Paper Review
[Paper Review] Deep Graph Contrastive Representation Learning (ICML 2020 GRL+ workshop)
Seung-won Seo
2025. 4. 27. 21:34

Deep Graph Contrastive Representation Learning (ICML 2020 GRL+ workshop)
Abstract
- Contrastive objective: 노드 수준 (node-level) 에서 대조적 목표를 활용하여 비지도 그래프 표현 학습을 수행합니다. 여기서 대조적 목표(contrastive objective)란, 데이터의 서로 다른 representation 간의 유사성 또는 일관성을 최대화하는 것을 의미합니다.
- 그래프 뷰 생성 (Corruption): 그래프를 손상시켜 두 개의 그래프 뷰를 생성합니다. 여기서 'corruption'은 의도적으로 데이터에 노이즈나 변형을 추가하는 것을 의미합니다.
- 노드 표현 학습: 두 뷰에서 노드 표현의 일치도를 최대화하여 노드 표현을 학습합니다.
- 다양한 노드 컨텍스트 제공: 구조적 및 속성 수준에서 그래프 뷰를 생성하는 하이브리드 방식을 제안하여 대조적 목표에 대한 다양한 노드 컨텍스트를 제공합니다.
- 실험 결과: 다양한 실제 데이터 세트를 사용한 실험에서 제안된 방법이 기존의 최첨단 방법보다 우수한 성능을 보입니다. 특히, 단백질 기능 예측에서 약 10%의 절대적인 개선을 보였으며, 비지도 방법이 전이 학습 작업에서 지도 학습 방법보다 뛰어난 성능을 보였습니다.
1. Introduction
- DeepWalk 기반 방법: DeepWalk DeepWalk: Online Learning of Social Representations는 그래프 내 노드들의 임베딩을 학습하는 방법으로, 랜덤 워크를 통해 노드 간의 관계를 파악합니다.
- Graph Proximity Matrix Reconstruction: DeepWalk는 그래프의 노드 간 근접성을 나타내는 행렬을 재구축하는 방식으로 학습됩니다. 여기서 proximity matrix는 노드 간의 유사성을 나타내는 지표로 사용됩니다.
- High-order Adjacency Matrix: DeepWalk는 고차 인접 행렬(high-order adjacency matrix)과 같은 그래프 proximity matrix를 재구축하는 것으로 해석될 수 있습니다. 고차 인접 행렬은 노드 간의 간접적인 연결 관계까지 고려한 인접 행렬을 의미합니다.
- 근접성 정보 과도한 강조: DeepWalk 기반 방법은 그래프의 구조적 근접성(proximity) 정보에 지나치게 의존하는 경향이 있습니다. 이는 struc2vec: Learning Node Representations from Structural Identity 에서도 지적되었듯이, 네트워크 구조에만 의존하여 노드의 특징을 충분히 반영하지 못한다는 것을 의미합니다.
- 정보 최대화 (InfoMax)
- 정의: 입력과 그 표현 사이의 Mutual Information (MI)을 최대화하는 것을 목표로 합니다. 여기서 Mutual Information은 두 확률 변수 간의 상호 의존성을 나타내는 척도입니다.
- 배경: 전통적인 graph representation learning에서는 그래프의 인접 행렬을 재구성하는 방식 DeepWalk (Perozzi et al., 2014), node2vec (Grover & Leskovec, 2016) 등]을 사용했습니다.
- InfoMax의 역할: reconstruction objective 대신, 입력 데이터와 그 representation 사이의 정보량을 최대화하는 방식으로, visual representation learning 분야에서 재조명되었습니다.
- Contrastive Learning:
- 목표: positive pair(같은 대상에 대한 다른 representation) 간의 유사성은 높이고, negative sample(다른 대상의 representation)과는 구별되도록 학습합니다.
- (Wu et al., 2018, Tian et al., 2019, He et al., 2020) 연구에서 Mutual Information (MI)을 최대화하는 contrastive learning 방법들이 제안되었습니다.
- Deep Graph InfoMax (DGI) [1]
- 개요: visual representation learning에서의 Deep InfoMax (DIM) 방법 [Bachman et al., 2019]에서 영감을 받아, 그래프 영역에 Mutual Information 최대화 방식을 적용했습니다.
- DGI의 원리 및 한계점: GNN을 사용하여 node embedding을 학습합니다. readout function을 통해 graph embedding인 global summary embedding을 얻습니다. objective는 original graph의 node embeddings과 graph embedding 사이의 Mutual Information을 최대화하여, corrupted graph의 node와 original graph의 node를 구별합니다.
- InfoMax objective: InfoMax objective를 구현하기 위해 DGI는 injective readout function을 필요로 하지만, 이는 너무 제한적입니다.
- Injective function (단사 함수): 모든 입력에 대해 고유한 출력을 내는 함수입니다. 즉, 서로 다른 입력은 항상 서로 다른 출력에 매핑됩니다.
- Readout function: 노드 임베딩으로부터 그래프 임베딩을 생성하는 함수입니다.
- Mean-pooling readout function의 문제: DGI에서 사용하는 mean-pooling readout function은 노드 수준 임베딩에서 유용한 정보를 추출하지 못할 수 있습니다. 노드 수준 임베딩의 고유한 특징을 보존하기에 충분하지 않기 때문입니다.
- Feature shuffling의 한계: DGI는 feature shuffling을 사용하여 그래프의 corrupted view를 생성합니다. 하지만 이 방식은 negative node sample을 생성할 때 node feature를 너무 coarse-grained한 수준에서 손상시키는 것을 고려합니다.
- Sparse feature matrix의 문제: feature matrix가 sparse할 때, feature shuffling만으로는 corrupted graph에서 노드에 대해 서로 다른 neighborhood를 생성하기에 충분하지 않습니다. 이는 contrastive objective 학습의 어려움으로 이어집니다
- Proposed method: GRACE
- 기존의 Deep Graph InfoMax (DGI) Deep Graph Infomax 방법과는 달리, GRACE는 노드 수준의 임베딩에 집중하여, 그래프 임베딩 생성을 위한 injective readout function을 가정하지 않습니다.
- DGI는 feature shuffling을 통해 그래프의 corrupted view를 생성하지만, GRACE는 구조와 속성 수준에서 corruption을 고려합니다. feature matrix가 sparse할 때 feature shuffling만으로는 충분한 negative sample을 생성하기 어렵다는 점을 개선했습니다.
- GRACE 의 핵심 아이디어
- Graph의 구조(topology)와 노드 속성(node attribute) 모두에 corruption을 적용하여 다양한 graph view를 생성합니다. 구체적으로는, edge를 제거하고 feature를 masking합니다.
- Contrastive loss를 사용하여 서로 다른 view에서 동일한 노드의 임베딩 간의 agreement를 최대화하도록 모델을 학습합니다.
- Motivation: 전통적인 self-organizing network 와 visual representation learning에서의 SimCLR 에서 영감을 받았습니다.
2. The Proposed Method
2.1. Preliminaries
- G = (V,E): 그래프 G 는 노드집합 V 와 엣지집합 E 로 정의됩니다.
- X: feature matrix
- X 는 노드의 feature matrix 입니다. X 의 각 행은 각 노드를 나타냅니다.
- A: adjacency matrix
- Adjacency matrix 는 그래프의 연결 관계를 이진 형태로 표현한 행렬입니다. 사실상 G 와 A 는 완전히 같은 표현입니다. 그래프를 학습하기 위하여, 그래프를 matrix 형태로 표현한 것 입니다.
- f(X,A): GNN 인코더
- GNN 인코더 f 는 노드의 특성 X와 그래프 구조 A를 입력으로 받아 저차원 노드 임베딩을 표현하는 함수입니다. 우리의 목표는 이 GNN 인코더를 학습시켜서 좋은 표현의 노드임베딩을 얻어 downstream task 에서의 성능개선입니다.
- H = f(X, A): 노드임베딩
- H는 학습된 노드 표현(임베딩)을 나타냅니다. h_i 는 v_i 노드의 노드임베딩입니다. 이러한 학습된 노드 임베딩은 node classification 와 같은 downstream task 에 사용될 수 있습니다.
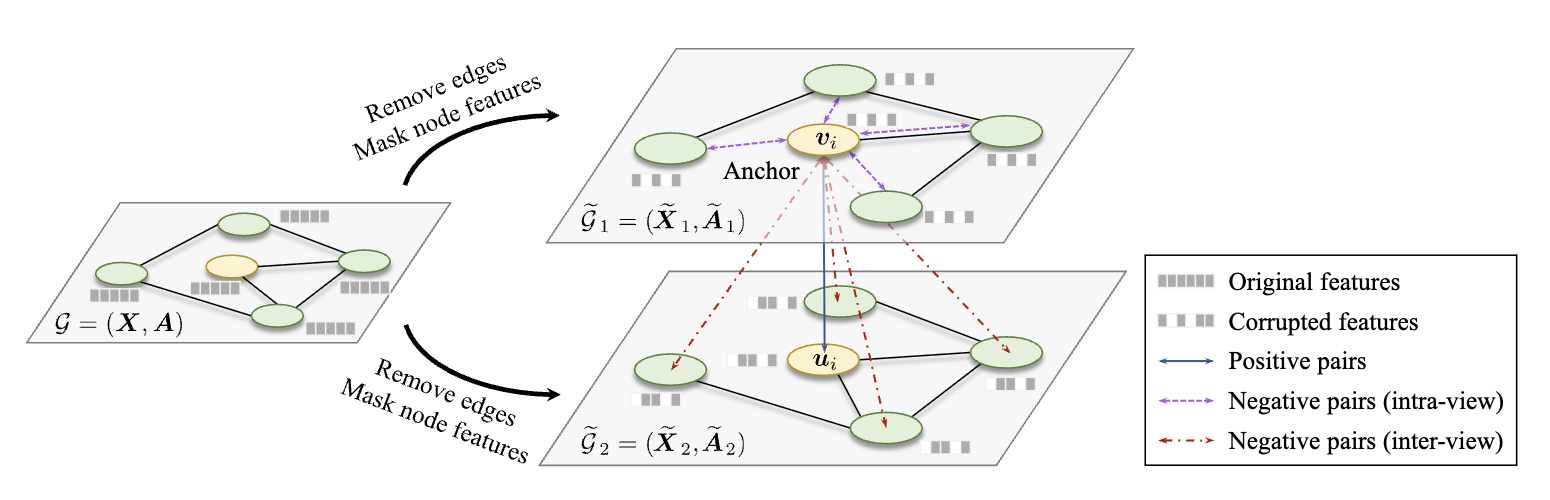
2.2. Contrastive Learning of Node Representations
2.2.1. THE CONTRASTIVE LEARNING FRAMEWORK
- GRACE: local-global 관계를 활용하는 기존 연구와 달리, 노드 수준 (node-level) 에서 임베딩 간의 일치도를 직접적으로 최대화하는 방식으로 표현 학습을 수행합니다. 주요 내용을 자세히 정리하면 다음과 같습니다.
- Graph Views 생성
각 iteration마다 원본 그래프 G에서 두 개의 graph view (G̃1, G̃2)를 생성합니다.
GNN encoder (f) 를 사용하여 각각 서로 다른 view의 노드 임베딩 U와 V를 얻습니다. - Contrastive Objective
Contrastive objective (discriminator)를 사용하여 동일한 노드의 임베딩을 서로 다른 view에서 구별합니다.
노드 v_i에 대해, 한 view에서 생성된 임베딩 u_i는 anchor가 되고, 다른 view에서 생성된 임베딩 v_i는 positive sample이 됩니다. 나머지 노드의 임베딩은 negative sample로 간주됩니다. - Critic 함수: 여기서 s 는 cosine similarity이고, g 는 비선형 projection입니다. Projection g 는 표현력을 향상시키기 위해 2-layer MLP로 구현됩니다.
- Pairwise Objective 함수: Positive pair 에 대한 pairwise objective 는 다음과 같이 정의됩니다.
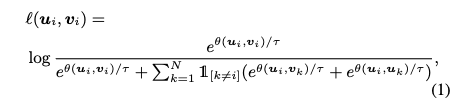
- Negative sample을 명시적으로 sampling하지 않고, positive pair가 주어지면 다른 모든 노드를 negative sample로 정의합니다. Negative sample은 inter-view와 intra-view 노드에서 비롯됩니다.
- 전체 Objective 함수: 전체 objective 함수 J는 모든 positive pair에 대한 평균으로 정의되며, maximize하는 것이 목표입니다.
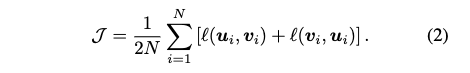
- 정리: 이러한 단계를 통해 GRACE는 그래프의 노드 표현을 학습하고, downstream task에서 좋은 성능을 보이도록 합니다.
이 프레임워크는 그래프 데이터에 적용하여 노드 임베딩을 학습하는 데 효과적입니다.
2.2.2. GRAPH VIEW GENERATION
- 그래프 뷰 생성의 중요성
Contrastive learning 방법에서 그래프의 다양한 뷰는 각 노드에 대해 서로 다른 context를 제공합니다.
따라서, 모델이 다양한 context에서 노드 임베딩을 비교함으로써 더 robust한 표현을 학습할 수 있도록 돕습니다. - 에지 제거 (Removing Edges, RE): 그래프의 구조적 정보를 변경하여 새로운 뷰를 생성합니다.
-> 원래 그래프에 존재하는 에지 중 일부를 무작위로 제거합니다. - 노드 피처 마스킹 (Masking Node Features, MF): 노드의 attribute 정보를 변경하여 새로운 뷰를 생성합니다.
-> 노드 피처의 특정 차원(dimension)을 무작위로 0으로 마스킹합니다.
3. Experiments
3.1. Datasets
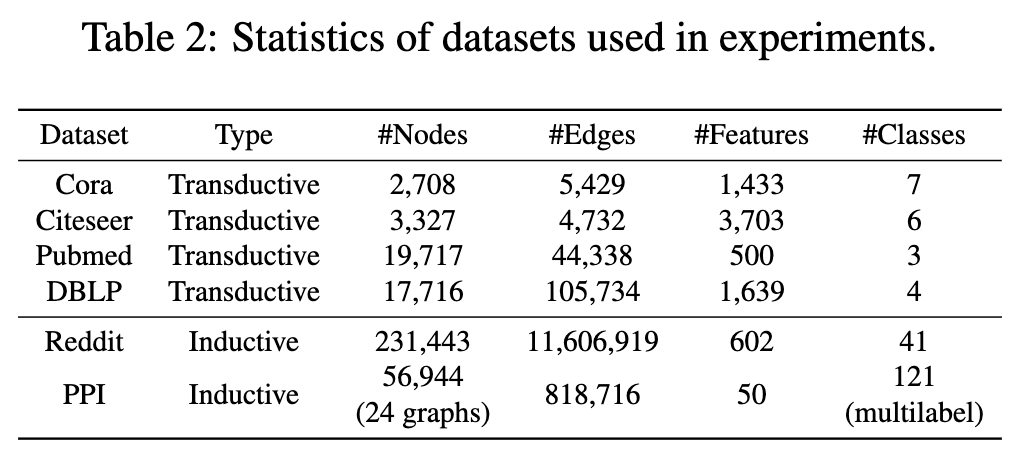
- Citation Networks: Cora, Citeseer, Pubmed, DBLP 데이터셋을 사용하며, transductive node classification 에 활용됩니다.
- Social Networks: Reddit posts 데이터셋을 사용하여 대규모 그래프에 대한 Inductive learning 을 수행합니다.
- Biological PPI Networks: PPI 네트워크를 사용하여 다중 그래프에 대한 Inductive node classification 를 진행합니다.
- 평가태스크
- Transductive learning (Transductive node classification)
- Inductive learning (Inductive node classification)
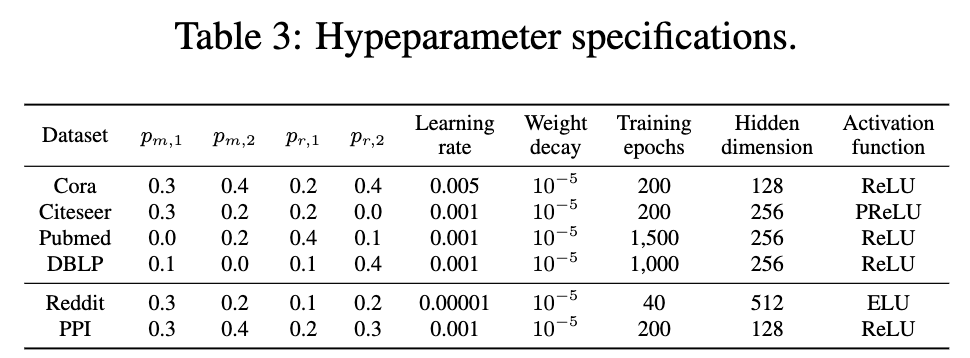
3.2. Experimental Setup
- 선형 평가 방식 (Linear Evaluation Scheme): 이 논문에서는 Deep Graph Infomax 논문에서 사용된 선형 평가 방식을 따르고 있습니다. 모델을 비지도 학습 방식으로 먼저 훈련시킨 후, 얻어진 임베딩을 사용하여 간단한 L2 정규화 로지스틱 회귀 분류기를 훈련하고 테스트합니다.
- 모델 훈련은 20번 반복하여 각 데이터셋에 대한 평균 성능을 보고합니다.
- 평가지표: Inductive Task에서는 micro-averaged F1-score를, Transductive Task에서는 정확도를 성능 측정 지표로 사용합니다.
- Inductive Learning Task 에서는 학습에 사용되지 않은 노드와 그래프를 대상으로 테스트를 진행합니다.
- Transductive Learning Task 에서는 모든 데이터의 특징을 사용하지만, 테스트 세트의 레이블은 가려진 상태로 진행됩니다.
Transductive learning.
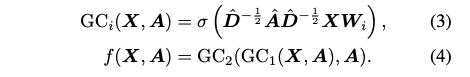
W: A trainable weight matrix.
Inductive learning on large graphs.
- Reddit 데이터셋의 큰 규모를 고려하여 GraphSAGE-GCN 인코더를 사용하여 inductive learning을 수행해야 합니다.
- GraphSAGE-GCN 인코더
- Reddit 데이터의 규모가 매우 크기 때문에 Deep Graph Infomax에서 사용된 설정을 따릅니다. 3개의 레이어로 구성된 GraphSAGE-GCN (Inductive Representation Learning on Large Graphs) 를 인코더로 사용하며, residual connection 을 추가했습니다.
- Mean-pooling propagation rule: 노드 feature들을 평균화합니다.
- Subsampling: Reddit 데이터셋이 너무 커서 GPU 메모리에 전부 올릴 수 없기 때문에, Inductive Representation Learning on Large Graphs에서 제안된 subsampling 방법을 사용합니다. 먼저 노드의 minibatch를 랜덤하게 선택합니다.
그 다음 선택된 각 노드를 중심으로 subgraph를 구성하기 위해 이웃 노드들을 sampling합니다. - 이러한 방식으로 large graph에 대한 inductive learning을 효율적으로 수행할 수 있습니다.
Inductive learning on multiple graphs.
- Inductive Learning setup on PPI dataset
- Reddit 데이터셋과 유사하게, PPI 데이터셋에 대해 inductive learning을 수행합니다. Inductive learning은 학습에 사용되지 않은 새로운 데이터(노드 또는 그래프)에 대해 모델이 일반화될 수 있도록 하는 설정입니다.
- GraphSAGE-GCN 모델을 사용하며, mean-pooling propagation rule을 적용합니다. GraphSAGE는 이웃 노드의 정보를 집계하여 노드 표현을 학습하는 GNN의 한 종류이며, mean-pooling은 이웃 노드의 feature를 평균내는 방식으로 집계하는 방법을 의미합니다.
- PPI 데이터셋의 특징: PPI (protein-protein interaction) 데이터셋은 여러 개의 그래프로 구성되어 있습니다. 각 그래프는 인간 조직에 해당하며, 노드는 단백질, 엣지는 단백질 간의 상호작용을 나타냅니다.
3.3. Results and Analysis
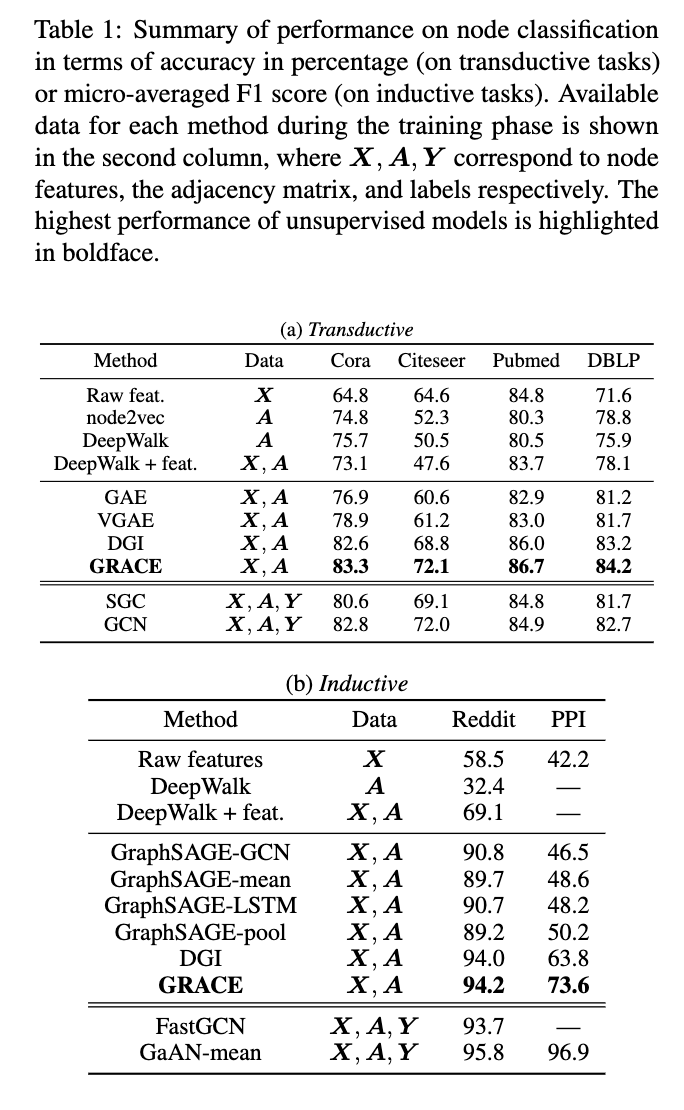
- 기존 unsupervised method 대비 우위: Transductive 및 inductive task 모두에서 GRACE가 기존 unsupervised 모델보다 훨씬 뛰어난 성능을 보였습니다. 이는 GRACE의 contrastive learning framework의 우수성을 입증합니다.
- Label supervision 모델과의 경쟁력: GRACE는 4개의 transductive 데이터셋과 inductive 데이터셋 Reddit에서 label supervision을 통해 학습된 모델과 견줄 만한 성능을 보였습니다.
- DGI 대비 성능 향상
- GRACE는 PPI 데이터셋에서 또 다른 경쟁력 있는 contrastive learning 방법인 DGI보다 10% 이상 높은 절대적 성능 향상을 달성했습니다.
- PPI 데이터셋의 node feature가 매우 희소(40% 이상의 노드가 all-zero feature를 가짐)하기 때문이며, negative sample을 선택할 때 topology 정보 고려의 중요성을 강조합니다.
- DGI는 feature shuffling을 통해 corrupted graph를 생성하지만, PPI와 같이 feature가 sparse한 경우 contrastive objective 학습에 어려움을 겪습니다.
- 반면 GRACE에서 사용된 RE(Removing Edges) scheme은 node feature에 의존하지 않아 이러한 상황에서 효과적인 해결책이 됩니다.
- Supervised 모델과의 격차: Supervised 모델은 label을 통해 추가적인 정보를 얻기 때문에 GRACE와의 성능 격차가 여전히 존재합니다.
- GRACE 모델은 다양한 데이터셋에서 기존 unsupervised 모델을 능가하는 강력한 성능을 보였으며, 특히 node feature가 sparse한 경우 DGI보다 우수한 성능을 나타냈습니다. 하지만 supervised 모델과의 성능 격차는 여전히 존재하며, 이는 label 정보 활용의 중요성을 시사합니다.
- 전통적인 방법론들과의 비교
- DeepWalk의 한계: DeepWalk와 같은 전통적인 대조 학습 방법은 일부 데이터셋(Citeseer, Pubmed, Reddit)에서 raw feature만 사용하는 naive classifier보다 성능이 떨어집니다. 이는 DeepWalk가 node feature를 효과적으로 활용하지 못함을 시사합니다.
- GCN 기반 방법
- GraphSAGE, GAE와 같은 GCN 기반 방법들은 node feature를 embedding 학습에 통합할 수 있습니다.
- GCN 기반 방법의 문제점: Pubmed 데이터셋에서 GCN 기반 방법들의 성능이 DeepWalk + feature보다 여전히 낮습니다. 이는 GCN 기반 방법들이 negative sample을 선택할 때 edge에만 의존하는 단순한 방식을 사용하기 때문으로 추정됩니다.
- Negative sample 선택의 중요성: 이는 대조 표현 학습에서 negative sample 선택이 얼마나 중요한지를 보여줍니다.
- GRACE 프레임워크의 효과: GRACE가 GAE보다 우수한 성능을 보이는 것은 GRACE 프레임워크가 graph view 간 node를 대조하는 효과적인 방법임을 입증합니다.
Conclusion
- 접근 방식: 제안하는 모델은 그래프의 노드 수준에서 표현 학습을 수행하기 위해 노드 간의 일치도를 최대화하는 대조 학습 프레임워크를 사용합니다.
- 모델 학습 과정
- 그래프 뷰 생성: 엣지 제거(removing edges)와 노드 특징 마스킹(masking node features)이라는 두 가지 방식을 사용하여 그래프 뷰를 생성합니다.
- 대조 손실 적용: 생성된 뷰에서 노드 임베딩의 일치도를 높이는 방향으로 대조 손실(contrastive loss)을 적용하여 모델을 학습합니다.
- 실험 및 결과: Transductive 및 Inductive 환경에서 다양한 실제 데이터 세트를 사용하여 포괄적인 실험을 수행했습니다.
제안하는 방법이 기존의 최첨단 방법들을 능가하며, 특히 Transductive 작업에서 지도 학습 모델을 능가하는 결과를 보였습니다.
Reference
[1] Deep Graph Infomax (ICLR 2019)