[Paper Review] LoRACode: LoRA Adapters for Code Embeddings (ICLR 2025 Workshop)

LoRACode: LoRA Adapters for Code Embeddings [Deep Learning for Code (DL4C) Workshop at ICLR 2025]
Saumya Chaturvedi, Aman Chadha, Laurent Bindschaedler
Abstract
- 코드 임베딩의 중요성 및 기존 방법의 한계
- 코드 임베딩은 의미 기반 (자연어-코드) 코드 검색에 필수적입니다. 하지만 기존 접근 방식은 코드에 내재된 구문적, 문맥적 미묘함을 정확하게 포착하는 데 어려움을 겪습니다.
- Open-source models: CodeBERT, UniXcoder와 같은 오픈 소스 모델은 확장성과 효율성에 한계가 있습니다.
- 성능이 뛰어난 proprietary 시스템 (즉, closed-source model) 은 큰 계산 비용을 요구합니다.
- LoRACode
- 본 논문은 Low-Rank Adaptation (LoRA) 기반의 파라미터 효율적인 파인 튜닝 방법을 제안합니다.
- 이 방법은 코드 검색을 위한 태스크별 어댑터(task-specific adapters)를 구축하는 데 사용됩니다.
- 학습 가능한 파라미터 수를 기본 모델의 2% 미만으로 줄입니다.
- 이를 통해 방대한 코드 코퍼스(200만 개 샘플)에 대해 두 개의 H100 GPU로 25분 만에 빠르게 파인 튜닝할 수 있습니다.
- 실험 결과, Mean Reciprocal Rank (MRR)에서 Code2Code 검색의 경우 최대 9.1% 향상, Text2Code 검색의 경우 다수의 프로그래밍 언어에서 최대 86.69% 향상된 성능을 보여줍니다.
- 태스크별 및 언어별 어댑터의 구분을 통해 구문적, 언어적 변화에 대한 코드 검색의 민감도를 탐색할 수 있었습니다.
- 본 논문의 기여
- 본 논문에서 제안하는 LoRACode는 LoRA라는 Low-Rank Adaptation 기법을 기반으로 합니다. LoRA는 대규모 언어 모델(LLM)의 파인 튜닝 시 전체 모델 가중치를 업데이트하는 대신, 몇 개의 어텐션 레이어에 낮은 랭크의 행렬을 도입하여 학습 가능한 파라미터 수를 크게 줄이는 파라미터 효율적 파인 튜닝(PEFT) 방법론입니다.
- LoRACode는 이 방법을 코드 임베딩 모델에 적용하여 CodeBERT, GraphCodeBERT, UniXcoder와 같은 기존 모델의 확장성 및 효율성 한계를 극복하고, proprietary 시스템의 높은 비용 문제를 완화하고자 합니다. 이는 기존의 코드 임베딩 모델들이 직면했던 실용적인 문제를 PEFT라는 최신 기술을 활용하여 해결하려는 시도입니다.
[개인적으로 이 논문에서 궁금한 것들]
1. LoRA 를 어떻게 활용하길래 그것이 Code search task 에서 task-specific 할 수 있는가? 어떤부분에서 novelty 가 있을까?
2. Code search 연구 분야에서 아직 남아있는 limitation 은 무엇일까 ?
3. CodeBERT, GraphCodeBERT, UniXcoder 와 같은 오픈소스 모델의 확장성 및 효율성의 한계란 무엇인가? 만약, 단순하게 LoRA 를 적용하여 성능 개선 된 것이라면 이러한 오픈소스 인코더 모델들이 확장성의 한계가 있다고 말할 수 있을까?
1 Introduction
- 기존의 트랜스포머 기반 코드 임베딩 (인코더) 모델들의 한계
- 코드 특성 포착의 어움: CodeBERT [Feng et al., 2020], GraphCodeBERT [Guo et al., 2021], UniXcoder [Guo et al., 2022], StarCoder [Li et al., 2023]와 같은 모델들은 코드와 자연어의 깊은 공동 표현 학습에는 효과적이지만, 코드의 정밀한 문법적, 문맥적 뉘앙스를 포착하는 데는 한계가 있습니다.
- 규모 및 성능 제한: 이 모델들은 상대적으로 규모가 작고 BERT와 같은 아키텍처 기반이어서 텍스트 및 코드 기반 쿼리에 대한 코드 스니펫의 의미 검색과 같은 작업에서 성능이 제한됩니다.
- 다국어 작업 일반화 실패: 다양한 프로그래밍 언어에 걸쳐 일반화하는 데 어려움을 겪으며, 특정 다운스트림 애플리케이션에 미세 조정된 변형 모델에 비해 복잡한 작업에서 성능이 떨어집니다 [Xie et al., 2023].
- 미세 조정의 높은 비용: 2백만 개 이상의 샘플을 포함하는 대규모 데이터셋 [Husain et al., 2020]으로 미세 조정을 수행하는 것은 상당한 리소스 집약적 작업입니다.
- 접근성 문제: 검색 성능이 뛰어난 proprietary 시스템 (예: Voyage AI, OpenAI)은 소스 코드가 공개되지 않고 미세 조정이 불가능합니다.
- LoRACode를 통한 해결 방안
- LoRACode는 Parameter-Efficient Fine-Tuning (PEFT) 방법, 특히 Low-Rank Adaptation (LoRA) [Hu et al., 2021]을 활용하여 이러한 한계를 극복하는 새로운 접근 방식을 제시합니다.
- 매개변수 효율적인 미세 조정: LoRA를 적용하여 미세 조정을 위한 학습 가능한 매개변수 수를 기본 모델의 2% 미만으로 크게 줄입니다.
- 빠른 학습 속도: 이를 통해 두 개의 H100 GPU를 사용하여 2백만 개의 코드 샘플을 단 25분 만에 미세 조정할 수 있어 계산 효율성이 뛰어납니다.
- 성능 향상: 코드 검색 작업에서 Mean Reciprocal Rank (MRR@1)를 크게 향상시킵니다.
- Code2Code 검색에서 최대 9.1% 증가
- Text2Code 검색에서 최대 86.69% 증가
- 작업 및 언어별 어댑터
- 작업별(Text2Code, Code2Code) 및 언어별 어댑터를 생성하여 코드 검색이 문법적, 언어적 변화에 얼마나 민감한지 탐구할 수 있도록 돕습니다. Text2Code 검색의 경우 6가지 프로그래밍 언어에 대한 언어별 기능을 캡슐화하는 어댑터를 별도로 미세 조정합니다.
- 리소스 절감: 기존 시스템에 비해 계산 비용을 절감하면서 성능은 뛰어납니다.
- 공개 모델 및 코드: 연구 발전을 위해 코드와 사전 학습된 모델을 공개적으로 제공합니다.
- 이러한 개선을 통해 LoRACode는 기존 모델들의 확장성, 효율성, 일반화 및 미세 조정 비용 문제를 해결하며 코드 검색 분야에서 최첨단 성능을 달성합니다.
Main Contributions
- LoRA를 활용한 매개변수 효율적 파인튜닝(PEFT) 접근 방식 도입
- 본 논문에서는 code search task 을 위해 PEFT 기술인 LoRA를 적용한 새로운 방법을 제시합니다.
- PEFT란? 대규모 모델의 모든 매개변수를 조정하는 대신, 소수의 추가 매개변수만 학습하여 모델을 특정 작업에 맞게 효율적으로 조정하는 기술입니다.
- LoRA란? PEFT 기법 중 하나로, 기존 모델의 가중치는 고정하고 어텐션 레이어에 '저랭크 행렬(low-rank matrices)'이라는 작은 행렬 몇 개를 추가하여 학습시키는 방식입니다.
- 코드 검색에 적용: 기존 코드 임베딩 모델의 성능을 유지하거나 향상시키면서도, 대규모 모델을 처음부터 학습시키거나 전체를 파인튜닝하는 것보다 훨씬 적은 컴퓨팅 자원을 사용합니다.
- 효율적인 파인튜닝으로 계산 효율성 대폭 향상
- 기존 기본 모델 매개변수의 1.83%~1.85% 수준의 적은 매개변수만을 사용하여 효율적으로 파인튜닝할 수 있음을 보여줍니다.
- 이는 대규모 코드 데이터셋(2백만 개 샘플)에서도 두 대의 H100 GPU로 25분 만에 파인튜닝을 완료할 수 있을 정도로 빠르고 비용 효율적인 학습을 가능하게 합니다.
- Text-to-Code 검색을 위한 언어별 어댑터 제안
- 다양한 프로그래밍 언어(6개 언어)에 대해 Text-to-Code 검색 작업에서 언어별 어댑터(language-specific adapters)의 성능 향상을 평가하고 제안합니다.
- 코드와 자연어(docstring 등) 간의 의미적 매칭을 찾는 Text-to-Code 검색에서는 각 프로그래밍 언어의 고유한 문법적, 의미적 특성을 이해하는 것이 중요합니다.
- 본 논문에서는 범용 어댑터보다 특정 언어에 맞춰 학습된 어댑터가 더 나은 성능을 보인다는 것을 실험을 통해 입증했습니다.
- Mean Reciprocal Rank (MRR) 대폭 향상
- Code-to-Code 검색 작업에서 MRR@1이 최대 9.1% 증가했습니다.
- Text-to-Code 검색 작업에서 MRR@1이 최대 86.69% 증가했습니다.
- MRR이란? 검색 결과의 순위를 평가하는 지표입니다. 첫 번째 관련 결과가 높은 순위일수록 MRR 값이 높아집니다. MRR@1은 첫 번째 결과가 얼마나 정확한지를 주로 측정합니다. 이러한 성능 향상은 LoRACode가 다양한 코드 검색 작업에서 기존 모델보다 뛰어난 검색 정확도를 제공함을 나타냅니다.
2 Background & Related Work
2.1 Code Search and Embedding Models
- 초기 통계 기반 접근 방식
- [Sachdev et al., 2018], [Allamanis et al., 2015] 등의 초기 연구는 자연어 쿼리 기반 코드 검색을 Transformer를 사용하지 않는 통계 모델링 문제로 접근했습니다.
- Neural Code Search [Sachdev et al., 2018]와 같은 방법은 함수, 변수 이름, 주석 등에서 키워드를 추출하고 skip gram vectorization을 사용하여 토큰 및 문서 임베딩을 생성했습니다. 이렇게 생성된 임베딩과 쿼리 임베딩 간의 cosine similarity를 계산하여 검색에 활용했습니다. 이 방식은 코드 토큰 및 이름의 표면적인 특징만을 파악하는 데 그쳤습니다.
- Transformer 기반 코드 인코딩 (Code Embedding) 모델의 등장
- CodeBERT [Feng et al., 2020]는 프로그래밍 언어와 자연어에 대한 bimodal pre-trained BERT 모델을 도입하며 코드의 깊은 의미론을 학습하는 데 혁신을 가져왔습니다.
- Masked Language Modeling 및 Replaced Token Detection을 사용하여 학습되었으며, Transformer attention mechanism을 활용하여 관계를 모델링했습니다. 이는 다양한 다운스트림 애플리케이션에 대해 fine-tuning될 수 있는 많은 코드 임베딩 모델의 가능성을 열었습니다.
- GraphCodeBERT [Guo et al., 2021]는 CodeBERT를 확장하여 data flow graph를 통합함으로써 코드의 구조적 종속성을 포착하고 버그 탐지 및 코드 요약과 같은 작업에 더 효과적으로 만들었습니다.
- UniXcoder [Guo et al., 2022]는 텍스트, 코드, 구조화된 표현을 포함한 여러 양식(modalities)에 걸쳐 코드 표현을 통합했습니다. cross-modal pretraining을 통해 코드 변환 및 완성 같은 작업에서 최고 성능(state-of-the-art)을 달성했습니다.
- StarCoder [Li et al., 2023], CodeT5 [Wang et al., 2021], CodeT5+ [Wang et al., 2023] 등 다른 Transformer 기반 모델들도 개발되었습니다. StarCoder는 80개 이상의 프로그래밍 언어로 학습된 대규모 모델이지만, 높은 계산 비용과 독점적인 학습 데이터로 인해 오픈 소스 활용에 제약이 있습니다.
- Transformer 기반 모델의 한계 및 도전 과제
- Transformer 기반 모델 [Xie et al., 2023]은 코드 인코딩에서 발전을 이루었지만, 일부 모델은 lightweight architecture로 인해 기본 검색 작업에서 다른 작업으로 일반화하는 데 어려움을 겪거나 성능이 떨어지기도 합니다. 자연어와 코드 간의 의미론적 간극과 프로그래밍 언어별 다양한 코드 표현 방식은 검색의 복잡성을 증가시킵니다.
- [Utpala et al., 2023]는 이전 코드 임베딩 모델들이 검색 평가 중 언어별 의미론적 구성 요소와 language-agnostic 구문 구성 요소를 분리하는 데 어려움을 겪는다는 것을 보여주었습니다. [Utpala et al., 2023]의 연구는 언어별 정보를 제거하고 language-agnostic 구성 요소에 집중함으로써 검색 작업에서 상당한 성능 향상을 이끌었습니다.
2.2 Benchmarks and Datasets
- CodeXGLUE
- 코드 이해 및 생성 모델을 위한 종합 벤치마크입니다.
- 코드-텍스트 생성, 코드 완성, 코드 번역 등 다양한 작업을 포함합니다.
- 미리 전처리된 데이터셋과 평가 지표를 제공하여 코드 모델의 성능을 벤치마킹하는 데 필수적입니다.
- XLCost
- GeeksForGeeks에서 생성된 벤치마크 데이터셋입니다.
- 동일한 함수를 사용하여 7가지 프로그래밍 언어(C++, Java, Python, C#, JavaScript, PHP, C)에 걸쳐 병렬 코드 스니펫을 제공합니다. 크로스-링구얼 코드 인텔리전스 작업에 사용될 수 있습니다.
- CosQA
- 질문-응답 데이터셋입니다.
- 사람이 직접 주석을 달아 질의(query)-코드 쌍을 구성하여, 텍스트-코드 검색 작업에서 강력한 의미적 정렬을 보장합니다.
- 모델 미세 조정을 위해 효과적이지만, Python 코드에만 초점을 맞추고 있어 다른 언어에는 적용하기 어렵다는 한계가 있습니다.
- CoIR
- 코드 정보 검색(Code Information Retrieval)을 위한 벤치마크입니다.
- 소규모 및 대규모 검색 작업을 평가하여 다양한 연산 요구사항에 따른 모델 성능을 측정합니다.
- 오픈 소스 모델과 OpenAI와 같은 상용 솔루션 간의 성능 격차를 보여주며, 효율적인 검색 시스템의 필요성을 강조합니다.
2.3 Low-Rank Decomposition
- Low-Rank Adaptation (LoRA) 란?
- LoRA [Hu et al., 2021]는 대표적인 Parameter-Efficient Fine-Tuning (PEFT) 기법 중 하나입니다.
- 대규모 언어 모델을 미세 조정할 때 전체 모델 파라미터를 업데이트하는 대신, 어텐션 레이어에 저계층 분해(low-rank decomposition) 행렬을 도입하여 학습 가능한 파라미터 수를 크게 줄입니다.
- 기존의 사전 학습된(pre-trained) 모델 가중치는 고정하고, 새로 추가된 저계층 행렬만 학습시킵니다.
- LoRA의 장점
- 파라미터 효율성: 학습 가능한 파라미터 수를 전체 모델의 1%~2% 수준으로 대폭 줄입니다.
- 자원 절감: 파라미터 수가 적기 때문에 모델 미세 조정에 필요한 메모리와 계산 자원 요구량이 현저히 낮아집니다.
- 모듈성: 작업별(task-specific) 또는 언어별(language-specific) 어댑터를 생성할 수 있으며, 이는 기본 모델의 무결성을 해치지 않고 특정 작업에 맞게 모델을 쉽게 조정할 수 있게 합니다.
- LoRA 활용 사례 (Jina AI 예시)
- Jina AI의 jina-embeddings-v3 [Sturua et al., 2024] 모델도 LoRA 어댑터를 사용하여 다국어 및 긴 문맥 검색(long-context retrieval)에 활용합니다.
- Low-rank 행렬을 미세 조정하여 최소한의 계산 비용으로 고품질 임베딩을 생성하며, 이는 텍스트-코드 및 코드-코드 검색에서 코드 임베딩의 효율성을 높이는 데 LoRA가 효과적임을 보여줍니다.
- 본 논문의 approach
- 이 논문에서는 이러한 LoRA 기법을 코드 임베딩에 적용하여 Code2Code 및 Text2Code 검색 작업의 성능을 향상시키는 방법을 제시합니다.
- LoRA를 통해 적은 파라미터로도 CodeBERT CodeBERT, GraphCodeBERT GraphCodeBERT, UniXcoder 와 같은 기본 모델의 성능을 개선할 수 있음을 보여줍니다. 특히, 이 논문에서는 Text2Code 검색 시 다국어 (programming languages) 데이터셋 전체에 대해 하나의 어댑터를 학습시키는 것보다 특정 프로그래밍 언어에 맞춰 언어별 어댑터를 학습시키는 것이 더 효과적임을 발견했는데, 이는 LoRA의 파라미터 제약과 프로그래밍 언어의 다양한 특성 때문으로 분석하고 있습니다.
- 본 연구에서 LoRA는 Parameter-Efficient Transfer Learning for NLP와 같은 기존 PEFT 연구를 기반으로 하며, 모델의 특정 부분(어텐션 레이어)에 저계층 업데이트를 적용하여 효율성을 극대화했습니다. 이는 대규모 모델을 다양한 하위 작업에 적용하는 데 필요한 자원 부담을 크게 줄이는 데 기여했습니다. 또한, 이 논문에서 사용된 Supervised Contrastive Learning과 같은 손실 함수는 LoRA를 통해 미세 조정되는 임베딩이 검색 작업에 더 효과적으로 학습되도록 돕습니다.
2.4 Embeddings and Contrastive Fine-tuning
- 텍스트 임베딩 개선의 중요성
- 특히 규모가 작은 언어 모델의 경우 텍스트 임베딩의 성능을 향상시키는 것이 중요합니다.
Contrastive Fine-tuning 활용: Supervised Contrastive Learning과 같은 Contrastive fine-tuning 기법은 의미적으로 유사한 텍스트 쌍을 정렬하여 임베딩 품질을 높입니다. - 손실 함수 (Loss Functions): 이를 위해 컴퓨터 비전 분야에서 많이 사용되던 Contrastive loss 가 활용됩니다.
- LoRA를 통한 효율적인 개선: LoRA: Low-Rank Adaptation of Large Language Models는 어텐션 레이어에 Low-Rank 행렬을 추가하여 임베딩을 효율적으로 개선하는 방법입니다. 이를 통해 특정 데이터셋이나 작업에 맞게 모델을 효율적으로 조정할 수 있습니다.
- 특히 규모가 작은 언어 모델의 경우 텍스트 임베딩의 성능을 향상시키는 것이 중요합니다.
- Contrastive Learning과 LoRA의 결합
- [1] 연구에 따르면, Contrastive Learning 프레임워크는 긍정 쌍(Positive pairs) 간의 거리를 최소화하고 부정 쌍(Negative pairs) 간의 거리를 최대화하여 임베딩을 강화합니다. 여기에 LoRA를 통합하면 의미론적 유사성, 텍스트 검색, 분류 등의 작업에 대해 모델을 가볍고 효과적으로 fine-tuning할 수 있습니다.
- Code search task 분야 관련 연구
- [4] 연구는 9가지 데이터 증강 연산자를 활용한 Contrastive pre-training 작업을 통해 프로그램 및 자연어 시퀀스의 토큰 표현 및 모델 견고성을 향상시켰습니다.
- [5] 연구 (OpenAI) 는 레이블이 없는 데이터를 사용하여 in-batch negatives 방식의 Contrastive Learning 목표로 텍스트 및 코드 임베딩 모델을 별도로 학습시켰습니다. 이를 통해 기존 연구 대비 20.8%의 성능 향상을 달성했습니다.
- [2] 연구는 Text2Code 검색에 LoRA와 Prompt Tuning과 같은 PEFT 기법 사용을 언급하지만, 구체적인 구현이나 분석 정보는 제시하지 않았습니다.
- [3] CodexEmbed: A Generalist Embedding Model Family for Multiligual and Multi-task Code Retrieval 연구는 instruction-tuned LLM을 사용한 코드 검색의 발전을 강조하며, 대부분의 대규모 코드 임베딩 모델이 Voyage AI’s와 같이 독점적이며 오픈소스 모델이 부족함을 지적합니다. [3] 는 CoIR 벤치마크에서 좋은 성능을 보이지만, 대규모 모델 의존성으로 인해 높은 저장 공간 및 계산 비용이 발생합니다.
- 본 논문의 LoRACode는 더 작은 코드 임베딩 모델에 LoRA 어댑터를 활용하여 이러한 문제를 해결하고, 자원 오버헤드를 크게 줄이면서 성능을 개선합니다.
3 Design and Implementation
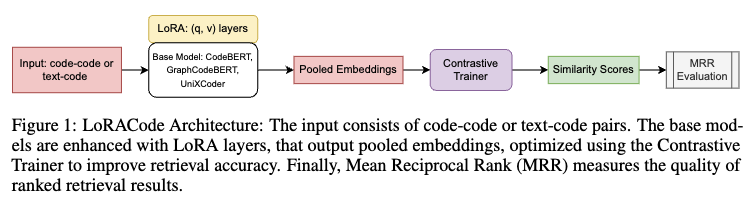
- LoRACode의 목적: 코드 검색 작업을 더 효율적으로 수행하기 위해 LoRA 어댑터를 사용합니다. 특히 자연어 질의로 코드를 찾거나(Text2Code) 코드로 코드를 찾는(Code2Code) 두 가지 주요 작업에 중점을 둡니다.
- 작동 방식
- 입력된 코드 토큰과 Docstring(코드 설명) 토큰을 임베딩(embedding)으로 변환합니다. 각 쿼리 포인트에 대한 유사도 점수를 계산합니다.
- 관련 코드 프로그램의 유사도 점수 배열을 정렬하고 Mean Reciprocal Rank (MRR)을 계산하여 검색 품질을 평가합니다.
- 기반 모델 및 LoRA
- CodeBERT [Feng et al., 2020], GraphCodeBERT [Guo et al., 2021], UniXcoder [Guo et al., 2022]와 같은 사전 학습된 코드 임베딩 모델을 백본(backbone)으로 사용합니다.
- 이 모델들은 LoRA [Hu et al., 2021] 기법을 사용하여 효율적으로 파인튜닝(fine-tuning)됩니다.
- LoRA는 모델의 어텐션(attention) 레이어에만 낮은 순위의 적응(adaptation) 행렬을 도입하고 나머지 매개변수는 고정하여, 파인튜닝에 필요한 매개변수 수를 크게 줄입니다. 이를 통해 메모리 사용량과 학습 속도를 개선합니다.
- 어댑터 종류
- 작업별 어댑터 (Task-specific adapters): Text2Code 또는 Code2Code 검색 작업에 맞게 파인튜닝됩니다.
- 언어별 어댑터 (Language-specific adapters): Text2Code 검색의 경우, 6가지 프로그래밍 언어별 특성을 반영하기 위해 언어별로 어댑터를 추가로 세분화하여 사용합니다.
- 학습 및 임베딩
- 효율적인 대조 학습(contrastive learning)을 위해 ContrastiveTrainer [Khosla et al., 2021]를 활용합니다. 이 트레이너는 쿼리와 긍정적인 코드 임베딩 간의 코사인 유사도 기반 손실 함수를 최소화하여 검색 정확도를 높입니다.
- 풀링된 임베딩(pooled embeddings)은 시퀀스 길이 전체의 은닉 상태(hidden states)를 평균하여 생성하며, 패딩(padding) 토큰은 계산에서 제외하여 가변 길이 코드 스니펫의 의미적 무결성을 유지합니다.
3.1 Task Specific Adapters
- Text2Code 검색
- 이 작업에서는 자연어 쿼리(예: 함수에 대한 설명)와 해당 코드 스니펫 간의 유사성을 찾는 것을 목표로 합니다.
- 데이터 로더는 자연어 설명(docstring)과 앵커(anchor) 코드 스니펫에 대한 특징(embeddings)을 생성합니다.
- Code2Code 검색
- 이 작업에서는 주어진 코드 스니펫과 의미적으로 유사하거나 관련된 다른 코드 스니펫을 찾는 것을 목표로 합니다.
- 데이터 로더는 쿼리 코드와 관련 코드 스니펫 모두에 대한 풀링된 임베딩(pooled embeddings)을 생성하며, 이 과정에서 언어별 특징도 통합합니다.
- 공통 과정
- 두 작업 모두에서 각 쿼리 샘플에 대해 모든 잠재적 검색 결과 후보에 대한 유사도 점수를 계산합니다.
- 계산된 유사도 점수를 기준으로 결과 임베딩 벡터를 정렬합니다.
- 정렬된 벡터에는 순위가 할당됩니다.
- 마지막으로, 모든 쿼리에 대해 순위의 역수(1/Rank)의 평균을 계산하여 Mean Reciprocal Rank (MRR)를 산출합니다.
- Mean Reciprocal Rank (MRR)
- MRR 값이 높을수록 시스템이 관련 결과를 더 높은 순위로 잘 배치한다는 것을 의미합니다. 즉, 사용자가 원하는 정보를 더 빠르게 찾을 수 있습니다.
- 이 연구에서는 특히 Text2Code 검색에서 언어별 어댑터를 사용했을 때 MRR이 크게 향상되는 것을 발견했습니다 (페이지 7, Table 4 참고).
- 이는 언어별 미세 조정이 다국어 데이터셋 전체에 대해 하나의 어댑터를 사용하는 것보다 더 효과적일 수 있음을 시사합니다.
- Language Agnostic Code Embeddings와 같은 이전 연구에서도 다국어 검색이 단일 언어 검색보다 낮은 성능을 보인다고 보고했는데, 이 연구의 결과는 이를 더욱 뒷받침하며 언어별 특성을 고려하는 것의 중요성을 강조합니다.
3.2 Language Specific Adapters
- 목표: 각 프로그래밍 언어(Go, Java, JavaScript, PHP, Python, Ruby 등)의 고유한 문법(syntax)과 의미(semantics)적 차이를 모델이 효과적으로 관리하도록 하는 것입니다.
- 접근 방식: 모든 언어에 대해 하나의 어댑터를 사용하는 대신, 개별 프로그래밍 언어별로 특화된 '언어별 어댑터(language-specific adapters)'를 개발합니다.
- 구현 방법
- CodeSearchNet [Husain et al., 2020]과 같은 다국어 데이터셋을 사용하여 각 언어별 데이터셋을 분리합니다.
- 분리된 각 언어 데이터셋을 바탕으로 학습(training) 및 평가(testing)에 사용할 데이터를 준비합니다. LoRA를 사용하여 기본 모델을 각 언어별 데이터셋에 대해 Fine-tuning합니다.
- 이 과정에서 특징 추출(feature construction), Fine-tuning, Mean Reciprocal Rank (MRR) 평가는 기존 방식(task-specific adapter 훈련 시)과 동일하게 진행됩니다.
- Language-specific adapter 효과
- 언어별로 모델을 맞춤화함으로써 특정 언어의 코드 검색 성능을 향상시키는 것을 목표로 합니다. 이 논문의 실험 결과(Table 4)는 이러한 언어별 어댑터 방식이 Text-to-Code 검색에서 상당한 성능 향상(MRR 및 NDCG 증가)을 가져옴을 보여줍니다.
- 특히 이전 연구 [Utpala et al., 2023]에서 언어와 무관한(language-agnostic) 특성에 초점을 맞춘 것과 달리, 이 연구는 언어별 특성을 활용하여 성능을 개선하려는 시도를 했다는 점에서 차이가 있습니다.
4 Evaluation
Research Questions
- RQ1: How does the performance of LoRACode, measured through Mean Reciprocal Rank and Normalized Distributed Cumulative Gain, compare to large pre-trained code embedding models (CodeBERT, UniXcoder, GraphCodeBERT) in code retrieval tasks? (§4.4, §4.2)
- RQ2: To what extent does using LoRA’s low-rank decomposition in the attention layers reduce the computational cost and memory consumption while maintaining or improving retrieval performance on multilingual code search tasks? (§4.4)
- RQ3: What is the impact of fine-tuning code retrieval models using language-specific adapters versus task-specific adapters across different programming languages? (§4.3)
4.1 Experimental Setup
4.1.1 Datasets
- Text2Code 검색
- CodeSearchNet [Husain et al., 2020]
오픈 소스 GitHub 프로젝트에서 가져온 2백만 개 이상의 메소드를 포함합니다.
Go, Java, JavaScript, PHP, Python, Ruby 등 6가지 프로그래밍 언어를 지원합니다.
각 메소드에는 자연어 문서(예: docstrings) 및 메타데이터(저장소, 위치, 줄 번호 등)가 포함되어 있습니다. - CosQA [Huang et al., 2021]
Python 코드 토큰에 대한 질문-답변 데이터셋입니다.
사람이 직접 주석을 달아 쿼리-코드 쌍의 의미론적 정렬이 매우 정확합니다.
Text2Code 검색을 위한 미세 조정에 사용되었습니다.
- CodeSearchNet [Husain et al., 2020]
- Code2Code 검색
- XLCoST [Zhu et al., 2022]
C++, Java, Python, C#, JavaScript, PHP, C 등 7가지 언어에 걸쳐 병렬 코드 스니펫을 제공합니다.
스니펫 및 프로그램 수준 모두에서 데이터를 포함하며, 프로그램은 언어 간 정렬을 유지하면서 스니펫으로 분할됩니다.
- XLCoST [Zhu et al., 2022]
- 이전 연구와 비교해서 평가방식의 차이: Text2Code 작업에서 Language Agnostic Code Embeddings와 같은 이전 연구들이 언어 독립적인 접근 방식을 탐구한 반면, 이 논문은 CodeSearchNet 및 CosQA 데이터셋을 활용하여 언어별 미세 조정의 효과를 검증했다는 점에서 차이가 있다.
4.1.2 Metrics
- MRR@K (Mean Reciprocal Rank at K)
- MRR은 검색 결과에서 첫 번째 관련 결과(relevant result)가 나타난 순위(rank)의 역수(reciprocal) 평균입니다. MRR@K는 상위 K개의 결과 내에서 첫 번째 관련 결과의 순위만 고려합니다.
- 이 측정 기준은 시스템이 가장 관련성이 높은 결과를 얼마나 빠르게, 즉 얼마나 높은 순위로 제시하는지에 중점을 둡니다. 순위가 높을수록(즉, 첫 번째 관련 결과가 더 앞쪽에 나올수록) 역수 값은 커지고 MRR 점수도 높아집니다.
- NDCG@10 (Normalized Discounted Cumulative Gain at 10)
- NDCG는 단순히 관련 결과의 순위뿐만 아니라 각 결과의 '관련성 강도(relevance intensity)'까지 고려하여 검색 결과의 품질을 측정합니다. NDCG@10은 상위 10개의 결과에 대해 계산되며, 검색 목록 하단에 있는 관련 결과보다 상단에 있는 관련 결과에 더 많은 가중치를 부여합니다.
- 'Normalized'는 다른 쿼리나 데이터셋 간의 비교를 위해 이상적인 결과(가장 관련성 높은 항목들이 맨 위에 있는 경우)에 대한 점수로 정규화된다는 의미입니다.
- 이 측정 기준은 결과의 순서(order)와 각 결과가 얼마나 유용한지(relevance)를 모두 고려하기 때문에 특히 텍스트 기반 검색(Text2Code)에서 검색 시스템의 효율성을 평가하는 데 중요합니다. CoIR: A Comprehensive Benchmark for Code Information Retrieval Models와 같은 논문에서도 NDCG의 중요성을 언급합니다.
- Evaluation metrics 정리: MRR은 가장 좋은 결과를 얼마나 빨리 찾는지에 초점을 맞추고, NDCG는 결과 목록의 전체적인 품질, 즉 관련성 높은 결과를 얼마나 잘 정렬하는지에 초점을 맞춘다고 할 수 있습니다. 본 논문에서는 Text2Code 검색의 효율성을 평가하기 위해 이 두 가지 측정 기준을 함께 사용했습니다.
4.2 Text2Code
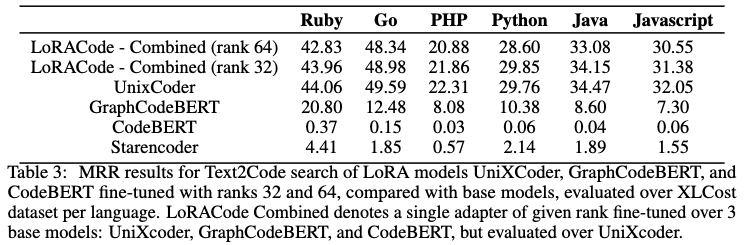
- 통합 LoRA 어댑터의 Text2Code 성능 (CodeSearchNet 데이터셋)
- 연구팀은 UniXcoder, GraphCodeBERT, CodeBERT 세 가지 기본 모델에 LoRA 어댑터를 결합하여 CodeSearchNet 데이터셋으로 Text2Code 검색 작업을 위해 미세 조정했습니다.
- 실험결과: Table 3에서 볼 수 있듯이, LoRA 랭크 32와 64를 사용한 통합 LoRA 모델의 Mean Reciprocal Rank (MRR) 결과는 기본 UniXcoder 모델에 비해 크게 향상되지 않았습니다. 이는 Text2Code 검색에서는 코드-코드 검색과 달리 작업별로 모델을 나누어 미세 조정하는 방식이 효과적이지 않음을 나타냅니다.
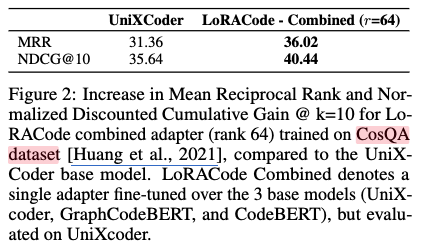
- 언어별 LoRA 어댑터의 가능성 탐색 (CosQA 데이터셋)
- 연구팀은 Text2Code 검색에 대한 두 번째 연구 질문을 탐색하기 위해 UniXcoder 모델을 단일 프로그래밍 언어에 대해 Fine-tuning 했습니다. 이를 위해 Python 코드만 포함하고 질문-답변 형식으로 구성된 CosQA 데이터셋을 사용했습니다.
- LoRA 설정을 질문-답변(QUESTION_ANS) 작업 유형으로 시도했으나 검색 작업에는 적합하지 않아, 대신 특징 추출(FEATURE_EXTRACTION) 작업 유형으로 설정하고 모델 파라미터를 고정한 채 LoRA 행렬을 미세 조정했습니다.
- 그 결과(그림 2), CosQA 데이터셋으로 미세 조정된 통합 LoRA 어댑터(rank 64)는 기본 UniXcoder 모델에 비해 MRR이 14.8%, Normalized Discounted Cumulative Gain (NDCG)이 13.5% 증가했습니다.
- CosQA 데이터셋 Fine-tuning 성능 향상의 이유
- 데이터셋 크기: CosQA [Huang et al., 2021] 는 CodeSearchNet [Husain et al., 2020] 보다 작은 데이터셋(2만 개 샘플)이지만, 단순히 데이터셋 크기가 작다는 것만이 주요 원인은 아닙니다.
- 인간 주석 데이터: CosQA [Huang et al., 2021] 는 인간이 직접 주석을 단 데이터셋으로, 질의와 코드 스니펫 간의 의미적 일관성이 매우 높습니다.
- 프로그래밍 언어별 특정 컨텍스트: CosQA [Huang et al., 2021] 는 Python 코드만 포함하는 단일 언어 데이터셋입니다. 반면 CodeSearchNet [Husain et al., 2020] 은 여러 언어를 포함합니다. 단일 언어에 대해 미세 조정하면 해당 언어의 구문적, 문맥적 특징을 더 잘 학습할 수 있어 성능이 향상됩니다.
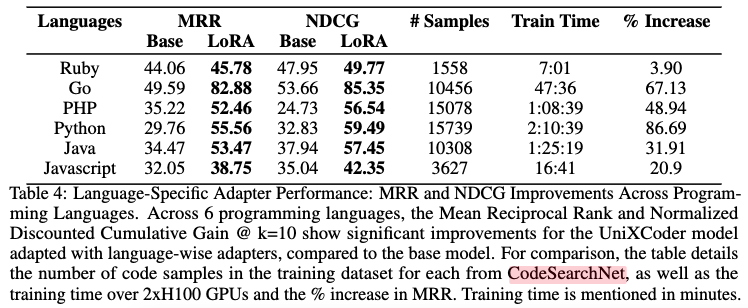
- 언어별 어댑터 성능 평가 (CodeSearchNet 데이터셋)
- CosQA 실험 결과를 바탕으로 연구팀은 CodeSearchNet [Husain et al., 2020] 데이터셋의 각 언어별 하위 데이터셋으로 LoRA 어댑터를 언어별로 미세 조정했습니다.
- Table 4 실험결과: Ruby, Go, PHP, Python, Java, Javascript 등 6개 언어 모두에서 기본 UniXcoder 모델 대비 MRR과 NDCG가 크게 향상되었습니다. 특히 Python(86.69% MRR 증가)과 Go(67.13% MRR 증가)처럼 데이터셋 규모가 큰 언어에서 더 높은 성능 향상이 나타났습니다. 이는 Text2Code 검색 작업에서 다국어 데이터셋에 대해 하나의 작업별 어댑터를 학습시키는 것보다, 언어별로 특화된 어댑터를 학습시키는 것이 훨씬 효과적임을 입증합니다.
- Findings: Text2Code 검색에서는 여러 언어를 포함하는 통합 데이터셋으로 LoRA 어댑터를 미세 조정하는 것보다, 각 프로그래밍 언어의 특성에 맞춰 언어별로 어댑터를 미세 조정하는 것이 성능 향상에 훨씬 효과적입니다. 특히 데이터셋의 품질과 크기가 언어별 어댑터의 성능에 중요한 영향을 미칩니다.
4.3 Language Specific Experimentation
- Language-specific adapter 성능 우수성: Text2Code 검색 시, 여러 프로그래밍 언어를 포함하는 통합 데이터셋으로 학습한 작업별 어댑터보다 특정 언어에 맞춰 학습한 언어별 어댑터의 성능이 더 우수하다는 중요한 결과가 확인되었습니다.
- 성능 차이의 원인
- 언어적 다양성: 다국어 데이터셋은 다양한 구문, 의미론 및 문맥적 종속성을 포함하므로 모델이 특정 언어에 특화되는 능력을 희석시킵니다.
- 제한된 매개변수: LoRA 어댑터는 학습 가능한 매개변수 수가 제한적이어서 성능 저하 없이 다양한 프로그래밍 언어에 걸쳐 일반화하기 어렵습니다.
- 구문 및 구조적 차이: 프로그래밍 언어는 Python의 들여쓰기 의존성 대 Java의 명시적인 중괄호 사용과 같이 구조적으로 크게 다릅니다. 작업별 어댑터는 이러한 차이를 설명하는 데 어려움을 겪었습니다.
- 데이터셋 크기의 영향: 학습 데이터셋 크기도 성능에 영향을 미쳤습니다.
- 언어별 어댑터는 언어당 10,000~20,000개 샘플(JavaScript 및 Ruby 제외)의 데이터셋으로 학습되어 시간이 더 오래 걸렸지만 더 풍부한 학습이 가능했습니다.
- Python(15,739개 샘플) 및 Go(10,456개 샘플)와 같이 데이터셋 규모가 큰 언어는 MRR이 각각 86.69% 및 67.13% 증가하며 가장 높은 성능 향상을 보였습니다.
- 반면 Ruby(1,558개 샘플) 및 JavaScript(3,627개 샘플)와 같이 데이터셋 규모가 작은 언어는 각각 3% 및 20.9%로 훨씬 작은 개선율을 보였습니다. 이는 데이터셋 크기와 모델의 효과적인 학습 능력 사이에 강한 상관관계가 있음을 시사합니다.
- 언어별 특성 처리
- 언어별 어댑터는 특정 언어의 고유한 특성을 더 잘 처리할 수 있었습니다.
- Python의 들여쓰기와 동적 타이핑과 같은 고유한 도전 과제는 언어별 어댑터가 더 잘 처리했습니다.
- Go 는 엄격한 구문과 최소한의 중복성 덕분에 단순성과 정적 타이핑 특성을 포착하는 맞춤형 미세 조정의 이점을 얻었습니다.
- Findings
- 본 연구에서의 실험 결과는 일반화된 접근 방식을 채택하기보다는 개별 프로그래밍 언어에 맞게 미세 조정 프로세스를 맞춤화하는 것이 중요함을 강조합니다.
- 기존 연구 Language Agnostic Code Embeddings, CoIR, CodeXEmbed 와 비교했을 때, 언어별 어댑터의 기준 점수는 유사했지만 LoRA를 통한 개선 폭이 훨씬 컸다는 점은 이 접근 방식의 유효성을 뒷받침합니다.
- 이러한 결과는 코드 검색 및 LoRA 어댑터를 사용한 미세 조정의 언어별 구성 요소에 대한 중요한 통찰력을 제공하며, 특히 학습 데이터셋 크기가 결과에 미치는 영향을 보여줍니다.
4.4 Code2Code
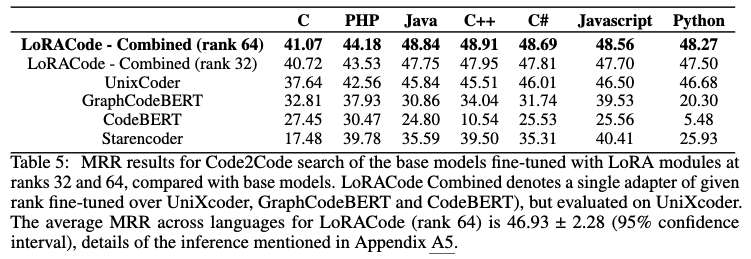
- 평가 대상 및 지표
- CodeBERT [Feng et al., 2020], GraphCodeBERT [Guo et al., 2021], UniXcoder [Guo et al., 2022] 와 같은 기본 모델에 대해 LoRA 어댑터(랭크 16, 32, 64)를 미세 조정한 결과를 평가했습니다.
- 여러 프로그래밍 언어에 걸쳐 평균 역순위(Mean Reciprocal Rank, MRR)를 주요 성능 지표로 사용했습니다.
- LoRA 어댑터의 성능 우수성
- LoRA 어댑터는 CodeBERT 및 GraphCodeBERT와 같은 임베딩 모델보다 지속적으로 더 나은 성능을 보였습니다. 이는 코드 검색에서 저랭크 적응(low-rank adaptation)의 효과를 입증합니다.
- UniXcoder [Guo et al., 2022] 와 비교했을 때도 랭크 32 LoRA 구성은 MRR을 크게 향상시켰습니다.
- 다국어 코드 검색 지원: 이러한 결과는 LoRA의 저랭크 분해(low-rank decomposition)가 검색 정확도 향상에 중요한 역할을 하며, 다국어 코드 검색에 이러한 어댑터를 사용하는 것을 지지함을 시사합니다.
- 매개변수 효율성: LoRA 구성은 전체 학습 가능한 매개변수의 1.83%~1.85%만 사용합니다. 이는 메모리 효율적이며 비용 효율적인 미세 조정을 가능하게 합니다.
- XLCoST 데이터셋의 특성 및 한계
- Text2Code 검색과 달리 Code2Code 검색 작업에서는 언어별 적응(language-wise adaptation)이 큰 의미를 갖지 못했습니다.
- 이는 XLCoST [Zhu et al., 2022] 데이터셋이 function_name을 주요 식별자로 사용하여 병렬 샘플을 통해 교차 언어 코드 검색을 수행하도록 설계되었기 때문입니다.
5 Limitations
- 학습 데이터셋의 제한된 다양성: 연구에 사용된 주요 학습 데이터셋(CodeSearchNet 및 CosQA)은 주로 GitHub의 코드-주석 쌍에서 가져온 것입니다. 이는 데이터가 오픈 소스 코드의 특징과 관행을 강하게 반영하며, 주로 자연어 쿼리에서 코드를 찾는 Text-to-Code 검색에 맞춰져 있다는 것을 의미합니다.
- Code-to-Code 검색 데이터 의존성: 코드를 코드로 검색하는 Code-to-Code 검색 기능을 구현하기 위해, 작성자들은 교차 언어 코드 쌍을 제공하는 XLCost 데이터셋에 의존했습니다. 이는 특정 유형의 데이터에 대한 의존성을 보여줍니다.
- 언어별 표현에 대한 심층 분석 부족: LoRA 기반의 미세 조정(fine-tuning) 방법이 효과적임을 보여주었지만, Transformer 아키텍처 내에서 각 프로그래밍 언어의 고유한 특징(syntax, semantics 등)이 정확히 어떻게 표현되고 학습되는지에 대한 더 깊이 있는 분석은 수행하지 않았습니다.
- 대규모 LLM 기반 검색 제외: 계산 자원(GPU 등)의 제약 때문에, 대규모 언어 모델(Large Language Models, LLM)을 기반으로 하는 코드 검색에 대한 연구는 이번 논문의 범위를 벗어나 향후 연구 과제로 남겨두었습니다.
6 Conclusion
- LoRACode 소개: LoRACode는 Low-Rank Adaptation(LoRA: Low-Rank Adaptation of Large Language Models) 기반의 Parameter-Efficient Fine-Tuning (PEFT) 기법입니다. 이는 기존의 대규모 사전 학습 모델 전체를 미세 조정하는 대신, 모델의 특정 레이어에 소수의 추가 파라미터(low-rank matrices)만 도입하여 학습하는 방식입니다. 논문에서는 이 기법을 코드 임베딩 개선에 적용했습니다.
- 성능 향상: LoRACode를 적용하여 Text2Code (자연어 쿼리로 코드 검색) 및 Code2Code (코드로 코드 검색) 검색 작업에서 코드 임베딩 성능을 크게 향상시켰습니다.
- 낮은 계산 비용: 성능 향상과 동시에 계산 오버헤드(overhead)는 낮게 유지됩니다. PEFT 기법 덕분에 전체 모델 파라미터의 극히 일부만 학습하여도 되므로, 학습 및 추론에 필요한 자원이 적습니다.
- 언어별 어댑터의 우수성: 특히 Text2Code 검색 작업에서 언어별 어댑터(language-specific adapters)가 작업별 어댑터(task-specific adapters)보다 코드의 구문적, 의미적 미묘한 차이를 포착하는 데 더 뛰어남을 확인했습니다. 이는 특정 언어에 맞춰 미세 조정을 수행하는 것이 다양한 언어를 한 번에 처리하는 것보다 효과적임을 시사합니다.
- Future work: 논문 저자들은 Code2Code 검색 작업과 다양한 언어에서 언어별 적응(language-specific adaptation)의 유사성을 더 깊이 탐구할 계획입니다.
Reference
[1] Improving text embeddings for smaller language models using contrastive fine-tuning
[2] Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning
[3] CodexEmbed: A Generalist Embedding Model Family for Multiligual and Multi-task Code Retrieval
[4] ContraBERT: Enhancing Code Pre-trained Models via Contrastive Learning
[5] Text and code embeddings by contrastive pre-training (OpenAI)