[Paper Review] LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation (ICLR 2023)

LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation (ICLR 2023)
Abstract
- (Graph) Contrastive Learning
- Contrastive Learning(CL)의 통합: GNN과 Contrastive Learning을 통합하여 데이터 희소성 문제를 해결하고 추천 성능을 향상시켰습니다.
- Contrastive Learning은 positive pair와 negative instance를 비교하여 임베딩 뷰 간의 일치도를 학습합니다.
- 기존 방법의 문제점
- 기존의 그래프 Contrastive Learning 방법들은 다음과 같은 문제점을 가지고 있습니다.
- 확률적 데이터 증강(예: 노드/엣지 perturbation) 또는 휴리스틱 기반 증강(예: 사용자 클러스터링)에 의존합니다.
본질적인 의미 구조를 잘 보존하지 못하고 노이즈에 쉽게 편향됩니다.
- LightGCL
- 간단하면서도 효과적인 그래프 Contrastive Learning 패러다임을 제안합니다.
- SVD를 사용하여 데이터 증강을 수행합니다. 이를 통해 global collaborative relation modeling을 통해 구조적 개선을 가능하게 합니다.
- 일반화 성능과 강건성(robustness)을 향상시킵니다.
- 데이터 희소성 및 popularity bias에 대한 강건성이 뛰어납니다.
1 Introduction
- 기존 GCL 방법의 한계
- 구조적 정보 손실: Graph augmentation 과정에서 무작위 Perturbation(노드 삭제, Edge 변경 등)을 사용하면 중요한 구조적 정보가 손실될 수 있습니다. 이는 Representation Learning을 저해하는 요인이 됩니다.
- 휴리스틱 기반 방법의 의존성: Representation을 Contrast하는 방식이 View Generator에 크게 의존적입니다. 따라서 모델의 일반성이 떨어지고, Noise에 취약해질 수 있습니다.
- Over-smoothing 문제: GNN 기반 Contrastive Recommender 시스템들은 Over-smoothing 문제로 인해 Representation 구분이 어려워지는 현상이 발생합니다.
- LightGCL의 접근 방식
- SVD 기반 Graph Augmentation: Singular Value Decomposition (SVD)를 활용하여 Graph Augmentation을 수행합니다. 이는 User-Item Interaction에서 유용한 정보를 추출하고, Global Collaborative Context를 Representation Alignment에 주입합니다.
- LightGCL 은 Self-Augmented Representation을 사용합니다.
- Main Contributions
- 새로운 프레임워크 제시: 추천 시스템의 주요 문제점을 해결하기 위해 가볍고 강력한 그래프 기반 Contrastive Learning 프레임워크인 LightGCL을 설계했습니다.
- 효율적인 학습 패러다임 제안: 부정확한 Contrastive 신호로 인해 발생하는 문제점을 완화할 수 있도록, global collaborative 관계를 주입하는 LightGCL이라는 효과적이고 효율적인 Contrastive Learning 패러다임을 제안합니다.
- 향상된 훈련 효율성: 기존의 GCL 기반 접근 방식과 비교했을 때 훈련 효율성이 향상되었습니다. GCL은 Graph Contrastive Learning의 약자로, 그래프 구조에서 Contrastive Learning을 적용하는 것을 의미합니다.
- 성능 우수성 입증: 다양한 실제 데이터 세트에서 광범위한 실험을 통해 LightGCL의 성능 우수성을 입증했습니다. 심층 분석을 통해 LightGCL의 합리성과 견고성을 입증했습니다.
2 Related Work
Graph Contrastive Learning for Recommendation
- SGL [1] 과 SimGCL [2] 의 문제점: 이 모델들은 random dropout을 사용하여 graph 구조와 embedding에 data augmentation을 적용하지만, 중요한 정보가 삭제될 수 있으며, 이는 inactive user의 sparsity 문제를 악화시킬 수 있습니다.
- HCCF [3] NCL [4] 의 문제점: 이 모델들은 embedding contrast를 위해 heuristic 기반의 view 생성 전략을 사용합니다. 하지만 이러한 방법들의 성공은 heuristic에 크게 의존하며, 다양한 추천 task에 adaptive하기 어렵습니다. 예를 들어, hyperedge의 수나 user cluster의 수와 같은 heuristic에 의존적입니다.
Self-Supervised Learning on Graphs
- Self-Supervised Learning (SSL)의 발전: SSL은 unlabeled 그래프 데이터를 활용하여 노드 표현(node representation)을 향상시킴으로써 그래프 학습 패러다임을 발전시켰습니다.
- Contrastive Learning (CL) over Graph Structures: 최근 연구들은 그래프 구조 상에서 Contrastive Learning (CL)을 통해 다양한 그래프 contrastive learning 방법들을 설계하는 데 집중하고 있습니다.
- SimGRACE [7] 는 GNN 인코더의 perturbation을 통해 contrastive views를 생성합니다.
- AutoGCL [8] 에서는 그래프 view 생성기가 그래프 인코더와 함께 end-to-end 방식으로 학습되도록 설계되었습니다.
- GCA [5] 는 topology-level 및 attribute-level 데이터 augmentation을 수행하여 contrastive view 생성을 합니다. 이 방법에서는 중요한 edge와 feature를 식별하여 adaptive augmentation을 수행합니다.
- GraphCL [6] 은 node/edge perturbation 및 attribute masking과 같은 다양한 augmentation 전략을 사용하여 correlated 그래프 representation views를 생성합니다.
3 Methodology
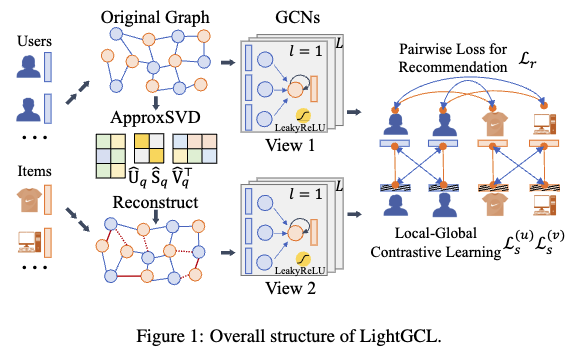
Local Graph Dependency Modeling
- A two-layer GCN
- Aggregation process
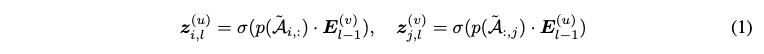

- The final embedding for a node is the sum of its embeddings across all layers
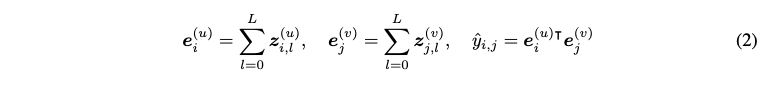
Efficient Global Collaborative Relation Learning
- 목표: 추천 시스템에서 그래프 컨트라스티브 학습을 향상시키기 위해 SVD를 사용.
- SVD: 사용자-아이템 상호 작용 그래프의 구조를 분석하고 중요한 collaborative signals 를 추출합니다.SVD를 이용한 LightGCL 강화
- Normalized adjacency matrix 에 SVD를 적용
- SVD 기반 그래프 구조 학습의 장점
- 주요 성분 강조: 사용자 선호도 표현에 중요하고 신뢰할 수 있는 사용자-아이템 상호 작용을 식별합니다.
- 글로벌 협업 신호 보존: 각 사용자-아이템 쌍을 고려하여 새로운 그래프 구조가 글로벌 협업 관계를 유지합니다.
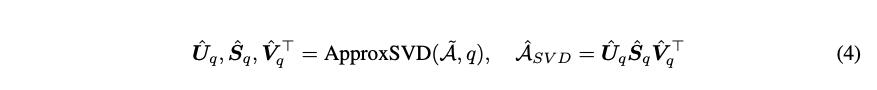
- 메시지 전달 (Message Propagation)
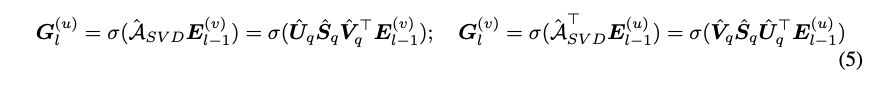
q: The required rank for the decomposed matrices
모델 효율성 향상을 위해 분해된 저차원의 행렬들을 미리 계산하여, large dense matrix 인 A_SVD 를 계산하고 저장할 필요가 없습니다.
- 효율적인 계산을 위한 Randomized SVD
- 대규모 행렬에 대한 정확한 SVD는 계산 비용이 매우 높기 때문에, 대규모 사용자-아이템 행렬에 적용하기 어렵습니다.
- Randomized SVD 알고리즘: Halko et al. (2011)이 제안한 randomized SVD 알고리즘을 사용하여 계산 효율성을 높입니다. 이 방법은 먼저 입력 행렬의 범위를 낮은 랭크의 직교 행렬로 근사한 다음, 더 작은 행렬에 대해 SVD를 수행합니다.
Simplified Local-Global Contrastive Learning
- 기존 GCL (Graph Contrastive Learning) 방법과의 차이점
- 기존 GCL 방법 (예: SGL, SimGCL)은 노드 임베딩을 비교할 때, 추가적인 두 개의 view를 생성합니다.
- 이때, 원래 그래프 (main-view)에서 생성된 임베딩은 InfoNCE 손실에 직접적으로 관여하지 않습니다.
이는 random perturbation을 통해 그래프를 augmentation할 때, main-view 임베딩에 부정적인 영향을 줄 수 있다고 판단했기 때문입니다.
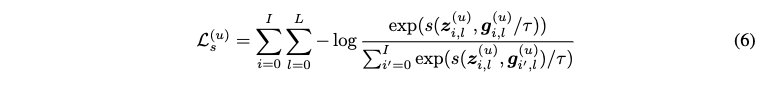
- LightGCL의 접근 방식
- LightGCL에서는 SVD (Singular Value Decomposition)를 통해 생성된 augmented graph view가 global collaborative 관계를 담고 있어 main-view 임베딩을 강화할 수 있다고 가정합니다.
- main-view 임베딩과 SVD로 augmentation된 view 임베딩을 직접적으로 비교하는 방식으로 CL 프레임워크를 단순화합니다.
수식 (6)은 사용자 임베딩에 대한 InfoNCE 손실 함수를 나타냅니다.
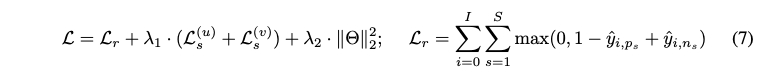
- Main objective function for the recommendation task
- First term: BPR (Bayesian Personalized Ranking) loss 와 같은 pairwise 손실 함수입니다. 이는 사용자가 선호하는 아이템과 선호하지 않는 아이템 간의 순위를 올바르게 지정하도록 모델을 학습합니다.
- Second term: contrastive learning loss
- Third term: L2 regularization loss
4 Evaluation
- RQ1: How does LightGCL perform on different datasets compared to various SOTA baselines?
- RQ2: How does the lightweight graph contrastive learning improve the model efficiency?
- RQ3: How does our model perform against data sparsity, popularity bias and over-smoothing?
- RQ4: How does the local-global contrastive learning contribute to the performance of our model?
- RQ5: How do different parameter settings affect our model performance?
4.1 Experimental settings
- 데이터셋
- Yelp: Yelp 플랫폼의 평점 데이터입니다. (29,601 명의 사용자, 24,734 개의 아이템, 1,069,128 개의 상호작용)
- Gowalla: Gowalla 플랫폼의 체크인 기록 데이터입니다. (50,821 명의 사용자, 57,440 개의 아이템, 1,172,425 개의 상호작용)
- ML-10M: MovieLens의 영화 평점 데이터입니다. (69,878 명의 사용자, 10,195 개의 아이템, 6,999,171 개의 상호작용)
- Amazon-book: Amazon의 도서 평점 데이터입니다. (78,578 명의 사용자, 77,801 개의 아이템, 2,240,156 개의 상호작용)
- Tmall: Tmall 플랫폼의 상품 구매 기록 데이터입니다. (47,939 명의 사용자, 41,390 개의 아이템, 2,357,450 개의 상호작용)
- 평가 지표
- Recall@N: 추천된 아이템 중 실제로 사용자가 선호하는 아이템의 비율을 나타냅니다. N은 추천 목록의 길이를 의미하며, 여기서는 N=20, 40이 사용되었습니다.
- NDCG@N (Normalized Discounted Cumulative Gain): 추천된 아이템의 순위를 고려하여, 관련성이 높은 아이템이 상위에 랭크될수록 높은 점수를 부여하는 지표입니다. N은 추천 목록의 길이를 의미하며, 여기서는 N=20, 40이 사용되었습니다.
- Baselines

4.2 Performance Validation (RQ1)
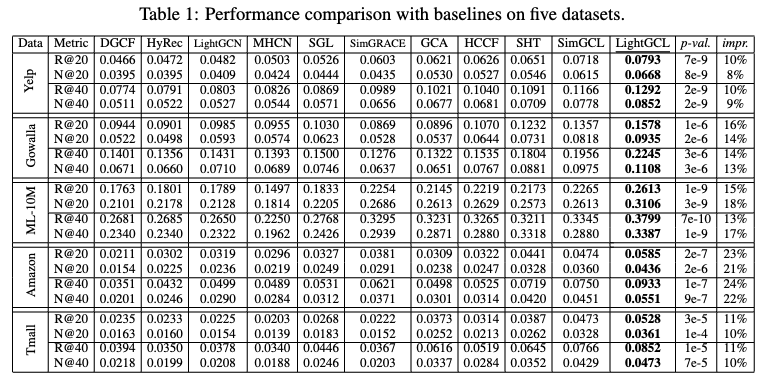
- Contrastive Learning의 우수성
- 최근 contrastive learning을 구현한 방법들(SGL, HCCF, SimGCL)이 전통적인 그래프 기반 모델(GCCF, LightGCN)이나 하이퍼 그래프 기반 모델(HyRec)보다 일관되게 우수한 성능을 보입니다.
- 이는 contrastive learning이 임베딩을 더 균등하게 분포시키는 데 효과적이기 때문일 수 있습니다
- Contrastive Learning의 향상
- LightGCL은 모든 contrastive learning baseline 모델보다 일관되게 더 나은 성능을 보입니다.
- 이러한 성능 향상은 전역적 협업 컨텍스트 신호를 주입하여 그래프 contrastive learning을 효과적으로 강화했기 때문입니다.
- 비교된 다른 contrastive learning 기반 추천 모델(예: SGL, SimGCL, HCCF)은 noisy한 상호 작용 정보에 쉽게 편향되어 잘못된 self-supervised 신호를 생성할 수 있습니다.
4.3 Efficiency Study (RQ2)
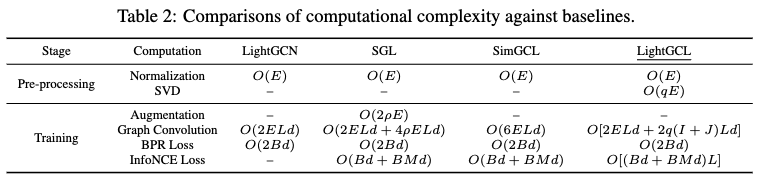
- GCL 모델의 계산 비용 문제: 기존 GCL 모델은 추가적인 view를 구성하고 convolution 연산을 수행하는 데 많은 계산 비용이 소요됩니다.
- LightGCL의 해결 방식
- SVD 기반 그래프 재구성: LightGCL은 SVD를 통해 저랭크(low-rank) 그래프를 재구성하여 계산 복잡도를 줄입니다.
- 간단한 CL 구조: LightGCL은 더 간단한 구조의 contrastive learning (CL)을 사용하여 계산 효율성을 높입니다.
- 전처리 단계의 SVD
- LightGCL은 전처리 단계에서 SVD를 수행하며, 이는 O(qE)의 시간 복잡도를 가집니다.
- SVD는 한 번만 수행되므로, 훈련 단계에 비해 계산 비용이 무시할 만합니다.
- Contrastive view 구성을 전처리 단계로 옮겨 훈련 중 반복적인 그래프 augmentation을 피함으로써 모델 효율성을 개선합니다.
- GCN 방법과의 비교
- 전통적인 GCN 방법(예: LightGCN)은 한 개의 그래프에 대해서만 convolution을 수행하므로, per-batch 복잡도는 O(2ELd) 입니다. (E는 edge 수, L은 layer 수, d는 embedding size입니다.)
- 대부분의 GCL 기반 방법은 세 개의 contrastive view를 계산하므로, 복잡도가 LightGCN의 약 세 배입니다.
4.4 Resistance Against Data Sparsity and Popularity Bias (RQ3)
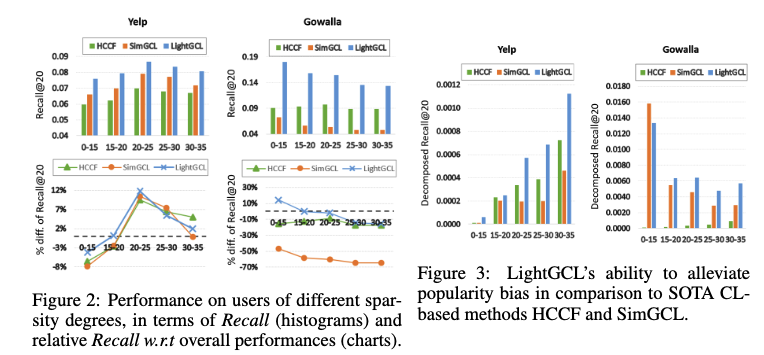
- 데이터 희소성 완화 평가
- Recall@20은 추천 시스템이 상위 20개 추천 결과 내에 사용자가 실제로 선호하는 아이템을 얼마나 잘 포함하는지를 나타내는 지표입니다.
- LightGCL은 interaction이 매우 적은 사용자 그룹(<15)에서도 전체 데이터셋과 비교하여 성능 저하가 크지 않았습니다. Gowalla 데이터셋에서는 오히려 더 높은 성능을 보이기도 했습니다.
- 인기 편향 완화 평가
- 인기 편향을 완화하는 LightGCL의 능력을 보여주기 위해, 아이템의 interaction 정도에 따라 아이템들을 그룹으로 나누었습니다. 여기서 interaction이 적은 아이템들을 "long-tail items"이라고 합니다.
- HCCF와 SimGCL은 인기 편향의 영향으로 성능 변동이 컸지만, LightGCL은 대부분의 경우에서 더 나은 성능을 보여주며 인기 편향에 대한 저항력을 입증했습니다.
4.5 Balancing Between Over-Smoothing and Over-Uniformity (RQ3)
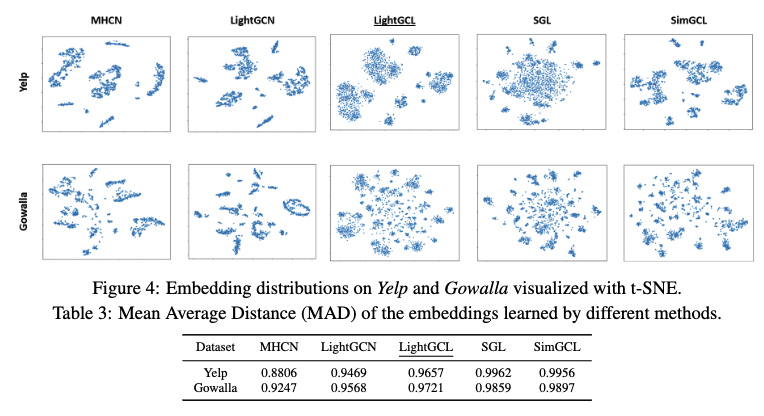
- Over-smoothing 문제: GNN 모델에서 레이어를 깊게 쌓을수록 노드 임베딩이 유사해지는 현상을 말합니다. 이는 모델이 노드 간의 차이를 학습하는 데 한계를 줍니다.
- Non-CL methods (LightGCN, MHCN): Contrastive Learning (CL)을 사용하지 않은 기존의 GNN 모델들은 임베딩 공간에서 뚜렷한 클러스터를 형성하지 못하고, 과도한 Smoothing 문제를 겪는다는 것을 의미합니다. 즉, 사용자나 아이템의 특징을 제대로 구분하지 못합니다.
- 기존의 CL-based methods (SGL, SimGCL)
- Over-uniform distributions: 임베딩들이 전체적으로 균일하게 분포되어, 데이터의 고유한 군집 구조를 반영하지 못합니다. 예를 들어, SGL 모델은 Yelp 데이터셋에서 사용자 간의 협업 관계를 제대로 포착하지 못하고, 임베딩들이 넓게 퍼져있는 형태를 보입니다.
- Highly dispersed small clusters: 임베딩들이 작은 클러스터들을 형성하지만, 클러스터 내부에서는 임베딩들이 지나치게 유사해져 Over-smoothing 문제가 발생합니다. SimGCL 모델은 Gowalla 데이터셋에서 이러한 현상을 보입니다.
- LightGCL 임베딩 시각화 결과
- LightGCL은 뚜렷한 군집 구조를 형성하여 협업 효과를 잘 나타내면서도, 각 군집 내의 임베딩들이 적절히 분산되어 사용자별 선호도를 반영합니다. 즉, LightGCL은 Over-smoothing 문제와 Over-uniform 분포 문제를 모두 완화하여 추천 시스템의 성능을 향상시킵니다.
- MAD (Mean Average Distance): 임베딩 공간에서 임베딩 벡터 간의 평균 거리를 나타내는 지표
- LightGCL은 Table 3에서 볼 수 있듯이, 기존 모델들에 비해 적절한 수준의 MAD 값을 유지하며, LightGCL이 Over-smoothing과 Over-uniformity 사이의 균형을 잘 맞추고 있음을 시사합니다.
4.6 Abalation Study (RQ4)
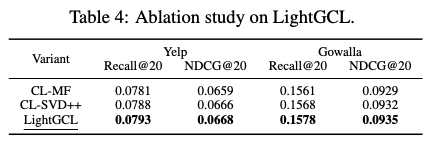
- 실험 설정: SVD 대신 다른 행렬 분해 기법을 사용한 두 가지 변형 모델(CL-MF, CL-SVD++)을 구현
- CL-MF: Matrix Factorization (MF)를 사전 학습하여 생성된 view를 사용합니다.
- CL-SVD++: SVD++를 활용하여 사용자의 implicit feedback을 고려합니다.
- 실험 결과 및 결론
- Table 4에서 볼 수 있듯이, MF 또는 SVD++에서 추출한 정보를 사용한 모델도 만족스러운 결과를 얻었습니다.
- 이는 행렬 분해가 contrastive learning (CL)을 강화하는 데 효과적이며, LightGCL 프레임워크가 다양한 행렬 분해 방식에 유연하게 적용될 수 있음을 보여줍니다.
- 결론: 그러나 사전 학습된 CL component를 사용하는 것은 번거롭고 시간이 오래 걸릴 뿐만 아니라, 성능 면에서도 approximate SVD 알고리즘을 사용하는 것보다 좋지 않았습니다. 따라서 LightGCL에서 제안하는 SVD 기반 그래프 증강 방식이 효과적임을 입증합니다.
4.7 Hyperparameter Analysis (RQ5)
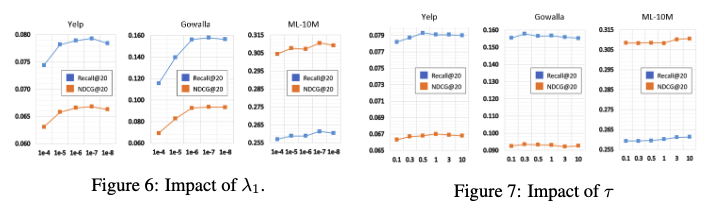
- InfoNCE loss 에 대한 정규화 가중치 (λ1)
- λ1의 역할: InfoNCE 손실에 대한 정규화 가중치 λ1은 LightGCL 모델에서 contrastive learning의 강도를 조절하는 하이퍼파라미터입니다.
- 실험 결과: 그림 6에서 Yelp, Gowalla, ML-10M 데이터셋에 대해 λ1이 10^(-7)일 때 모델 성능이 가장 높았습니다. λ1 값이 10^(-6)에서 10^(-8) 사이일 때 성능 향상이 나타났습니다.
- 해석: λ1 값이 너무 크면 contrastive learning이 너무 강해져 모델이 과도하게 특정 패턴에만 집중할 수 있습니다. 반대로 λ1 값이 너무 작으면 contrastive learning 효과가 미미해져 모델이 충분히 일반화되지 못할 수 있습니다. 따라서 적절한 λ1 값을 찾는 것이 중요합니다.
- Temperature (τ)
- τ의 역할: τ는 InfoNCE 손실 함수에서 유사도 점수를 조정하는 역할을 합니다. τ 값이 작을수록 모델은 positive pairs에 더 집중하고, τ 값이 클수록 negative pairs도 중요하게 고려합니다.
- 실험 결과: 그림 7에서 τ 값이 0.1에서 10 사이에서 비교적 안정적인 성능을 보였습니다. 그러나 최적의 τ 값은 데이터셋에 따라 달랐습니다.
- 해석: τ 값은 데이터셋의 특성에 따라 최적값이 달라질 수 있습니다. 일부 데이터셋에서는 positive pairs에 집중하는 것이 유리할 수 있고, 다른 데이터셋에서는 negative pairs도 함께 고려하는 것이 더 나은 성능을 보일 수 있습니다.
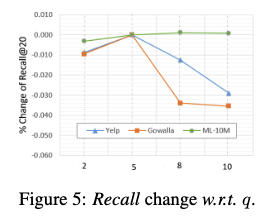
- SVD rank (q)
- q의 역할: q는 SVD(Singular Value Decomposition, 특이값 분해)에서 유지할 특이값의 개수를 결정합니다. SVD는 사용자-아이템 상호 작용 그래프의 구조를 압축하고 중요한 정보를 추출하는 데 사용됩니다. q 값이 클수록 더 많은 정보를 유지하지만 계산 비용이 증가하고, q 값이 작을수록 정보 손실이 발생할 수 있습니다.
- 실험 결과: 그림 5에서 작은 q 값으로도 만족스러운 결과를 얻을 수 있음을 보여줍니다. 특히 q = 5일 때 사용자-아이템 상호 작용 그래프의 중요한 구조를 보존하는 데 충분했습니다.
- 해석: SVD를 통해 그래프 구조를 효과적으로 압축하고, 작은 q 값으로도 중요한 정보를 유지할 수 있습니다. 이는 LightGCL 모델이 효율적으로 학습할 수 있도록 돕습니다.
4.8 Case Study (RQ4)
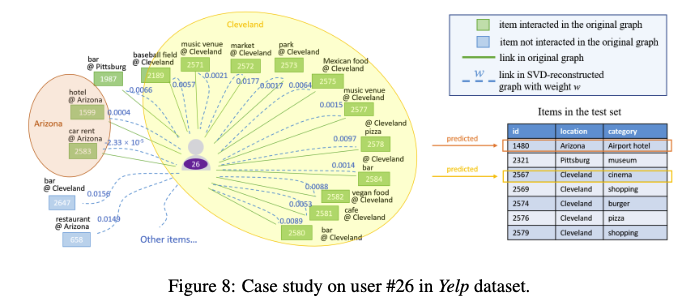
- 사용자 분석: Yelp 데이터셋에서 사용자 #26의 방문 장소를 분석한 결과, 클리블랜드(거주 추정)와 애리조나(여행 추정) 두 지역에 집중되어 있습니다.
- SVD 기반 재구성: LightGCL은 SVD를 통해 사용자-아이템 그래프를 재구성하고, 각 장소(아이템)에 중요도를 반영한 새로운 가중치를 부여합니다.
- 가중치 조정
- 애리조나의 렌터카 업체(#2583)에는 음수 가중치가 부여되었습니다. 이는 한 번 여행 시 여러 렌터카 업체를 방문하지 않는 일반적인 행동 패턴에 부합합니다.
- 방문 기록이 없는 장소 중 사용자에게 잠재적으로 흥미로운 장소(#2647, #658)에는 높은 가중치가 부여되어, 방문할 가능성이 있다고 예측합니다.
- 소규모 관심사 반영: LightGCL은 사용자의 주된 관심사 외에 상대적으로 덜 중요한 지역(애리조나)의 아이템도 놓치지 않고 추천합니다. 이는 SVD를 통해 전체적인 맥락을 고려하기 때문입니다.
5 Conclusion
- Proposed method
- 추천 시스템을 위한 그래프 대조 학습 프레임워크에 간단하면서도 효과적인 데이터 증강 방법 제시
- 특이값 분해(SVD)를 활용하여 사용자-아이템 상호 작용 그래프 구조를 효과적으로 증강
- 주요 결과
- 제안하는 그래프 증강 방식이 데이터 희소성 및 인기 편향에 강한 내성을 보임
- 여러 공개 데이터셋에서 SOTA 성능 달성
- Future work: casual analysis 을 통합하여 추천 시스템 성능 향상 및 데이터 증강 시 혼란 효과 완화
- 정리: LightGCL 은 SVD를 활용한 그래프 데이터 증강을 통해 추천 시스템의 성능을 향상시키는 새로운 방법을 제시하고, 이 방법이 데이터 희소성 및 인기 편향 문제에 효과적임을 실험적으로 입증했습니다. 향후 연구 방향으로는 인과 분석을 통한 추천 시스템 개선을 제시했습니다.
Reference
[1] Self-Supervised Graph Learning for Recommendation
[2] Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation
[3] Hypergraph Contrastive Collaborative Filtering
[4] Improving Graph Collaborative Filtering with Neighborhood-Enriched Contrastive Learning
[5] Graph contrastive learning with adaptive augmentation (WWW 2021)
[6] Graph contrastive learning with augmentations (Neurips 2020)
[7] SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation (WWW 2022)
[8] AutoGCL: Automated Graph Contrastive Learning via Learnable View Generators (AAAI 2021)