[Paper Review] Do Neural Topic Models Really Need Dropout? Analysis of the Effect of Dropout in Topic Modeling (EACL 2023)

Do Neural Topic Models Really Need Dropout? Analysis of the Effect of Dropout in Topic Modeling (EACL 2023)
Suman Adhya, Avishek Lahiri, Debarshi Kumar Sanyal
Abstract
- Dropout이란 ?
Dropout은 뉴럴 네트워크 학습 시 과적합(overfitting) 문제를 해결하기 위해 널리 사용되는 정규화(regularization) 기법입니다.
특히 작은 데이터셋으로 큰 feedforward 뉴럴 네트워크를 학습할 때, 학습 데이터에서는 성능이 좋지만 학습에 사용되지 않은 테스트 데이터에서는 성능이 떨어지는 과적합 문제를 완화하는 데 효과적입니다. - 기존의 Dropout 효과에 대한 연구와의 차이점: Dropout의 효과는 Convolutional Neural Network (CNN)와 같은 지도 학습(supervised learning) 모델에서 광범위하게 연구되었습니다. 하지만, VAE-based neural topic models와 같은 비지도 학습(unsupervised models)에서의 dropout 효과에 대한 분석은 부족했습니다.
- 본 논문의 Analysis: 이 논문은 VAE(Variational Autoencoder) 아키텍처의 인코더(encoder)와 디코더(decoder)에서 dropout을 사용했을 때 어떤 결과가 나타나는지 분석했습니다. 분석 대상 모델은 널리 사용되는 세 가지 neural topic mode 인 CTM (contextualized topic model), ProdLDA, ETM (embedded topic model)입니다. 분석에는 공개적으로 사용 가능한 네 가지 데이터셋이 활용되었습니다.
- Dropout의 효과를 평가하는 기준: 생성된 토픽의 품질(quality), 예측 성능(predictive performance)
1 Introduction
- Neural Topic Model (NTM): NTM은 기존의 전통적인 토픽 모델의 한계를 극복하기 위해 신경망의 장점을 활용하는 모델입니다. 기존 모델의 단점이었던 높은 계산 비용과 모델 변경 시 추론 방법 재도출의 어려움을 개선하여, 더 높은 유연성과 확장성을 제공합니다.
- VAE 기반의 NTM: NTM의 한 종류로, Auto-Encoding Variational Bayes(AEVB) [1] 라는 추론 기술을 기반으로 합니다.
Topic Modelling Meets Deep Neural Networks: A Survey 논문에서 이러한 모델들을 VAE-NTM으로 분류하고 있습니다. - VAE-NTM의 학습 목표
- VAE-NTM은 학습 과정에서 두 가지 목표를 동시에 달성하려고 합니다. 이는 VAE 의 일반적인 학습 방식과 유사합니다.
- 입력 문서 재구성 가능성 최대화 (Maximize the log-likelihood): 모델이 원본 문서를 얼마나 잘 복원할 수 있는지를 나타냅니다. 이는 토픽 표현이 문서의 내용을 잘 담고 있도록 학습하는 것을 의미합니다.
- 잠재 공간의 사후 분포와 사전 분포 간의 KL-divergence 최소화: 잠재 공간(여기서는 문서의 토픽 분포)에서 학습된 근사 사후 분포가 미리 정해놓은 간단한 사전 분포(e.g., 가우시안 분포)와 최대한 유사해지도록 합니다. 이는 잠재 공간을 잘 구조화하고 안정적인 학습을 유도하는 역할을 합니다. KL-divergence는 두 확률 분포 간의 차이를 측정하는 지표이며, 이 값을 최소화함으로써 두 분포를 비슷하게 만듭니다.
- 이전 연구 [2]
- LDA (Latent Dirichlet allocation) 및 BTM (A biterm topic model for short texts)과 같은 전통적인 토픽 모델에 dropout을 적용하는 연구를 수행했습니다. 이 연구에 따르면, 적절한 dropout 비율을 선택하면 모델 학습 시간을 단축할 수 있었습니다.
- 특히 짧은 텍스트의 경우, 예측 성능과 일반화 능력이 크게 향상되었습니다. 하지만 이 연구는 뉴럴 토픽 모델(Neural Topic Models)은 고려하지 않았습니다.
- 본 논문의 차별점 및 기여
- 본 논문은 이전 연구의 한계를 해결하고자 합니다.
- VAE-NTMs(VAE 기반 뉴럴 토픽 모델)에 dropout을 하이퍼파라미터로 사용하여 성능을 향상시키는 방안을 제안합니다. CTM, ProdLDA, ETM 등 다양한 VAE-NTM 아키텍처에 대해 dropout 효과를 검증했습니다.
- 이를 통해 토픽 일관성(topic coherence), 토픽 다양성(topic diversity), 토픽 품질(topic quality) 측면에서 더 나은 성능을 달성하는 것을 목표로 합니다.
- 본 논문 저자들은 뉴럴 토픽 모델에 대한 dropout의 사용을 구체적으로 다룬 연구는 본 논문이 처음이라고 밝히고 있습니다.
Main Contributions
- 최적의 dropout 값 선택으로 인한 토픽 품질 향상 (정량적 및 정성적): VAE-NTM의 인코더와 디코더 모두에서 드롭아웃 설정을 매우 낮게 하거나 아예 사용하지 않을 때 토픽 품질이 크게 향상됨을 정량적 지표(예: NPMI, Topic Quality)와 정성적 평가(더 해석하기 쉬운 토픽)를 통해 포괄적으로 보여주었습니다.
- 다운스트림 작업 성능 향상: VAE-NTM에서 낮은 드롭아웃 비율을 체계적으로 선택하는 것이 문서 분류와 같은 다운스트림 작업의 성능을 상당히 개선할 수 있음을 입증했습니다.
- 입력 문서 길이와 드롭아웃의 의존성 분석: 드롭아웃이 입력 문서 길이에 따라 어떻게 영향을 미치는지 분석했습니다. 기존 연구에서는 긴 텍스트에 드롭아웃이 효과적이지 않다고 했지만, 이 논문에서는 VAE-NTM의 경우 문서 길이에 상관없이 드롭아웃 비율이 증가함에 따라 성능이 일관되게 감소하는 경향을 보였습니다.
- 드롭아웃 감소에 따른 성능 향상 분석: 드롭아웃 비율이 낮아질수록 VAE-NTM의 성능이 향상되는 현상에 대한 경험적 분석 결과를 제시했습니다. 이러한 실험결과를 드롭아웃이 생성 모델의 데이터 분포 학습을 방해할 수 있기 때문이라고 분석했습니다.
2 Task Formulation
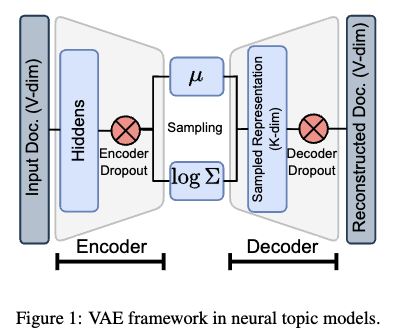
2.1 VAE Framework in Neural Topic Models
- 입력 문서 표현: 인코더(encoder)의 입력은 문서 표현입니다. 예를 들어, 각 단어가 등장하는 빈도를 나타내는 bag-of-words 벡터와 같이 문서의 특징을 나타내는 벡터 형태입니다. 여기서 V 는 어휘 사전의 크기입니다.
- 인코더의 역할
- 인코더는 입력 문서 x 를 받아서 잠재 변수(latent variable) z 에 대한 근사 사후 분포 approximate posterior distribution 를 학습합니다.
- W 는 인코더가 학습해야 할 가중치입니다.
- VAE-NTM에서는 이 근사 사후 분포를 가우시안 분포(Gaussian distribution)로 가정하고, 인코더는 이 분포의 평균과 분산을 출력합니다.
- K 는 잠재 공간(latent space)의 차원입니다.
- 잠재 변수 샘플링 (Reparameterization Trick): 디코더(decoder)는 인코더가 출력한 가우시안 분포에서 잠재 표현 z 을 샘플링합니다. 이 샘플링 과정은 신경망을 통해 역전파(backpropagation)가 가능하도록 reparameterization trick을 사용하여 수행됩니다. 이 트릭을 통해 샘플링 과정의 무작위성 epsilon 을 평균과 분산에서 분리하여, 평균과 분산에 대한 그래디언트(gradient)를 계산하고 학습을 진행할 수 있습니다.
- 문서-토픽 분포 생성: 샘플링된 잠재 표현 z 로부터 문서-토픽 분포 벡터 theta 가 생성됩니다. 이는 소프트맥스(softmax) 함수를 사용하여 계산됩니다. theta 의 각 요소는 문서가 특정 토픽에 속할 확률을 나타냅니다.
- 디코더의 역할 및 문서 재구성: 디코더는 문서-토픽분포와 토픽-단어 행렬를 사용하여 원래 입력 문서-단어 분포 벡터를 재구성합니다.
이 과정에서 디코더는 학습 가능한 가중치 \(W'\)을 사용하여 입력이 주어졌을 때 이를 재구성할 확률 \(p_{W'}(x|z)\)을 학습합니다. - VAE 프레임워크에서 Dropout 적용
- 인코더 Dropout: 인코더 내부의 multi-layer feed-forward neural network (FFNN)의 은닉층(hidden layer) 출력에 확률로 dropout이 적용됩니다. 이 출력은 이후 근사 사후 분포 q 의 매개변수를 얻기 위한 두 개의 별도 레이어로 전달됩니다.
- 디코더 Dropout: 문서-토픽 분포 벡터 theta 에 확률로 dropout이 적용됩니다. 이는 문서 재구성 과정 바로 직전에 수행됩니다.
- 이러한 VAE 프레임워크는 문서에서 토픽 분포를 학습하고 이를 통해 문서를 재구성하는 방식으로 작동합니다. Dropout은 이 과정의 특정 지점에 적용되어 모델의 과적합(overfitting)을 방지하는 정규화 기법 (regualization technique) 으로 사용됩니다.
2.2 Task Description
- Dropout 비율 변화: 인코더(Encoder)와 디코더(Decoder) 모두에서 dropout 비율을 0.0부터 0.6까지 0.1 간격으로 변화시키며 실험했습니다. 상한선인 0.6은 이 연구에서 비교 대상으로 삼은 기존 VAE-NTMs에서 사용된 가장 높은 dropout 비율이기 때문에 선택되었습니다.
- 성능 측정 항목: 연구진은 모델 성능을 다음 세 가지 주요 지표를 사용하여 측정했습니다.
- Topic Coherence (토픽 응집도, 일관성): 토픽을 구성하는 상위 단어들이 의미론적으로 얼마나 관련이 있는지를 측정합니다. 여기에서는 NPMI 를 사용하여 측정하였습니다.
- Topic Diversity (토픽 다양성): 생성된 토픽들이 서로 얼마나 다른지, 즉 고유한지를 측정합니다. Topic Diversity (TD) [3] 지표를 사용했으며, 이는 모든 토픽에 걸쳐 나타나는 고유 단어의 비율로 정의됩니다. 0에 가까울수록 반복적인 토픽이 많고, 1에 가까울수록 토픽들이 다양합니다.
- Topic Quality (토픽 품질, TQ): 토픽 응집도와 토픽 다양성의 곱으로 정의되는 종합적인 지표입니다 [3].
- 추가 평가 방법: 자동화된 토픽 모델 측정 지표가 항상 토픽의 품질을 정확하게 포착하지 못할 수 있기 때문에 [4], 토픽에 대한 수동 평가와 문서 분류(document classification) 다운스트림 task 에서의 예측 성능 평가도 함께 수행했습니다.
3 Empirical Study
3.1 Datasets
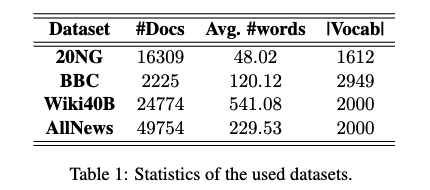
- 20NG, BBC: OCTIS toolkit in the pre-processed format
- Wiki40B [5], AllNews [6]
- Train/Valid/Test sets -> 70 : 15 : 15.
- Validation set 은 오직 early stopping 을 위해 사용되었습니다.
3.2 Models
- 연구에서 실험에 사용한 NTMs
- CTM (CombinedTM)
- ProdLDA
- ETM
- 실험 설정
- 모델 학습 시 dropout을 제외한 모든 하이퍼파라미터(hyperparameter)는 각 모델의 원 논문에서 제시된 기본값과 동일하게 설정했습니다.
- 토픽의 개수 K는 {20, 50, 100} 중 하나로 설정하고, 각 모델을 30 epoch 동안 학습시켰습니다.
- 결과의 신뢰성을 높이기 위해 각 모델을 10번 독립적으로 실행하여 나온 점수들의 평균을 사용했습니다.
- Dropout 적용
- VAE 아키텍처에서는 인코더(Encoder)와 디코더(Decoder)에 각각 dropout이 적용될 수 있으며, 연구에서는 두 부분의 dropout 비율(각각 Ep와 Dp로 표기)을 변화시키며 실험했습니다.
- 비교 대상: 최적의 dropout 비율로 학습된 모델의 성능을 해당 모델의 원 논문에서 사용한 기본(default) dropout 비율로 학습된 모델의 성능과 비교했습니다.
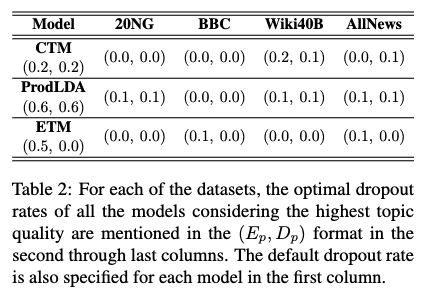
- Table 2 설명
- 이 표는 각 모델(CTM, ProdLDA, ETM)에 대해 사용된 데이터셋별 기본 dropout 비율과 최적 dropout 비율을 보여줍니다.
dropout 비율은 (Ep, Dp) 형식으로 표시되어 있으며, 여기서 Ep는 인코더의 dropout 비율, Dp는 디코더의 dropout 비율을 나타냅니다. - 예를 들어서, CTM의 기본 dropout은 (0.2, 0.2)이지만, 20NG 데이터셋에서는 (0.0, 0.0)일 때 topic quality가 가장 높았고, BBC 데이터셋에서도 (0.0, 0.0)일 때 가장 높았습니다.
- 이 표는 각 모델(CTM, ProdLDA, ETM)에 대해 사용된 데이터셋별 기본 dropout 비율과 최적 dropout 비율을 보여줍니다.
3.3 Results and Analysis
3.3.1 Quantitative Evaluation of Topic Quality
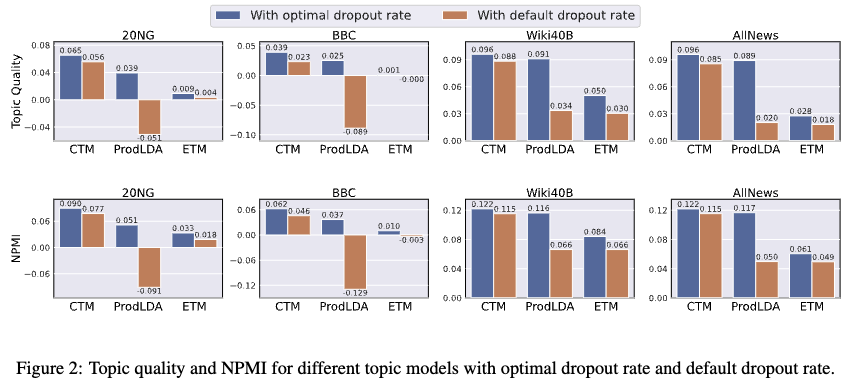
- 토픽 품질 향상: 드롭아웃 비율을 최적화함으로써 VAE-NTMs 모델(CTM, ProdLDA, ETM)의 토픽 품질 점수가 전반적으로 향상되었습니다.
- 20NG 데이터셋 결과: CTM의 토픽 품질 점수는 기존 0.056에서 0.065로 향상되었습니다. 이는 약 16.07%의 성능 향상입니다.
ProdLDA의 토픽 품질 점수는 기존 -0.051에서 0.039로, ETM은 기존 0.004에서 0.009로 향상되었습니다. 이 두 모델의 경우 성능 향상률이 100%를 초과합니다. - 성능 향상률 차이의 원인: CTM의 경우, 기존 구현에서 이미 비교적 낮은 드롭아웃 비율(인코더와 디코더 모두 0.2)을 사용하고 있었기 때문에 최적화로 인한 추가 성능 향상 폭이 다른 모델(ProdLDA와 ETM)에 비해 작았습니다. ProdLDA와 ETM은 기존 구현에서 더 높은 드롭아웃 비율을 사용했기 때문에 최적화를 통한 성능 향상 폭이 컸습니다.
- Findings: 이 결과는 VAE-NTMs에서 드롭아웃 비율을 단순히 기본값으로 설정하기보다는 데이터셋과 모델 특성에 맞춰 신중하게 조정하는 것이 중요하다는 것을 시사합니다. 논문에서는 특히 낮은 드롭아웃 비율에서 더 좋은 토픽 품질이 나타나는 경향을 보인다고 언급하고 있습니다
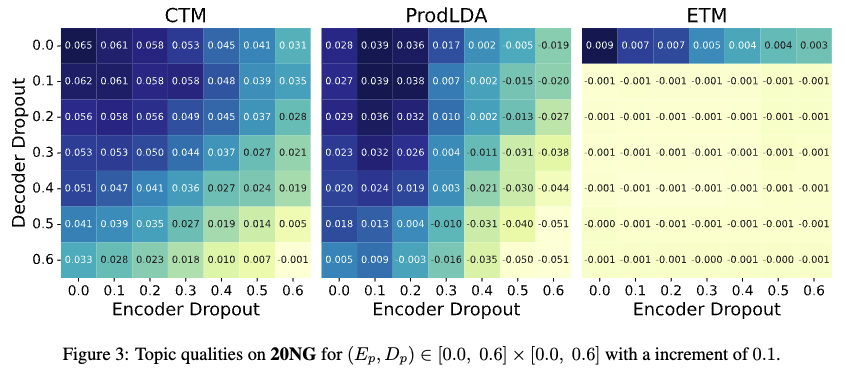
- 실험결과
- Figure 3은 20NG 데이터셋에서 VAE-NTMs (CTM, ProdLDA, ETM)의 토픽 품질 점수가 인코더 드롭아웃 비율 E_p 과 디코더 드롭아웃 비율 D_p 변화에 따라 어떻게 달라지는지를 보여줍니다.
- Figure 3의 실험결과에 따르면, 20NG 데이터셋에서 VAE-NTMs의 토픽 품질은 일반적으로 인코더와 디코더의 드롭아웃 비율이 0.0 또는 0.1과 같이 낮거나 0에 가까울 때 더 좋은 결과를 보입니다. 드롭아웃 비율이 높아질수록 토픽 품질은 저하되는 경향을 확인할 수 있습니다.
- 저자들은 다른 데이터셋(BBC, Wiki40B, AllNews)에서도 유사한 결과가 관찰되었다고 언급하며, 이는 드롭아웃 비율이 VAE-NTMs의 성능에 중요한 영향을 미치는 하이퍼파라미터임을 시사합니다.
- Findings: 이러한 결과는 기존 지도 학습에서 드롭아웃이 과적합 방지에 효과적이었던 것과 대조적입니다. 저자들은 섹션 4에서 이에 대해 논하며, VAE-NTMs와 같은 생성 모델의 경우 드롭아웃이 입력 데이터에 노이즈를 주어 모델이 데이터 분포 특성을 정확하게 학습하는 것을 방해하기 때문에 토픽 품질이 저하될 수 있다고 설명합니다.
3.3.2 Qualitative Evaluation of Topic Quality

- Optimal dropout 모델과 기본모델이 생성한 주제들을 정성평가 하기 위해 주제 정렬 시도
- 최적의 드롭아웃 모델(토픽 목록 P)과 기본 드롭아웃 모델(토픽 목록 Q)의 토픽들을 비교하기 위해 두 단계의 토픽 정렬 전략을 사용했습니다.
- 유사도 행렬 생성: 먼저, Rank-biased Overlap (RBO)라는 척도를 사용하여 토픽 목록 P와 Q 간의 유사도 행렬 A를 생성했습니다. RBO는 순서가 있는 두 목록(여기서는 토픽 내 단어들의 순서) 간의 유사도를 측정하는 방법으로, 순위가 높은 요소에 더 큰 가중치를 부여합니다.
- 토픽 쌍 선택: 유사도 행렬 A에서 유사도 점수가 가장 높은 토픽 쌍을 반복적으로 선택합니다. 이 과정을 통해 최적 드롭아웃 모델의 토픽과 기본 드롭아웃 모델의 가장 유사한 토픽을 짝지을 수 있습니다.
- 정성적 평가: 이렇게 정렬된 토픽 쌍들의 상위 단어들을 Table 3에 제시하고 시각적으로 비교했습니다. 논문 저자들은 이 비교를 통해 드롭아웃 최적화 모델이 더 해석하기 쉬운 토픽을 생성한다는 것을 확인했습니다. 자동화된 토픽 모델 측정 지표가 항상 토픽의 질을 정확하게 포착하지 못한다는 점 [4] 를 고려할 때, 이러한 정성적 평가는 중요합니다.
3.3.3 Effect of Dataset Length
- 문서길이와의 연관성: 이 논문에서는 사용된 데이터셋(20NG, BBC, Wiki40B, AllNews) 중 20NG는 비교적 짧은 텍스트를 포함하고 있고, 다른 데이터셋은 긴 텍스트를 포함하고 있음을 언급합니다. 실험 결과, 드롭아웃 비율이 증가함에 따라 모든 VAE-NTM 모델의 성능이 일관되게 감소하는 것을 확인했습니다. 이러한 성능 감소는 데이터셋의 길이가 짧든 길든 상관없이 나타났습니다.
- 이전연구 [2] 에서는 자신들의 드롭아웃 방법이 긴 텍스트에서는 효과적이지 않다고 보고했습니다.
- 두 연구 결과의 차이: 이 논문의 저자들은 자신들의 연구 결과가 [2] 의 발견과 다르다고 지적합니다. [2] 는 드롭아웃이 긴 텍스트에 효과가 없다고 했지만, 이 논문에서는 긴 텍스트 데이터셋에서도 드롭아웃 비율 증가가 성능 감소로 이어진다는 것을 보여줍니다. 이는 전통적인 토픽 모델(LDA, BTM)에 대한 [2] 의 분석과 VAE-NTM에 대한 이 논문의 분석에서 나타나는 차이점일 수 있습니다.
3.3.4 Document Classification
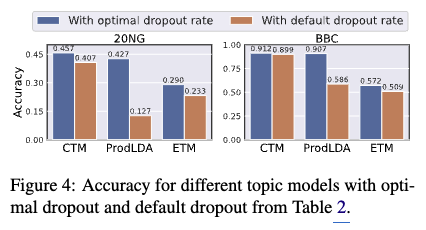
- Downstream task 실험
- 토픽 모델이 생성한 토픽의 품질이 실제 다운스트림 작업(여기서는 문서 분류)에 어떤 영향을 미치는지 측정합니다.
- 데이터셋: 20NG 및 BBC 코퍼스를 사용했습니다.
- 토픽 개수 (K): 토픽 개수를 20개, 50개, 100개로 다양하게 설정하여 모델을 학습시켰습니다.
- 훈련/테스트 분할: 각 데이터셋의 훈련 서브셋을 사용하여 토픽 모델과 분류기를 학습시키고, 테스트 서브셋을 사용하여 분류기의 성능을 평가했습니다.
- 문서 표현: 각 문서는 토픽 모델을 통해 얻은 K 차원의 'document-topic vector'로 표현됩니다. 이 벡터는 해당 문서가 각 토픽에 대해 얼마나 관련되어 있는지를 나타냅니다.
- 분류기 학습: 이 document-topic vector를 입력으로 사용하여 SVM (Support Vector Machine) 분류기를 훈련시켰습니다. SVM은 지도 학습 알고리즘으로, 주어진 입력 벡터를 기반으로 문서의 카테고리를 예측하도록 학습됩니다.
- 성능 평가
- 훈련된 SVM 분류기를 테스트 서브셋의 document-topic vector에 적용하여 문서의 카테고리를 예측했습니다.
- 평가지표로 정확도(accuracy)를 측정하고, 서로 다른 토픽 개수 (K=20, 50, 100)에 대한 정확도 (Acc) 점수를 평균하여 최종 성능 지표로 사용했습니다.
- 실험결과: 최적화된 dropout rate를 사용했을 때 문서 분류 작업의 정확도가 향상되는 것을 확인했습니다 (Figure 4 참고). 이는 적절한 dropout 설정을 통해 토픽 모델이 더 유용하고 예측력 있는 토픽 표현을 학습했음을 시사합니다.
4 Theoretical Understanding of Results
- VAE 기반의 NTM 의 성능 향상
- 본 논문에서의 emperical study 는 드롭아웃 비율을 신중하게 조절하면 VAE-NTM의 성능을 크게 향상시킬 수 있음을 보여줍니다.
- 드롭아웃 비율은 모델과 데이터셋의 종류에 따라 신중하게 선택해야 하는 중요한 하이퍼파라미터로 다루어져야 한다고 주장합니다. 특히 VAE-NTM의 경우 더욱 그렇습니다.
- 낮은 드롭아웃 비율의 효과: 대부분의 경우, 인코더와 디코더 모두에서 낮은 드롭아웃 비율을 사용할 때 높은 드롭아웃 비율을 사용했을 때보다 더 나은 성능을 얻을 수 있었습니다.
- 지도 학습과의 차이: 지도 학습 기법에서는 Dropout과 같은 표준 드롭아웃 및 다양한 변형이 광범위하게 사용됩니다. 지도 학습에서 드롭아웃의 주된 목적은 훈련 과정에 노이즈를 주입하여 모델이 테스트 단계에서 이상치를 잘 인식하고 과적합을 방지하는 것입니다.
- 생성 모델(VAE-NTM) 관점에서의 드롭아웃 해석: 본 연구에서 높은 드롭아웃 사용 시 성능이 저하되는 것은 VAE-NTM이 데이터의 생성 모델을 학습하는 과정에 기인할 수 있다고 해석합니다. 드롭아웃은 입력 데이터의 작은 변화(섭동)에 대해 모델을 강건하게 만들지만, 역설적으로 입력 데이터 분포의 특징을 정확하게 학습하는 것을 방해할 수 있습니다. 이것이 토픽 응집도(topic coherence)와 토픽 품질(topic quality)이 떨어지는 이유일 수 있습니다.
- 문서 분류 성능 저하: 문서 분류 작업의 경우, 높은 드롭아웃으로 훈련된 토픽 모델에서 생성된 문서-토픽 벡터는 품질이 낮아지고, 이러한 저품질 벡터로 훈련된 분류기의 테스트 문서에 대한 정확도가 떨어지게 됩니다. 이는 분류기에 직접 드롭아웃을 적용하여 과적합을 방지하는 일반적인 신경망 분류기의 지도 학습 설정과는 다릅니다.
5 Conclusion
- 분석연구와 주요 Findings
- 이 논문은 VAE-NTM 모델(CTM, ProdLDA, ETM)에서 인코더(encoder)와 디코더(decoder)에 적용된 드롭아웃 비율이 모델 성능에 미치는 영향을 심층적으로 분석했습니다.
- 인코더와 디코더 모두에서 드롭아웃 비율이 증가함에 따라 VAE-NTM 모델의 성능이 일반적으로 감소한다는 사실을 발견했습니다.
- 결과 해석: 논문에서는 이러한 결과가 VAE-NTM이 데이터의 생성 모델을 학습하려 하기 때문이라고 설명합니다. 드롭아웃은 입력 데이터에 노이즈를 주어 모델이 과적합(overfitting)되는 것을 방지하는 일반적인 정규화 기법이지만, VAE-NTM과 같은 생성 모델에서는 너무 높은 드롭아웃 비율이 데이터 분포의 특성을 정확하게 학습하는 것을 방해할 수 있습니다. 이는 토픽 일관성 및 품질 저하로 이어집니다.
- 지도 학습과의 차이: 지도 학습(supervised learning) 시나리오, 특히 신경망 분류기에서 드롭아웃은 주로 분류기 자체에 적용되어 과적합을 방지하는 데 효과적입니다. 하지만 VAE-NTM은 데이터를 생성하는 모델을 학습한 후, 이 모델에서 얻은 문서-토픽 벡터를 다운스트림 태스크(예: 문서 분류)에 활용합니다. 따라서 VAE-NTM 학습 단계에서 높은 드롭아웃으로 인해 토픽 모델의 품질이 낮아지면, 이는 결국 다운스트림 태스크의 성능 저하로 이어진다고 논문은 설명합니다.
- Optimal dropout: 논문은 대부분의 경우 인코더와 디코더에서 매우 낮은 드롭아웃 비율(예: 0.0 또는 0.1) 또는 드롭아웃을 사용하지 않는 것(0.0)이 높은 성능을 얻는 데 더 효과적임을 실험적으로 보여줍니다. 따라서 드롭아웃 비율을 모델과 데이터셋의 특성에 맞춰 신중하게 선택해야 할 중요한 하이퍼파라미터로 다루어야 한다고 강조합니다.
Limitations
- 다른 종류의 드롭아웃 적용: 본 연구에서는 일반적인 드롭아웃 방식을 사용했지만, 다양한 드롭아웃 기법이 존재합니다. 이러한 다른 기법들이 VAE 기반 신경망 토픽 모델(VAE-NTM)에 어떤 영향을 미치는지에 대한 분석은 본 논문에서 다루지 않았습니다.
- 다른 VAE 기반 신경망 토픽 모델 분석: 이 연구는 CTM, ProdLDA, ETM이라는 특정 VAE-NTM 모델에 초점을 맞추어 드롭아웃 효과를 분석했습니다. 다른 VAE-NTM 모델에서도 유사한 결과가 나타나는지 또는 모델의 특성에 따라 드롭아웃의 효과가 다를 수 있는지에 대한 추가적인 연구가 필요합니다.
- 다른 downstream task 분석: 본 연구는 문서 분류 성능을 통해 드롭아웃 효과를 평가했습니다. 토픽 모델링 결과를 활용하는 다른 후속 작업(downstream tasks)에서의 드롭아웃 효과에 대한 분석도 향후 연구 과제로 남아 있습니다.
Reference
[1] Auto-encoding variational bayes (ICLR 2014)
[2] Eliminating overfitting of probabilistic topic models on short and noisy text: The role of dropout.
[3] Topic modeling in embedding spaces (TACL 2020)
[4] Is automated topic model evaluation broken? the incoherence of coherence (Neurips 2021)
[5] Wiki-40B: Multilingual language model dataset.
[6] GraphBTM: Graph enhanced autoencoded variational inference for biterm topic model (EMNLP 2018)