학습 버전 vONT: vONTSS의 비지도 학습 버전인 vONT는 기존 최신 기술에 비해 뛰어난 주제 일관성(topic coherence)을 보입니다. 이는 자동 평가뿐만 아니라 사람이 직접 평가한 결과에서도 확인되었습니다. 또한, 주제 간 높은 클러스터링 가능성(clusterability)을 유도합니다.
- Optimal Transport 손실의 특징: Optimal Transport 손실은 최적 조건(global minimal) 하에서 Cross-Entropy 손실과 동일하며, 키워드 세트와 주제 간의 일대일 매칭을 유도하는 것으로 이론적으로 증명되었습니다.
- 준지도 학습 버전 (vONTSS)의 장점
- vONTSS는 경쟁력 있는 문서 분류 성능을 달성합니다.
- 높은 주제 다양성(topic diversity)을 유지합니다.
- 빠른 학습 속도
- 다양한 데이터셋에서 가장 낮은 분산(variance)을 보여 안정적입니다.
Limitations and Risks
- vMF 분포의 단위 제약: vMF 분포는 샘플 값이 단위 구(unit sphere) 상에 존재해야 하는 제약이 있습니다. 이는 잠재 공간(latent space)의 다양성을 제한하고, 주제(topic) 수가 증가함에 따라 모델 성능 향상에 제약을 줄 수 있습니다. 논문에서는 이러한 한계를 극복하기 위해 Bivariate von Mises 분포 또는 Kent 분포와 같이 더 풍부한 다양성을 가진 다른 분포를 시도해 볼 수 있다고 언급합니다.
- 약한 지도 학습(weakly supervised) 설정에서의 성능: 약한 지도 학습 환경에서 vONTSS는 사전 학습된 언어 모델(pre-trained language models)을 활용하는 방법들만큼 뛰어난 성능을 보이지 못할 수 있습니다. 논문 저자들은 향후 연구로 vONTSS 모델의 구조와 기존 언어 모델링 기법을 결합하여 분류 성능을 개선할 수 있다고 제안합니다.
- Semi-supervised 설정에서 각 주제에 최소 하나의 키워드가 필요하다는 제약: vONTSS의 현재 준 지도 학습 형태는 각 주제에 대해 최소 하나의 키워드 제공을 필요로 합니다. 이는 실제 사용 환경에서 적용 가능성을 제한할 수 있습니다. 이를 해결하기 위한 방안으로는 주제-키워드 매핑 전에 주제를 미리 선택하거나, Gumbel 분포를 사용하여 최적 운송(optimal transport) 손실 함수를 수정하는 방법을 제시합니다.
Reference
[1] Neural variational inference for text processing (ICML 2016)
[2] Whai: Weibull hybrid autoencoding inference for deep topic modeling (ICLR 2018)
[3] Decoupling sparsity and smoothness in the dirichlet variational autoencoder topic model (JMLR 2019)
[4] Hyperspherical Variational Auto-Encoders
[5] Spherical Text Embedding (Neurips 2019)
[6] Sinkhorn distances: Lightspeed computation of optimal transportation distances (Neurips 2013)
[7] Super-convergence: very fast training of neural networks using large learning rates