[Paper Review] “Low-Resource” Text Classification : A Parameter-Free Classification Method with Compressors (ACL 2023)
* 본 논문 리뷰는 빠른 정리를 위해 매우 간략하게 리뷰함을 양해 바랍니다.
“Low-Resource” Text Classification : A Parameter-Free ClassificationMethod with Compressors (ACL 2023)
- Abstract
1. DNN 의 텍스트 분류에서의 어려움
- 대부분의 딥러닝 모델은 데이터에 대한 의존성
- DNN : 계산적으로 매우 비용이 많이 듭니다.
- 많은 파라미터와 상당한 양의 레이블이 달린 데이터가 필요합니다.
- DNNs의 계산적 요구는 계산 자원 및 데이터 라벨링 면에서 비용이 크게 드는 결과를 초래합니다.
2. 제안된 대안적인 방법
- 텍스트 분류를 위한 DNNs의 대안으로 Non-Parametric Method 을 제안
- 제안된 방법 : gzip과 같은 간단한 압축기와 k-최근접이웃(K-NN) 분류기를 결합한 것
3. 제안된 방법의 주요 특징
- 사용 편의성: 이 방법은 사용하기 쉽다
- 모델의 가벼움: 계산 요구사항 면에서 가볍습니다.
- 텍스트 분류에서의 범용성을 갖추고 있어 다양한 작업에 적용될 수 있다는 뜻
4. 방법론과 결과
- 학습 파라미터 x
- 훈련된 딥 러닝 방법들과 경쟁력 있는 결과
5. 적은 양의 데이터에서의 성능
- 적은 양의 레이블 데이터가 있어 DNNs를 효과적으로 훈련시키기 어려운 경우에도 괜찮은 성과
- 텍스트 분류를 위한 DNNs에 대한 대안으로 간단한 압축 도구와 k-NN 분류기를 결합한 비-파라미터적인 접근 방식
- Introduction
1. Complexity of Deep Neural Networks
- 복잡한 심층 신경망은 잠재적 상관관계를 포착하고 내재적 패턴을 인식하는 능력이 있지만, 간단한 작업(예: 주제 분류)에 대해서는 지나치게 복잡할 수 있습니다.
- 가벼운 대안들이 종종 충분한 결과를 제공할 수 있음
2. Proposed Method
- 손실 없는 압축기, 압축기 기반 거리 측정 및 k-최근접 이웃 분류기(kNN)를 결합한 텍스트 분류 방법
- 압축기를 사용하여 압축기 기반 거리 측정으로 유사도 점수로 변환한 후, 이 거리를 사용하여 kNN을 통해 분류를 수행
3. Contributions
- Method : NCD(Normalized Compression Distance) 및 kNN classifier을 사용
- DNN 와 유사한 결과를 얻을 수 있음
- 제안된 방법이 적은 레이블 데이터가 있는 상황에서도 좋은 성능
- Method
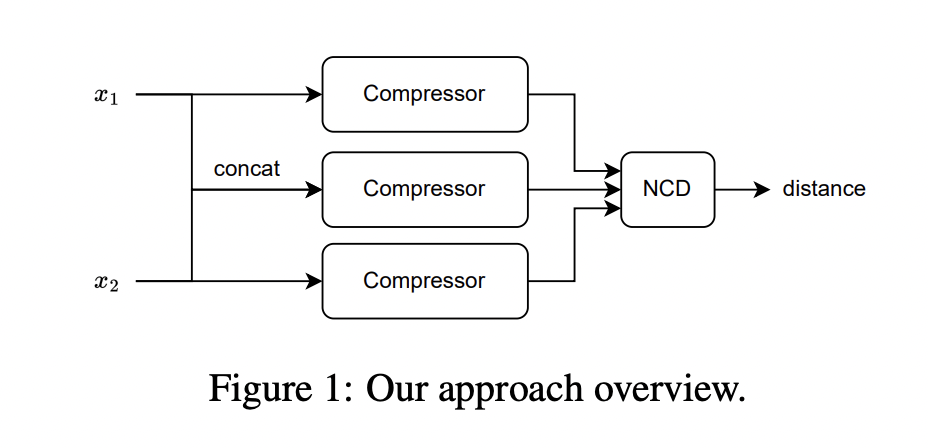
- 텍스트간의 유사도 측정 : Kolmogorov complexity (Kolmogorov, 1963) 의 계산 복잡성으로 인해 이것의 근사값으로 NCD 를 이용
- NCD (Nomalized Compression Distance)
- 압축기(gzip) 를 기반으로 만든 두개의 텍스트간의 유사도를 측정하는 metric
- C(x) : gzip 압축기를 이용해 압축한 텍스트
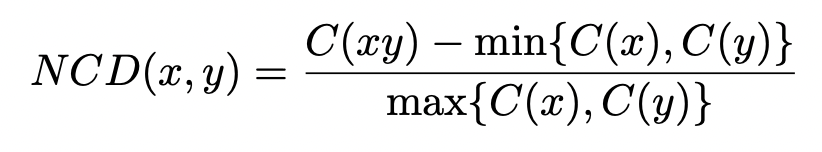
- NCD 값들을 distance metric 으로 활용하여 이를 KNN classifier 로 텍스트들을 분류함.
- Comment
- 초경량화 모델 : [pre-training , training , fine-tuning , 데이터 전처리] 필요 x , 모델의 파라미터 수 = 0 (GPU 필요 x)
- 압축기 (gzip) -> 데이터에 형식에 무관한 장점이 있으므로 활용가치가 크다.
- deep neural network 기반보다 훨씬 가벼운 모델로 좋은 성능을 내어 신선하다.
- 다른 task 에서 해결할 수 있는 DNN 의 대안적인 경량화 모델 ?